28 内存回收下篇:三色标记-清除算法是怎么回事?
今天我们继续讨论内存回收问题。在上一讲,我们发现双色标记-清除算法有一个明显的问题,如下图所示:

你可以把 GC 的过程看作标记、清除及程序不断对内存进行修改的过程,分成 3 种任务:
- 标记程序(Mark)
- 清除程序(Sweep)
- 变更程序(Mutation)
标记(Mark)就是找到不用的内存,清除(Sweep)就是回收不用的资源,而修改(Muation)则是指用户程序对内存进行了修改。通常情况下,在 GC 的设计中,上述 3 种程序不允许并行执行(Simultaneously)。对于 Mark、Sweep、Mutation 来说内存是共享的。如果并行执行相当于需要同时处理大量竞争条件的手段,这会增加非常多的开销。当然你可以开多个线程去 Mark、Mutation 或者 Sweep,但前提是每个过程都是独立的。

因为 Mark 和 Sweep 的过程都是 GC 管理,而 Mutation 是在执行应用程序,在实时性要求高的情况下可以允许一边 Mark,一边 Sweep 的情况; 优秀的算法设计也可能会支持一边 Mark、一边 Mutation 的情况。这种算法通常使用了 Read On Write 技术,本质就是先把内存拷贝一份去 Mark/Sweep,让 Mutation 完全和 Mark 隔离。
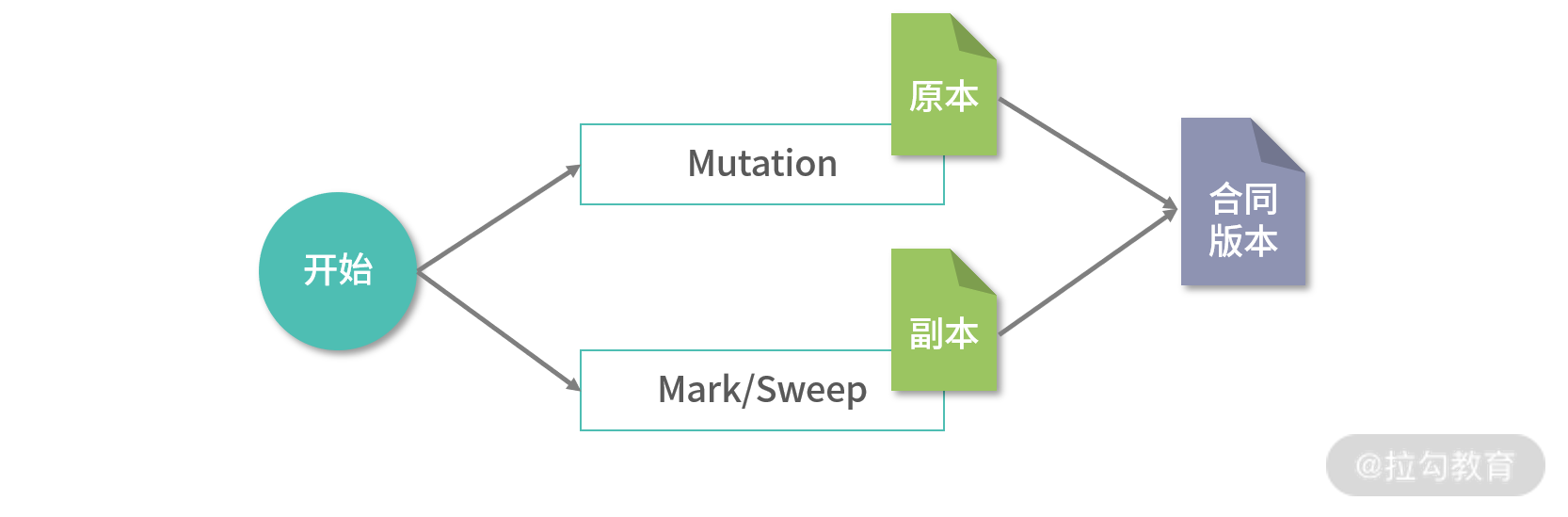
上图中 GC 开始后,拷贝了一份内存的原本,进行 Mark 和 Sweep,整理好内存之后,再将原本中所有的 Mutation 合并进新的内存。 这种算法设计起来会非常复杂,但是可以保证实时性 GC。
上图的这种 GC 设计比较少见,通常 GC 都会发生 STL(Stop The World)问题,Mark/Sweep/Mutation 只能够交替执行。也就是说, 一种程序执行的时候,另一种程序必须停止。
对于双色标记-清除算法,如果 Mark 和 Sweep 之间存在 Mutation,那么 Mutation 的伤害是比较大的。比如 Mutation 新增了一个白色的对象,这个白色的对象就可能会在 Sweep 启动后被清除。当然也可以考虑新增黑色的对象,这样对象就不会在 Sweep 启动时被回收。但是会发生下面这个问题,如下图所示:
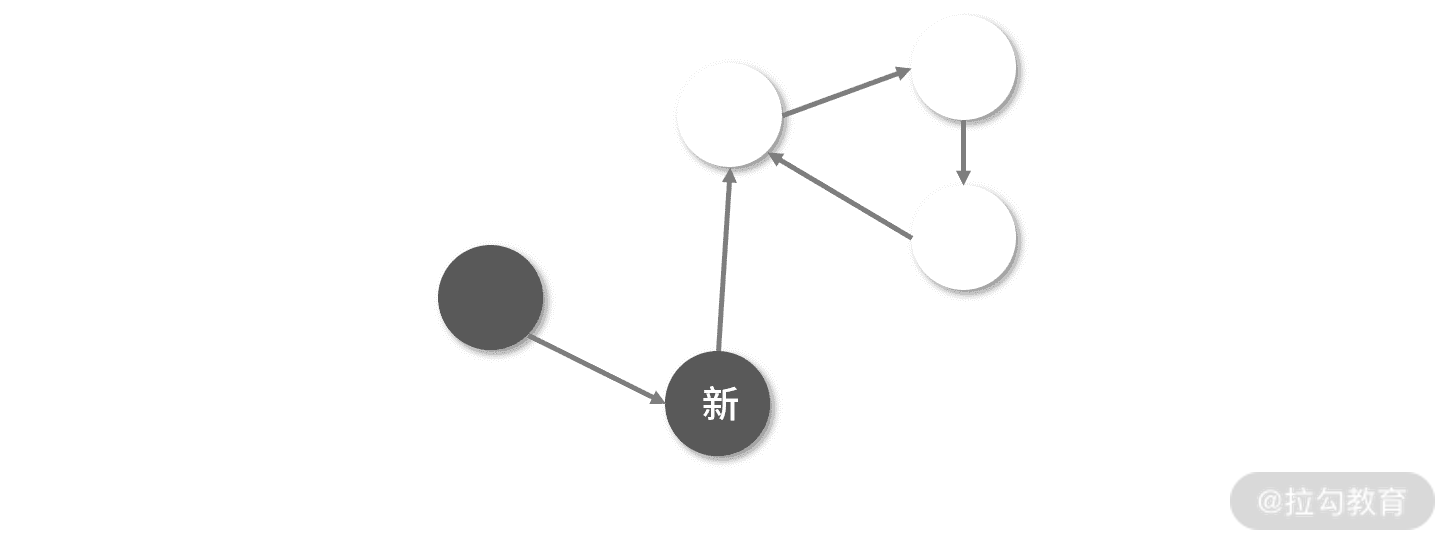
如果一个新对象指向了一个已经删除的对象,一个新的黑色对象指向了一个白色对象,这个时候 GC 不会再遍历黑色对象,也就是白色的对象还是会被清除。因此,我们希望创建一个在并发环境更加稳定的程序,让 Mark/Mutation/Sweep 可以交替执行,不用特别在意它们之间的关联。
有一个非常优雅地实现就是再增加一种中间的灰色,把灰色看作可以增量处理的工作,来重新定义白色的含义。
三色标记-清除算法(Tri-Color Mark Sweep)
接下来,我会和你讨论这种有三个颜色标记的算法,通常称作三色标记-清除算法。首先,我们重新定义黑、白、灰三种颜色的含义:
- 白色代表需要 GC 的对象;
- 黑色代表确定不需要 GC 的对象;
- 灰色代表可能不需要 GC 的对象,但是还未完成标记的任务,也可以认为是增量任务。
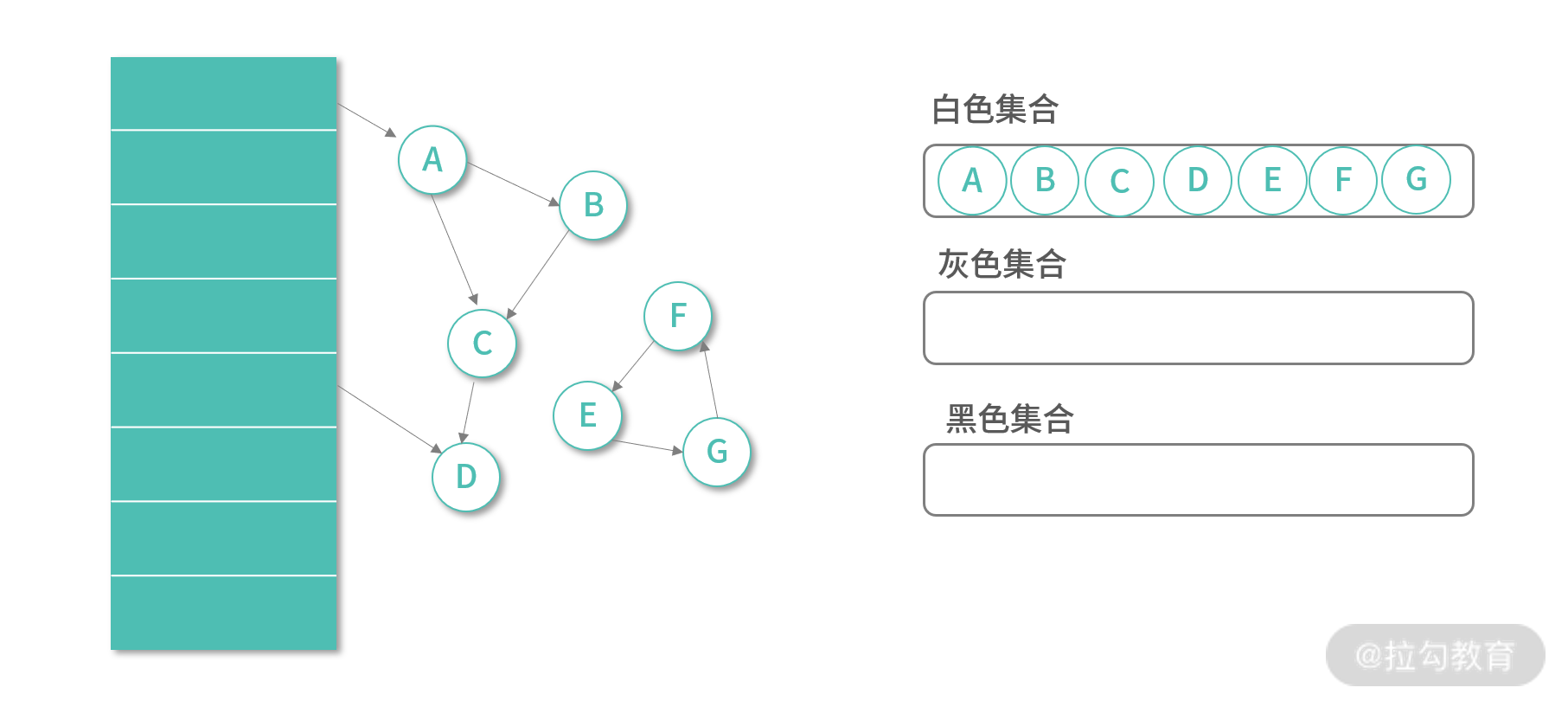
在三色标记-清除算法中,一开始所有对象都染成白色。初始化完成后,会启动标记程序。在标记的过程中,是可以暂停标记程序执行 Mutation。
算法需要维护 3 个集合,白色集合、黑色集合、灰色集合。3 个集合是互斥的,对象只能在一个集合中。执行之初,所有对象都放入白色集合,如下图所示:
第一次执行,算法将 Root 集合能直接引用的对象加入灰色集合,如下图所示:
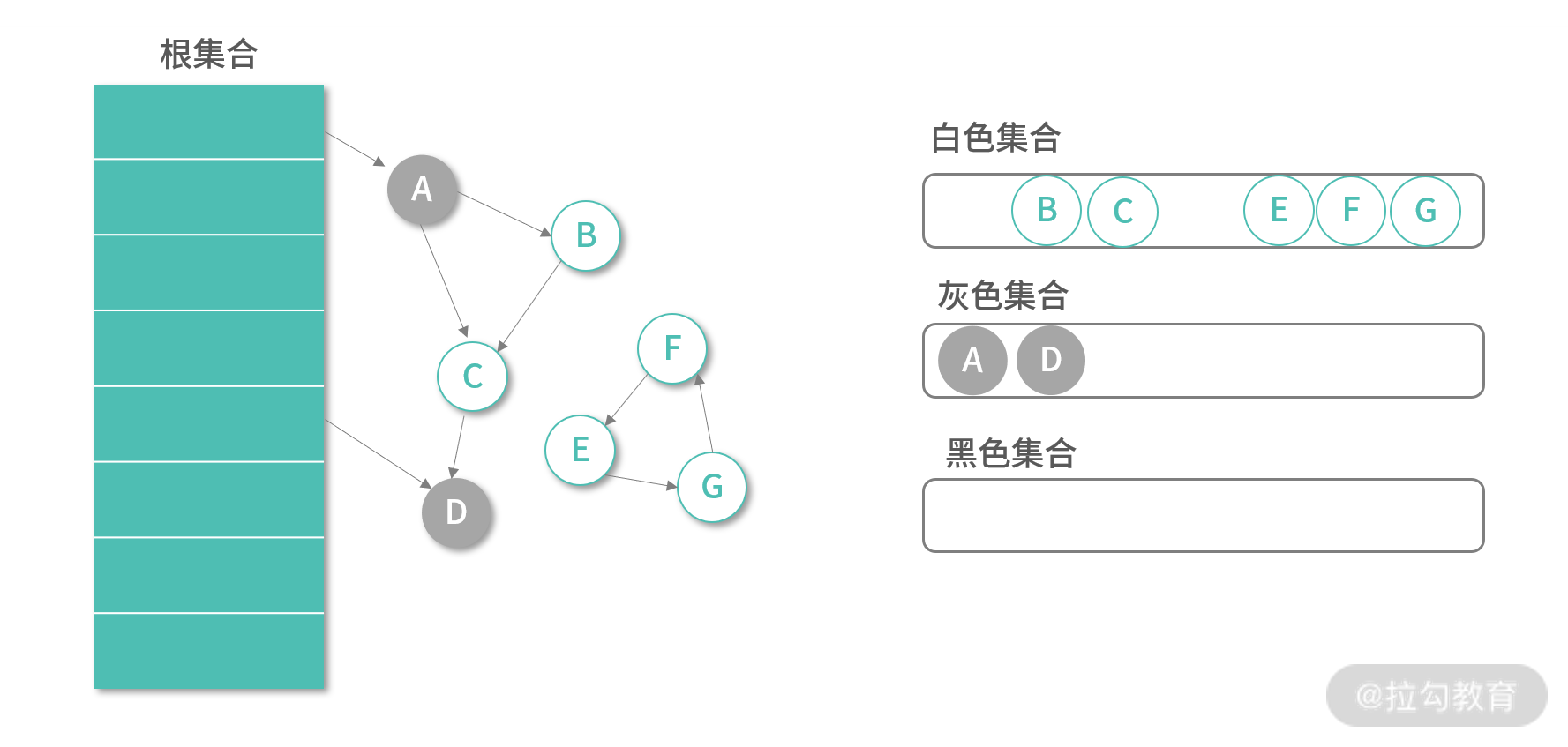
接下来算法会不断从灰色集合中取出元素进行标记,主体标记程序如下:
1 | while greySet.size() > 0 { |
标记的过程主要分为 3 个步骤:
- 如果对象在白色集合中,那么先将对象放入灰色集合;
- 然后遍历节点的所有的引用对象,并递归所有引用对象;
- 当一个对象的所有引用对象都在灰色集合中,就把这个节点放入为黑色集合。
伪代码如下:
1 | func mark(obj) { |
你可以观察下上面的程序,这是一个 DFS 的过程。如果多个线程对不同的 Root Object 并发执行这个算法,我们需要保证 3 个集合都是线程安全的,可以考虑利用 ConcurrentSet(这样性能更好),或者对临界区上锁。并发执行这个算法的时候,如果发现一个灰色节点说明其他线程正在处理这个节点,就忽略这个节点。这样,就解决了标记程序可以并发执行的问题。
当标记算法执行完成的时候,所有不需要 GC 的元素都会涂黑:
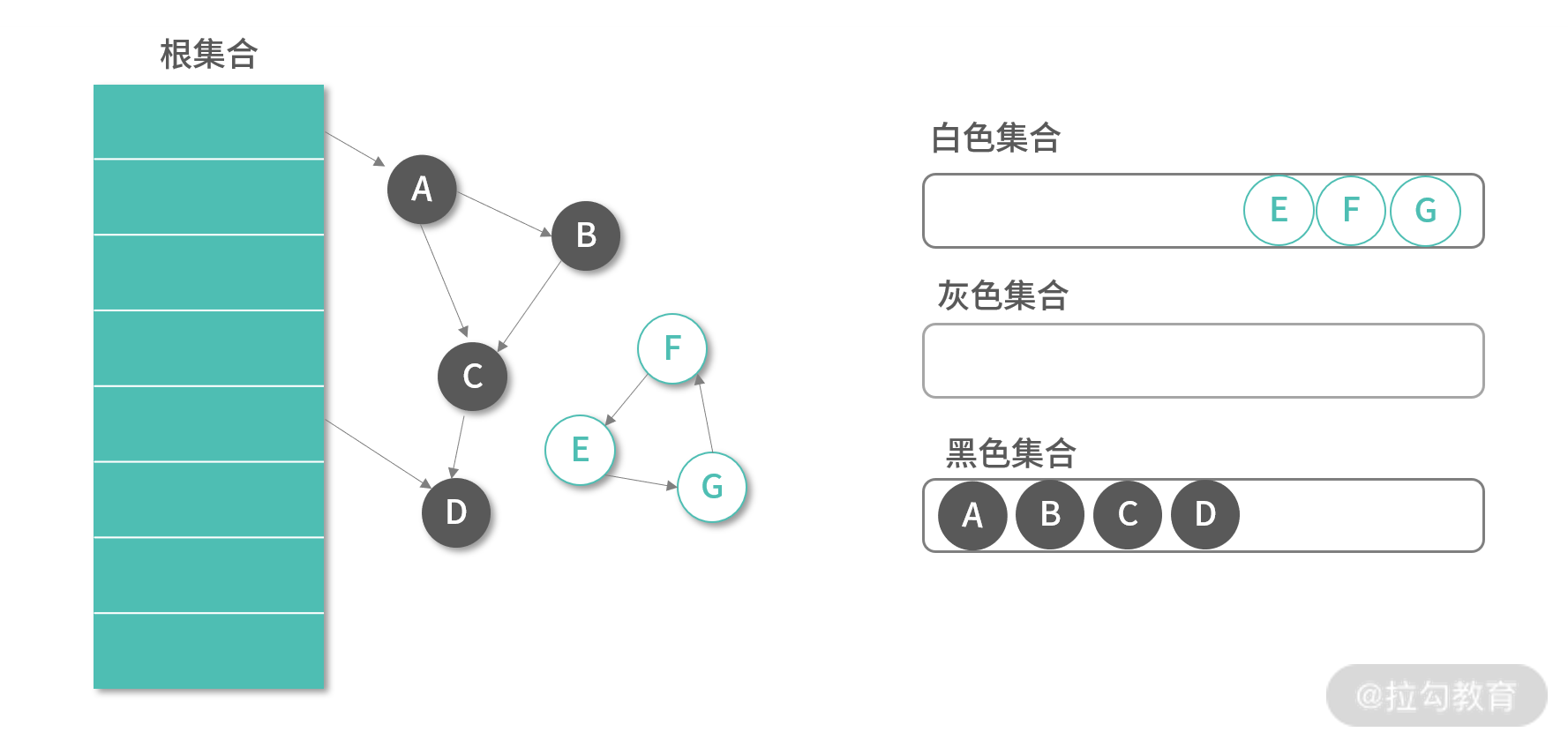 标记算法完成后,白色集合内就是需要回收的对象。
标记算法完成后,白色集合内就是需要回收的对象。
以上,是类似双色标记-清除算法的全量 GC 程序,我们从 Root 集合开始遍历,完成了对所有元素的标记(将它们放入对应的集合)。
接下来我们来考虑增加 GC(Incremental GC)的实现。首先对用户的修改进行分类,有这样 3 类修改(Mutation)需要考虑:
- 创建新对象
- 删除已有对象
- 调整已有引用
如果用户程序创建了新对象,可以考虑把新对象直接标记为灰色。虽然,也可以考虑标记为黑色,但是标记为灰色可以让 GC 意识到新增了未完成的任务。比如用户创建了新对象之后,新对象引用了之前删除的对象,就需要重新标记创建的部分。
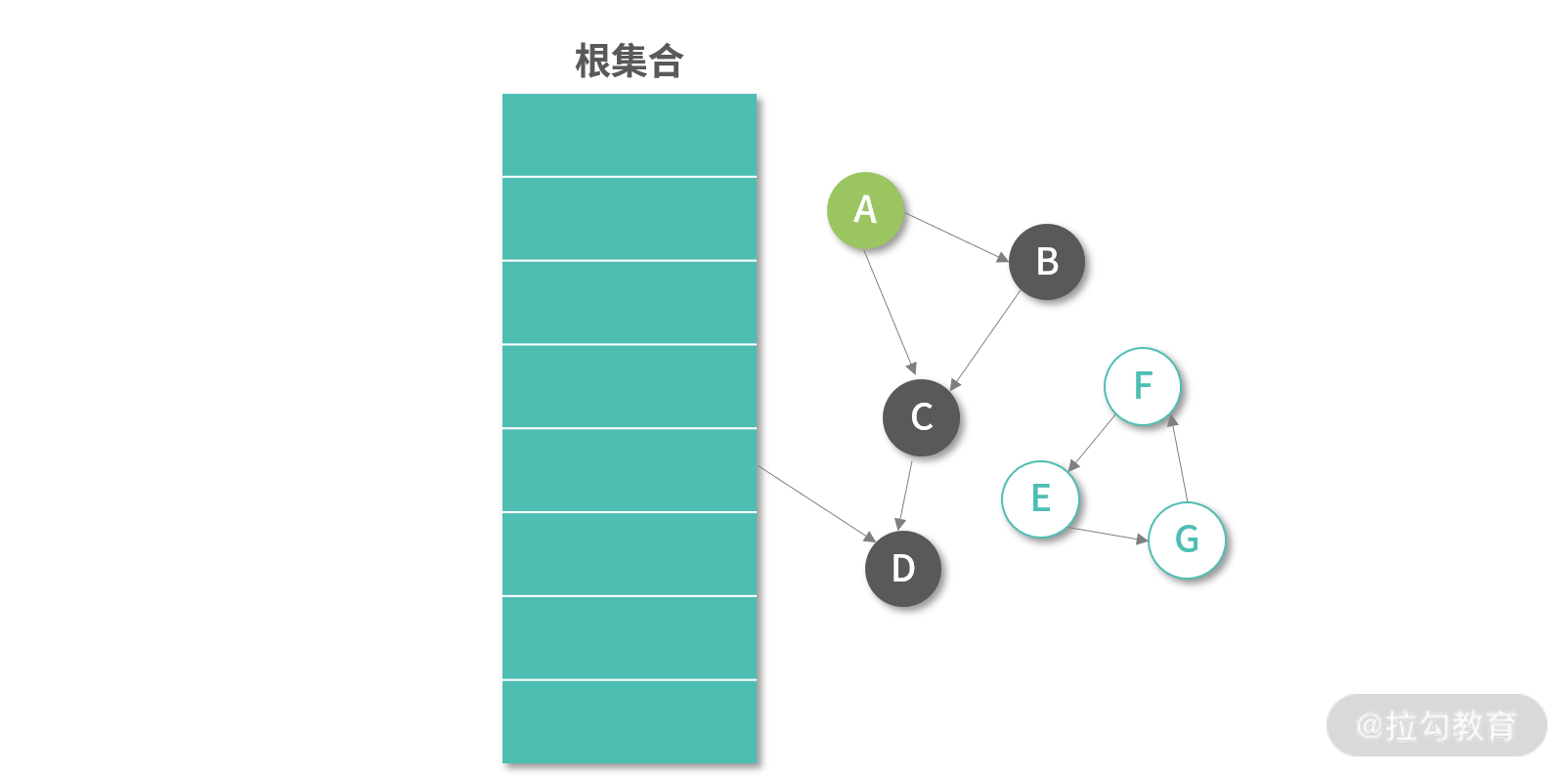
如果用户删除了已有的对象,通常做法是等待下一次全量 Mark 算法处理。下图中我们删除了 Root Object 到 A 的引用,这个时候如果把 A 标记成白色,那么还需要判断是否还有其他路径引用到 A,而且 B,C 节点的颜色也需要重新计算。关键的问题是,虽然可以实现一个基于 A 的 DFS 去解决这个问题,但实际情况是我们并不着急解决这个问题,因为内存空间往往是有富余的。
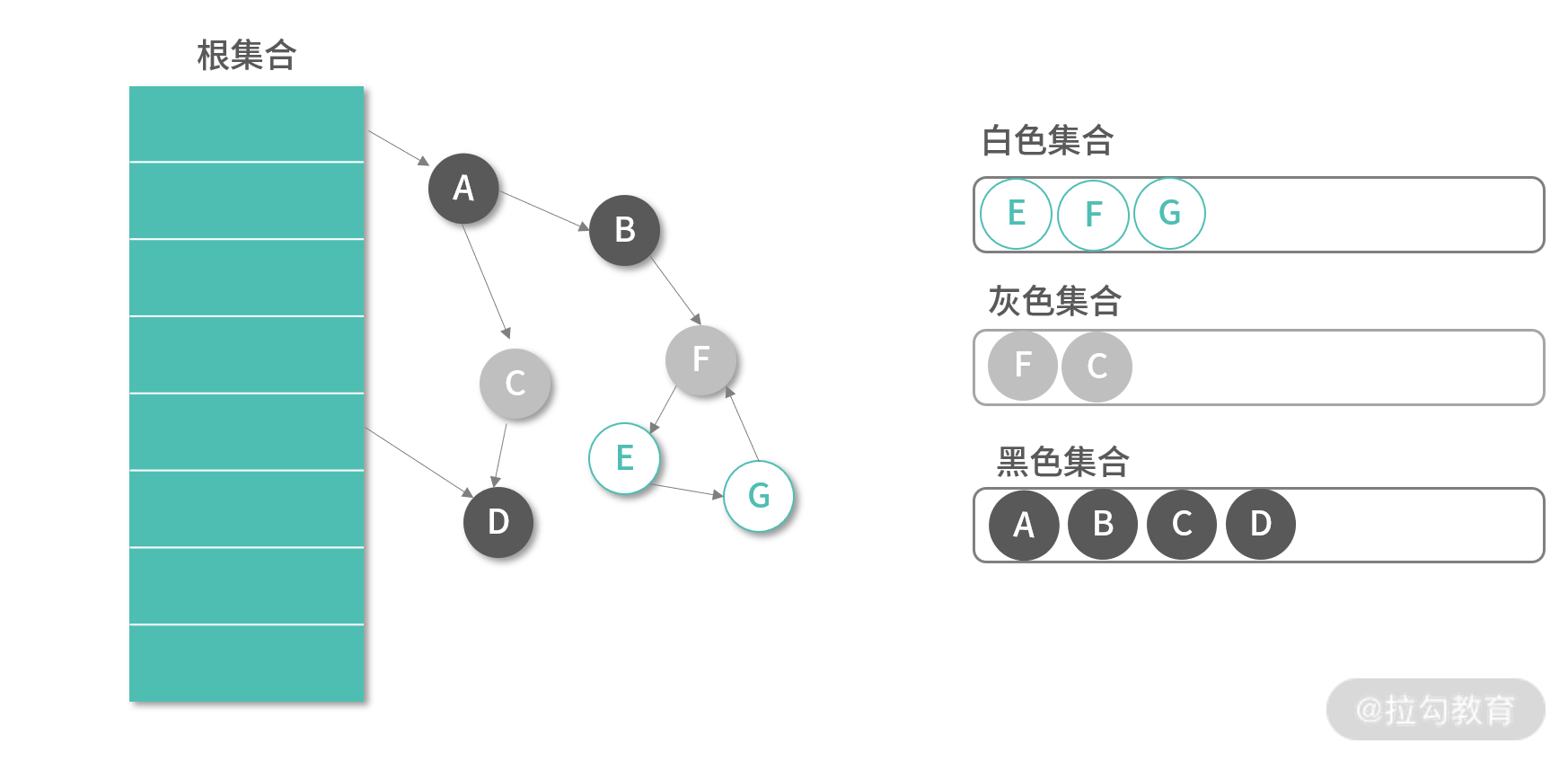
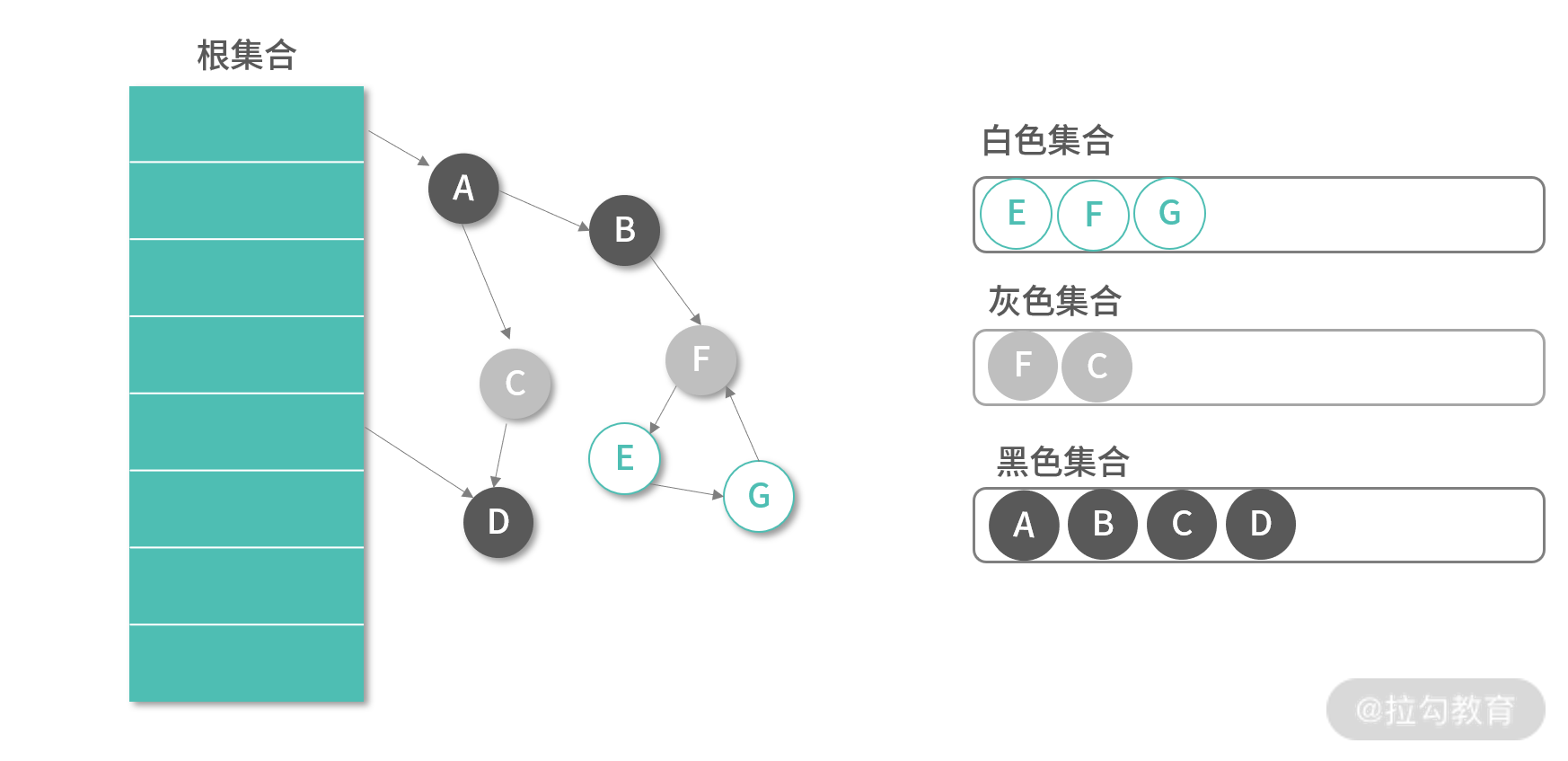
在调整已有的引用关系时,三色标记算法的表现明显更好。下图是对象 B 将对 C 的引用改成了对 F 的引用,C,F 被加入灰色集合。接下来 GC 会递归遍历 C,F,最终然后 F,E,G 都会进入灰色集合。
内存回收就好比有人在随手扔垃圾,清洁工需要不停打扫。如果清洁工能够跟上人们扔垃圾的速度,那么就不需要太多的 STL(Stop The World)。如果清洁工跟不上扔垃圾的速度,最终环境就会被全部弄乱,这个时候清洁工就会要求“Stop The World”。三色算法的优势就在于它支持多一些情况的 Mutation,这样能够提高“垃圾”被并发回收的概率。
目前的 GC 主要都是基于三色标记算法。 至于清除算法,有原地回收算法,也有把存活下来的对象(黑色对象)全部拷贝到一个新的区域的算法。
碎片整理和生代技术
三色标记-清除算法,还没有解决内存回收产生碎片的问题。通常,我们会在三色标记-清除算法之上,再构建一个整理内存(Compact)的算法。如下图所示:
 Compact 算法将对象重新挤压到一起,让更多空间可以被使用。我们在设计这个算法时,观察到了一个现象:新创建出来的对象,死亡(被回收)概率会更高,而那些已经存在了一段时间的对象,往往更不容易死亡。这有点类似 LRU 缓存,其实是一个概率问题。接下来我们考虑针对这个现象进行优化。
Compact 算法将对象重新挤压到一起,让更多空间可以被使用。我们在设计这个算法时,观察到了一个现象:新创建出来的对象,死亡(被回收)概率会更高,而那些已经存在了一段时间的对象,往往更不容易死亡。这有点类似 LRU 缓存,其实是一个概率问题。接下来我们考虑针对这个现象进行优化。
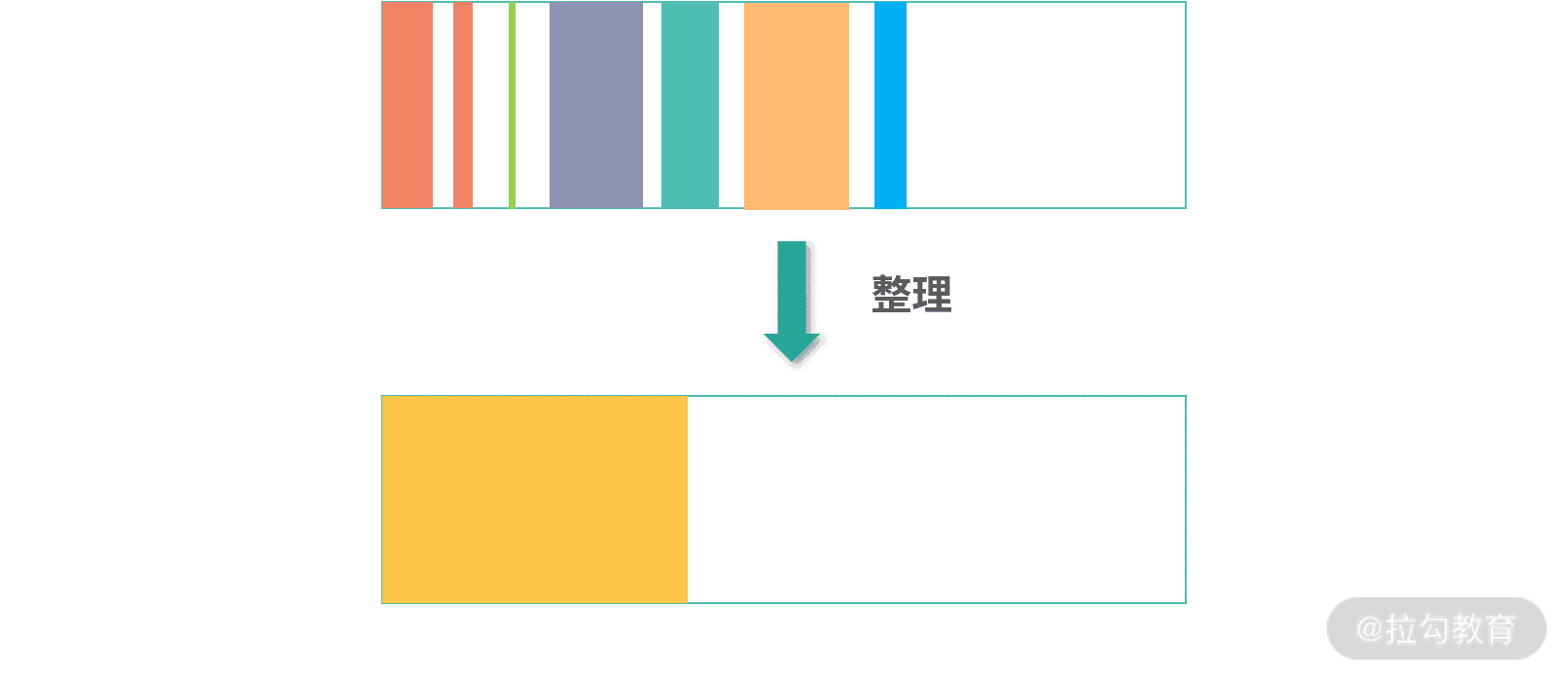
如上图所示,你可以把新创建的对象,都先放到一个统一的区域,在 Java 中称为伊甸园(Eden)。这个区域因为频繁有新对象死亡,因此需要经常 GC。考虑整理使用中的对象成本较高,因此可以考虑将存活下来的对象拷贝到另一个区域,Java 中称为存活区(Survior)。存活区生存下来的对象再进入下一个区域,Java 中称为老生代。
上图展示的三个区域,Eden、Survior 及老生代之间的关系是对象的死亡概率逐级递减,对象的存活周期逐级增加。三个区域都采用三色标记-清除算法。每次 Eden 存活下来的对象拷贝到 Survivor 区域之后,Eden 就可以完整的回收重利用。Eden 可以考虑和 Survivor 用 1:1 的空间,老生代则可以用更大的空间。Eden 中全量 GC 可以频繁执行,也可以增量 GC 混合全量 GC 执行。老生代中的 GC 频率可以更低,偶尔执行一次全量的 GC。
GC 的选择
最后我们来聊聊 GC 的选择。通常选择 GC 会有实时性要求(最大容忍的暂停时间),需要从是否为高并发场景、内存实际需求等维度去思考。在选择 GC 的时候,复杂的算法并不一定更有效。下面是一些简单有效的思考和判断。

- 如果你的程序内存需求较小,GC 压力小,这个时候每次用双色标记-清除算法,等彻底标记-清除完再执行应用程序,用户也不会感觉到多少延迟。双色标记-清除算法在这种场景可能会更加节省时间,因为程序简单。
- 对于一些对暂停时间不敏感的应用,比如说数据分析类应用,那么选择一个并发执行的双色标记-清除算法的 GC 引擎,是一个非常不错的选择。因为这种应用 GC 暂停长一点时间都没有关系,关键是要最短时间内把整个 GC 执行完成。
- 如果内存的需求大,同时对暂停时间也有要求,就需要三色标记清除算法,让部分增量工作可以并发执行。
- 如果在高并发场景,内存被频繁迭代,这个时候就需要生代算法。将内存划分出不同的空间,用作不同的用途。
- 如果实时性要求非常高,就需要选择专门针对实时场景的 GC 引擎,比如 Java 的 Z。
当然,并不是所有的语言都提供多款 GC 选择。但是通常每个语言都会提供很多的 GC 参数。这里也有一些最基本的思路,下面我为你介绍一下。
如果内存不够用,有两种解决方案。一种是降低吞吐量——相当于 GC 执行时间上升;另一种是增加暂停时间,暂停时间较长,GC 更容易集中资源回收内存。那么通常语言的 GC 都会提供设置吞吐量和暂停时间的 API。
如果内存够用,有的 GC 引擎甚至会选择当内存达到某个阈值之后,再启动 GC 程序。通常阈值也是可以调整的。因此如果内存够用,就建议让应用使用更多的内存,提升整体的效率。
总结
那么通过这节课的学习,你现在可以尝试来回答本节关联的 2 道面试题目:
- 如何解决内存的循环引用问题?
- 三色标记清除算法的工作原理?
【解析】 解决循环引用的问题可以考虑利用 Root Tracing 类的 GC 算法。从根集合利用 DFS 或者 BFS 遍历所有子节点,最终不能和根集合连通的节点都是需要回收的。
三色标记算法利用三种颜色进行标记。白色代表需要回收的节点;黑色代表不需要回收的节点;灰色代表会被回收,但是没有完成标记的节点。
初始化的时候所有节点都标记为白色,然后利用 DFS 从 Root 集合遍历所有节点。每遍历到一个节点就把这个节点放入灰色集合,如果这个节点所有的子节点都遍历完成,就把这个节点放入黑色的集合。最后白色集合中剩下的就是需要回收的元素。
28 (1)加餐 练习题详解(五)
今天我会带你把《模块五:内存管理》中涉及的课后练习题,逐一讲解,并给出每个课时练习题的解题思路和答案。
练习题详解
24 | 虚拟内存 :一个程序最多能使用多少内存?
【问题】可不可以利用哈希表直接将页编号映射到 Frame 编号?
【解析】按照普通页表的设计,如果页大小是 4K,1G 空间内存需要 262144 个页表条目,如果每个条目用 4 个字节来存储,就需要 1M 的空间。那么创建 1T 的虚拟内存,就需要 1G 的空间。这意味着操作系统需要在启动时,就把这块需要的内存空间预留出来。
正因为我们设计的虚拟内存往往大于实际的内存,因此在历史上出现过各种各样节省页表空间的方案,其中就有用 HashTable 存储页表的设计。HashTable 是一种将键(Key)映射到值(Value)的数据结构。在页表的例子中,键是页编号,值是 Frame 编号。 你可以把这个 HashTable 看作存储了很多 <PageId, FrameId> 键值对的数据结构。
为了方便你理解下面的内容,我绘制了一张图。下图使用了一个有 1024 个条目的 HashTable。当查找页面 50000 的时候,先通过哈希函数 h 计算出 50000 对应的 HashTable 条目是 24。HashTable 的每个条目都是一个链表,链表的每个节点是一个 PageId 和 FrameId 的组合。接下来,算法会遍历条目 24 上的链表,然后找到 Page = 50000 的节点。取出 Frame 编号为 1232。
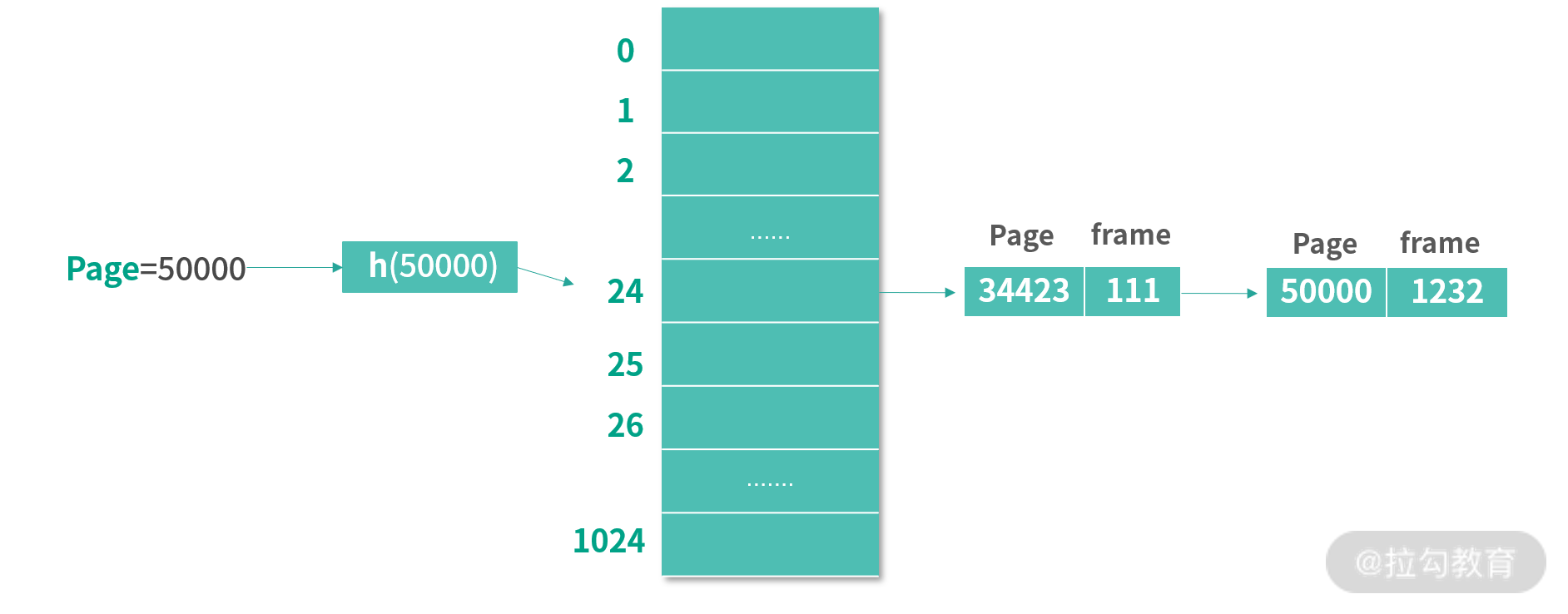
通常虚拟内存会有非常多的页,但是只有少数的页会被使用到。这种情况下,用传统的页表,会导致过多的空间被预分配。而基于 HashTable 的设计则不同,可以先分配少量的项,比如在上图中,先只分配了 1024 个项。每次查找一个页表编号发现不存在的情况,再去对应位置的链表中添加一个具体的键-值对。 这样就大大节省了内存。
当然节省空间也是有代价的,这会直接导致性能下降,因为比起传统页表我们可以直接通过页的编号知道页表条目,基于 HashTable 的做法需要先进行一次 Hash 函数的计算,然后再遍历一次链表。 最后,HashTable 的时间复杂度可以看作 O(k),k 为 HashTable 表中总共的 <k,v> 数量除以哈希表的条目数。当 k 较小的时候 HashTable 的时间复杂度趋向于 O(1)。
25 | 内存管理单元:什么情况下使用大内存分页?
【问题】Java 和 Go 默认需不需要开启大内存分页?
【解析】在回答什么情况下使用前,我们先说说这两个语言对大内存分页的支持。
当然,两门语言能够使用大内存分页的前提条件,是通过“**25 讲”**中演示的方式,开启了操作系统的大内存分页。满足这个条件后,我们再来说说两门语言还需要做哪些配置。
Go 语言
Go 是一门编译执行的语言。在 Go 编译器的前端,源代码被转化为 AST;在 Go 编译器的后端,AST 经过若干优化步骤,转化为目标机器代码。因此 Go 的内存分配程序基本上可以直接和操作系统的 API 对应。因为 Go 没有虚拟机。
而且 Go 提供了一个底层的库 syscall,直接支持上百个系统调用。 具体请参考Go 的官方文档。其中的 syscall.madvise 系统调用,可以直接提示操作系统某个内存区间的程序是否使用大内存分页技术加速 TLB 的访问。具体可以参考 Linux 中madise 的文档,这个工具的作用主要是提示操作系统如何使用某个区域的内存,开启大内存分页是它之中的一个选项。
下面的程序通过 malloc 分配内存,然后用 madvise 提示操作系统使用大内存分页的示例:
1 | #include <sys/mman.h> |
如果放到 Go 语言,那么需要用的是runtime.sysAlloc和syscall.Madvise函数。
Java 语言
JVM 是一个虚拟机,应用了Just-In-Time 在虚拟指令执行的过程中,将虚拟指令转换为机器码执行。 JVM 自己有一套完整的动态内存管理方案,而且提供了很多内存管理工具可选。在使用 JVM 时,虽然 Java 提供了 UnSafe 类帮助我们执行底层操作,但是通常情况下我们不会使用UnSafe 类。一方面 UnSafe 类功能不全,另一方面看名字就知道它过于危险。
Java 语言在“25 讲”中提到过有一个虚拟机参数:XX:+UseLargePages,开启这个参数,JVM 会开始尝试使用大内存分页。
那么到底该不该用大内存分页?
首先可以分析下你应用的特性,看看有没有大内存分页的需求。通常 OS 是 4K,思考下你有没有需要反复用到大内存分页的场景。
另外你可以使用perf指令衡量你系统的一些性能指标,其中就包括iTLB-load-miss可以用来衡量 TLB Miss。 如果发现自己系统的 TLB Miss 较高,那么可以深入分析是否需要开启大内存分页。
26 | 缓存置换算法: LRU 用什么数据结构实现更合理?
【问题】在 TLB 多路组相联缓存设计中(比如 8-way),如何实现 LRU 缓存?
【解析】TLB 是 CPU 的一个“零件”,在 TLB 的设计当中不可能再去内存中创建数据结构。因此在 8 路组相联缓存设计中,我们每次只需要从 8 个缓存条目中选择 Least Recently Used 缓存。
增加累计值
先说一种方法, 比如用硬件同时比较 8 个缓存中记录的缓存使用次数。这种方案需要做到 2 点:
- 缓存条目中需要额外的空间记录条目的使用次数(累计位)。类似我们在页表设计中讨论的基于计时器的读位操作——每过一段时间就自动将读位累计到一个累计位上。
- 硬件能够实现一个快速查询最小值的算法。
第 1 种方法会产生额外的空间开销,还需要定时器配合,成本较高。 注意缓存是很贵的,对于缓存空间利用自然能省则省。而第 2 种方法也需要额外的硬件设计。那么,有没有更好的方案呢?
1bit 模拟 LRU
一个更好的方案就是模拟 LRU,我们可以考虑继续采用上面的方式,但是每个缓存条目只拿出一个 LRU 位(bit)来描述缓存近期有没有被使用过。 缓存置换时只是查找 LRU 位等于 0 的条目置换。
还有一个基于这种设计更好的方案,可以考虑在所有 LRU 位都被置 1 的时候,清除 8 个条目中的 LRU 位(置零),这样可以节省一个计时器。 相当于发生内存操作,LRU 位置 1;8 个位置都被使用,LRU 都置 0。
搜索树模拟 LRU
最后我再介绍一个巧妙的方法——用搜索树模拟 LRU。
对于一个 8 路组相联缓存,这个方法需要 8-1 = 7bit 去构造一个树。如下图所示:
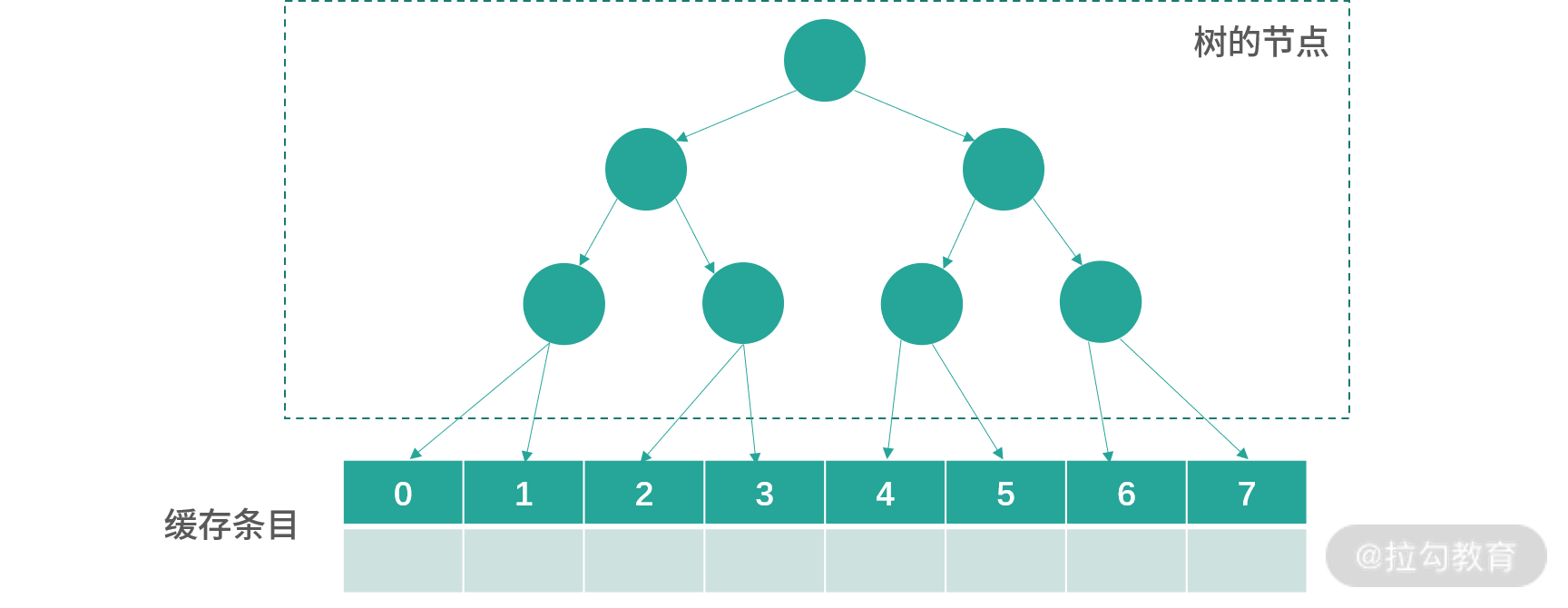
8 个缓存条目用 7 个节点控制,每个节点是 1 位。0 代表节点指向左边,1 代表节点指向右边。
初始化的时候,所有节点都指向左边,如下图所示:
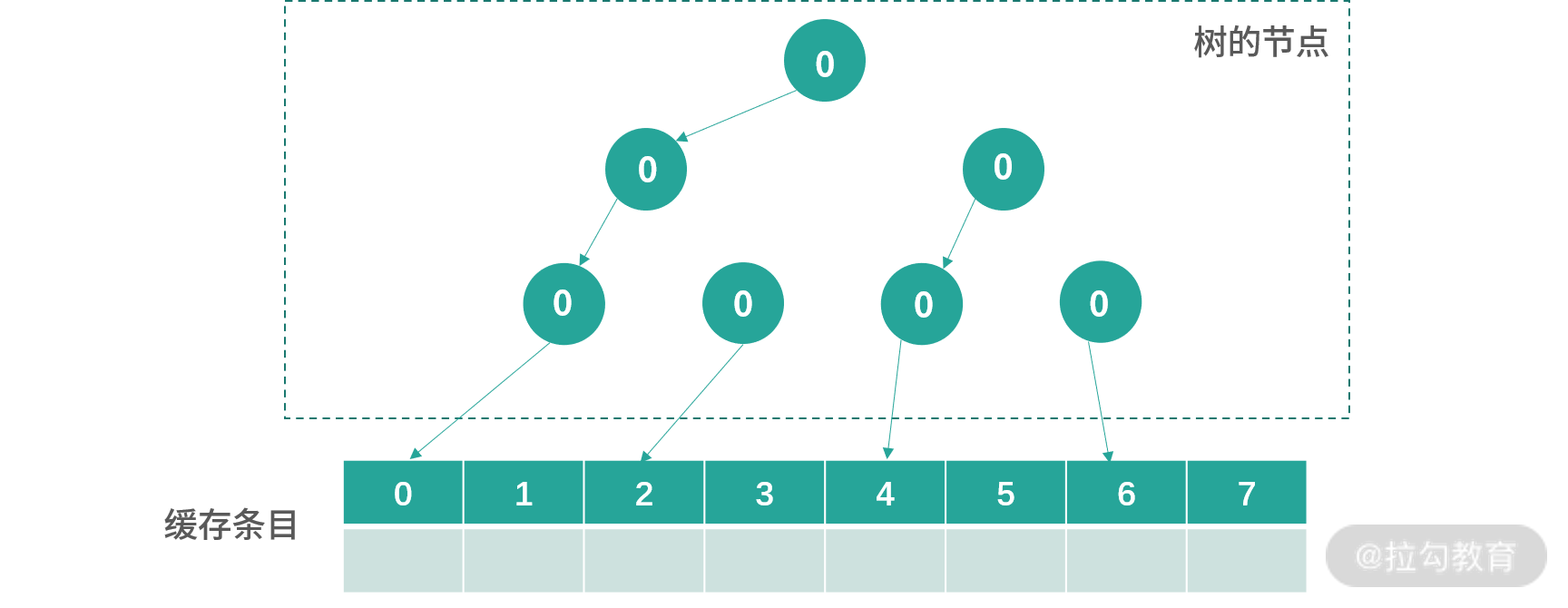
接下来每次写入,会从根节点开始寻找,顺着箭头方向(0 向左,1 向右),找到下一个更新方向。比如现在图中下一个要更新的位置是 0。更新完成后,所有路径上的节点箭头都会反转,也就是 0 变成 1,1 变成 0。
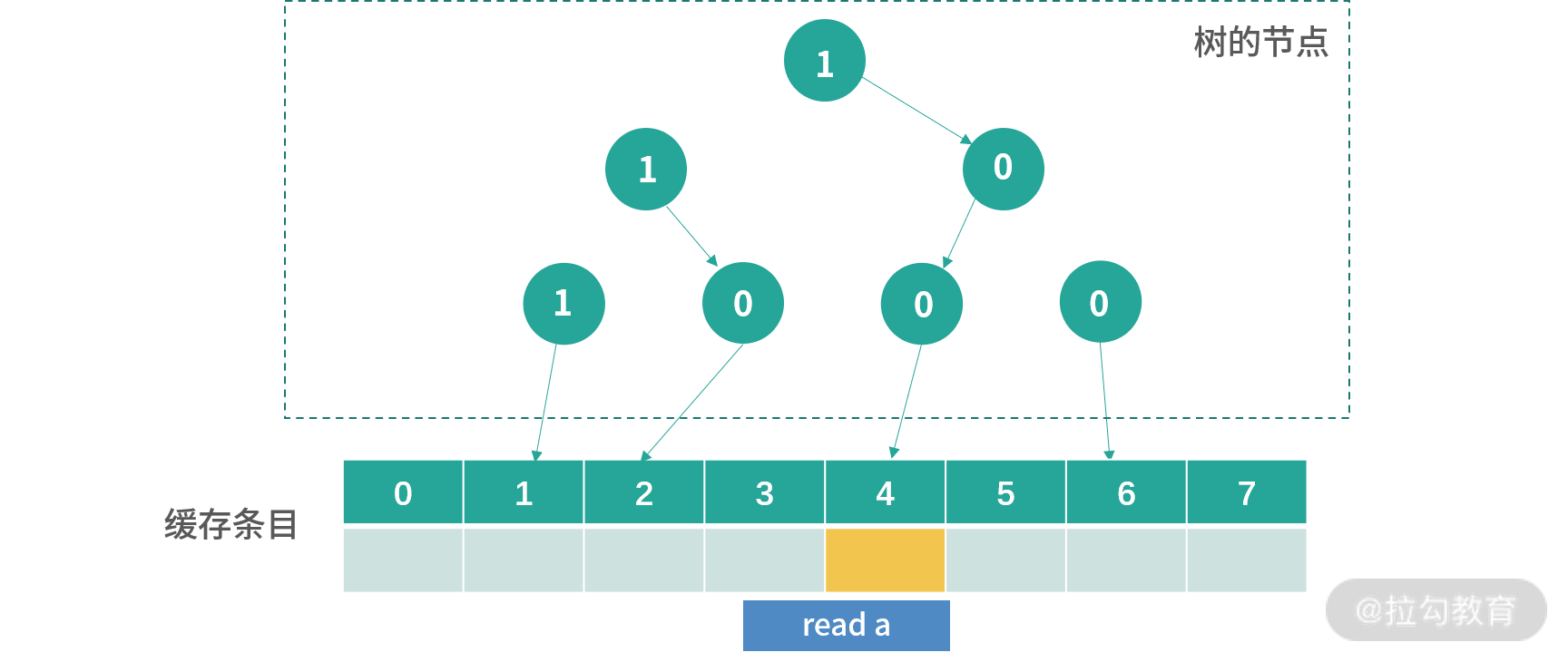
上图是read a后的结果,之前路径上所有的箭头都被反转,现在看到下一个位置是 4,我用橘黄色进行了标记。
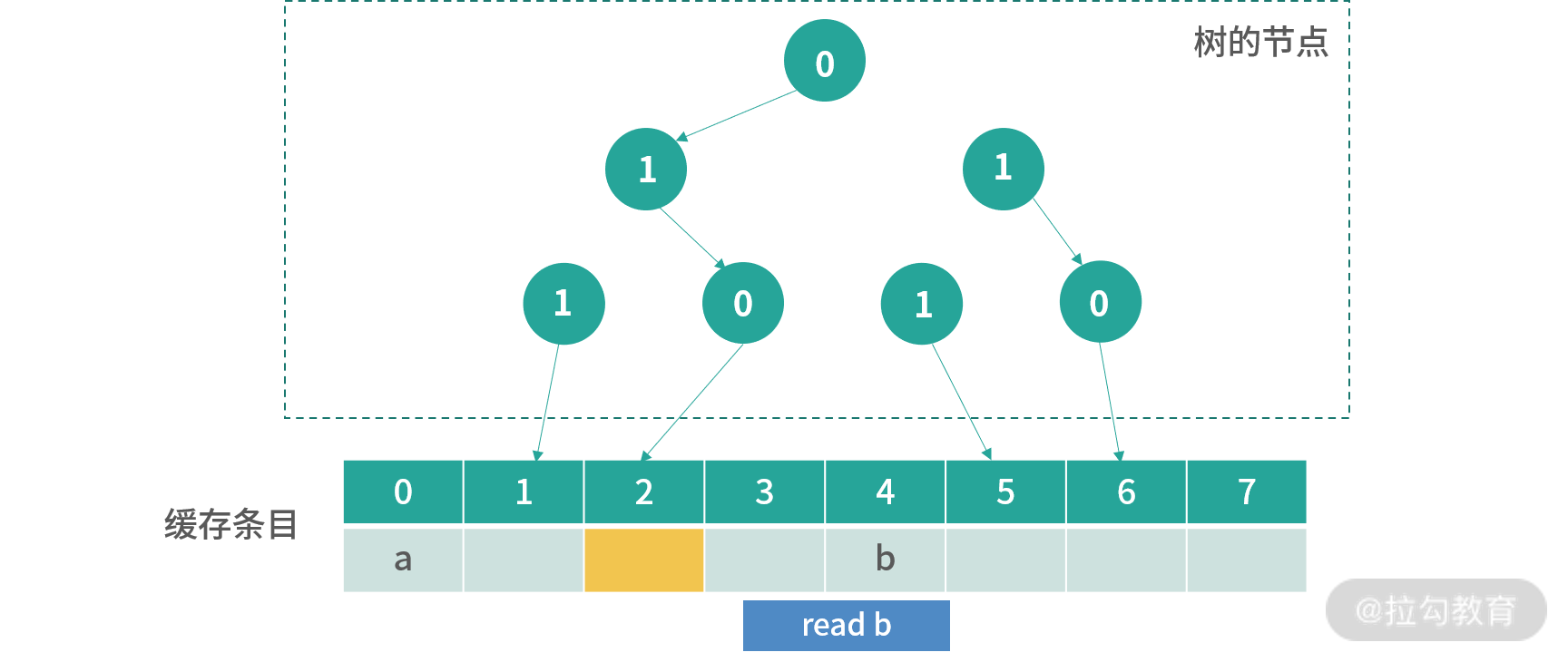
上图是发生操作read b之后的结果,现在橘黄色可以更新的位置是 2。
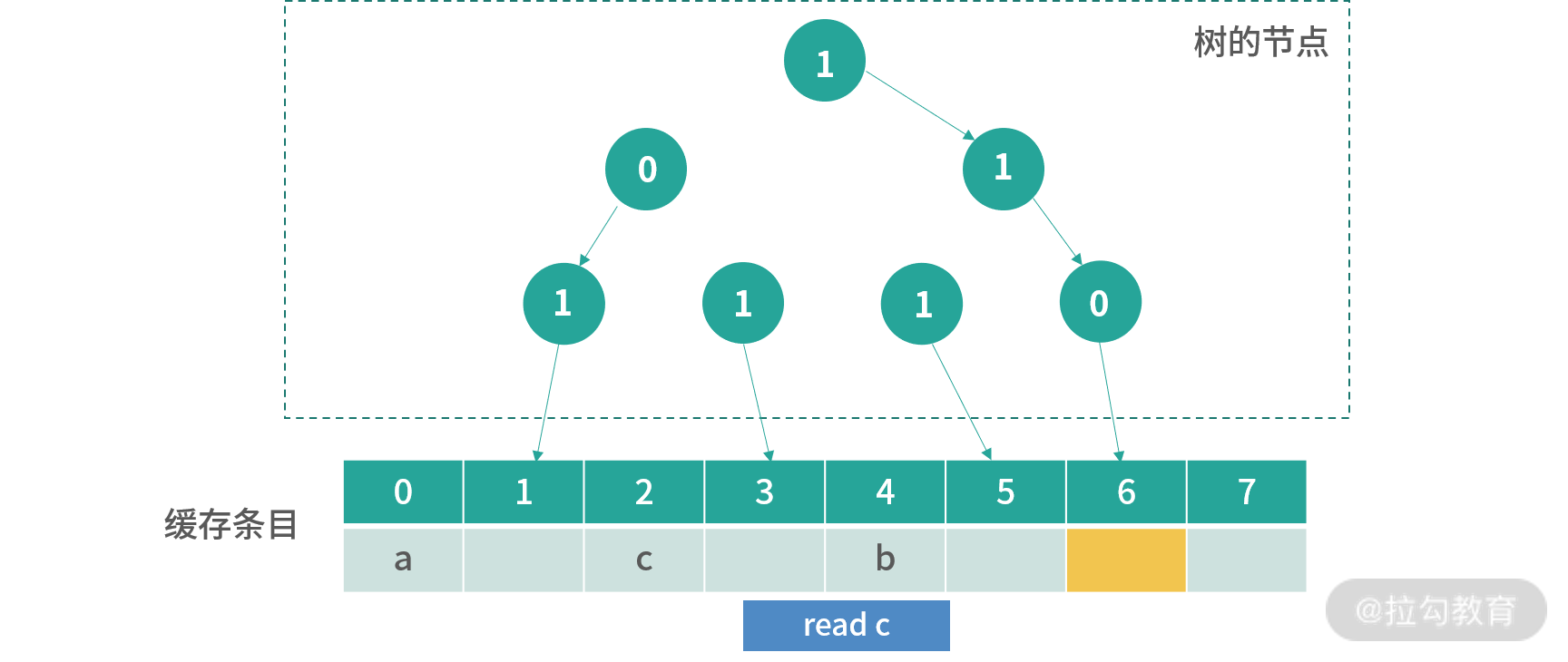
上图是读取 c 后的情况。后面我不一一绘出,假设后面的读取顺序是d,e,f,g,h,那么缓存会变成如下图所示的结果:
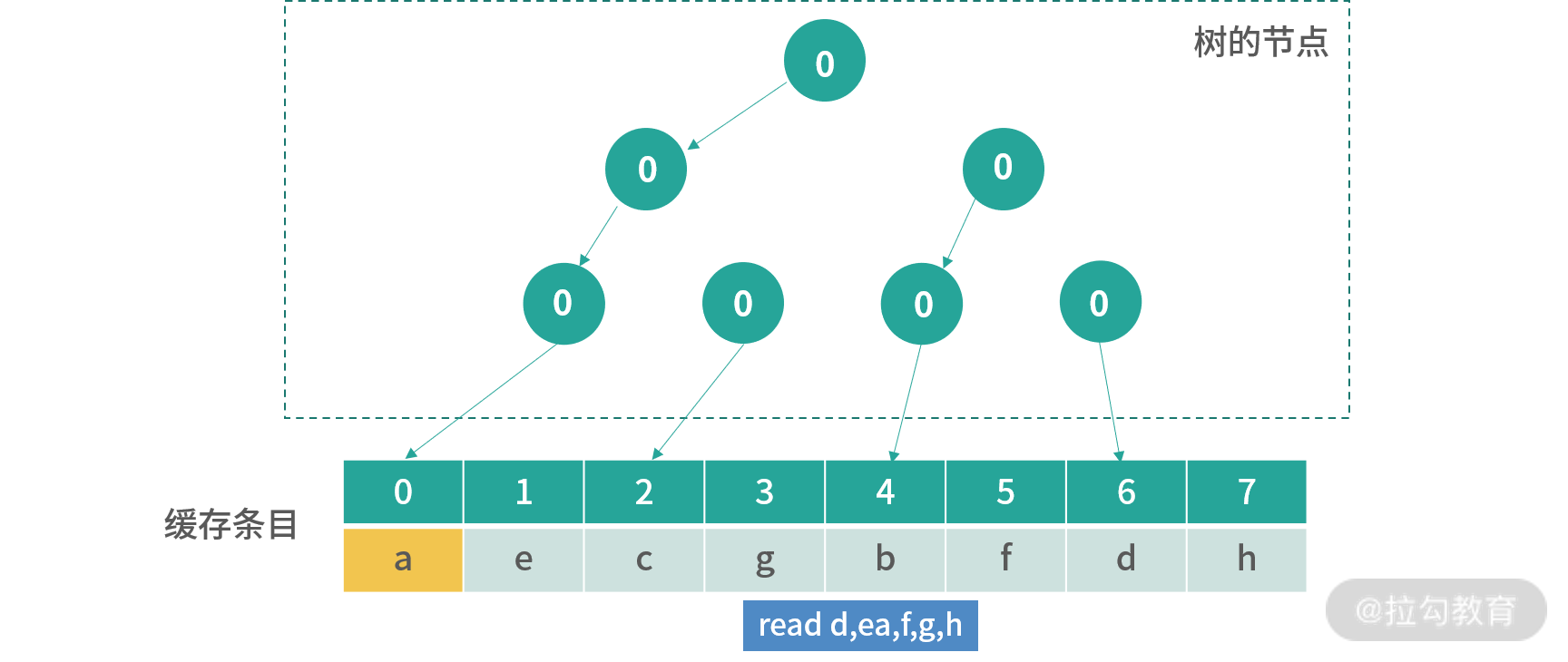
这个时候用户如果读取了已经存在的值,比如说c,那么指向c那路箭头会被翻转,下图是read c的结果:
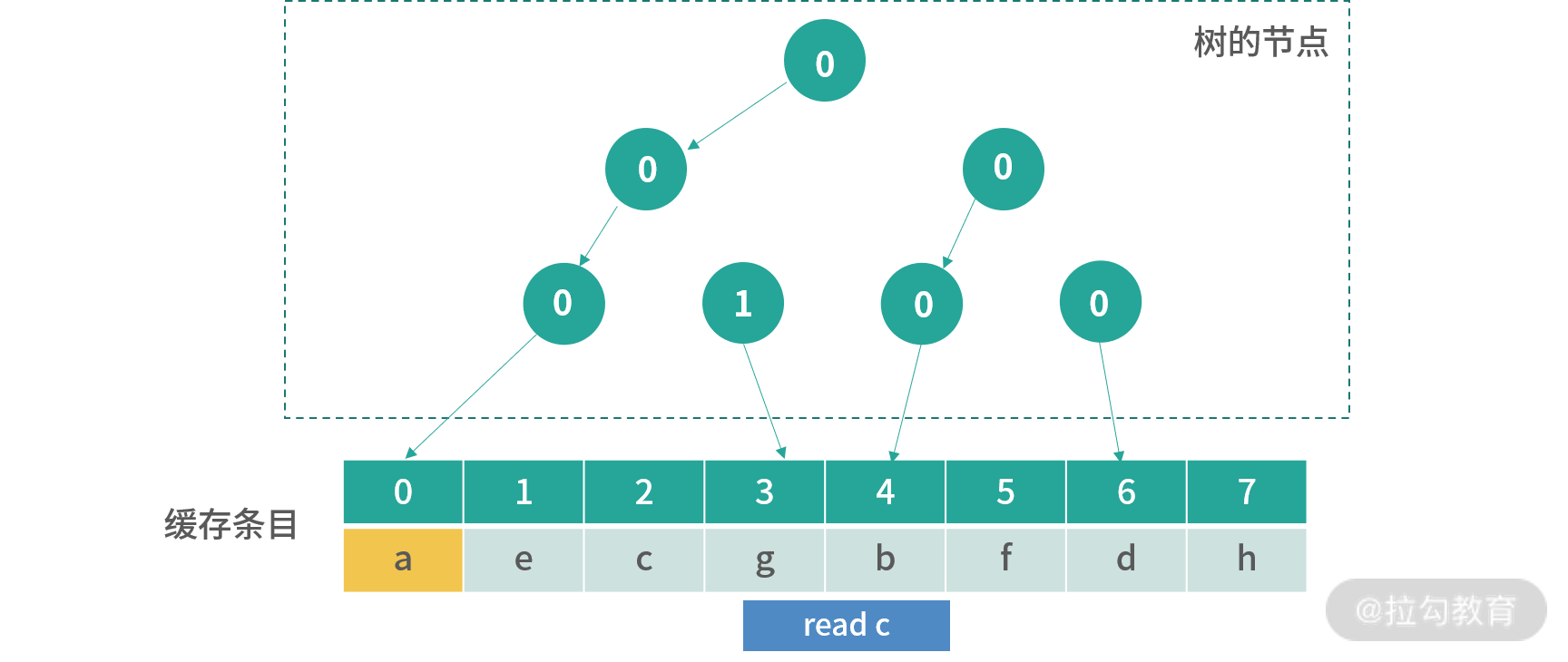
这个结果并没有改变下一个更新的位置,但是翻转了指向 c 的路径。 如果要读取x,那么这个时候就会覆盖橘黄色的位置。
因此,本质上这种树状的方式,其实是在构造一种先入先出的顺序。任何一个节点箭头指向的子节点,应该被先淘汰(最早被使用)。
这是一个我个人觉得非常天才的设计,因为如果在这个地方构造一个队列,然后每次都把命中的元素的当前位置移动到队列尾部。就至少需要构造一个链表,而链表的每个节点都至少要有当前的值和 next 指针,这就需要创建复杂的数据结构。在内存中创建复杂的数据结构轻而易举,但是在 CPU 中就非常困难。 所以这种基于 bit-tree,就轻松地解决了这个问题。当然,这是一个模拟 LRU 的情况,你还是可以构造出违反 LRU 缓存的顺序。
27 | 内存回收上篇:如何解决内存的循环引用问题?
28 | 内存回收下篇:三色标记-清除算法是怎么回事?
【问题】如果内存太大了,无论是标记还是清除速度都很慢,执行一次完整的 GC 速度下降该如何处理?
【解析】当应用申请到的内存很大的时候,如果其中内部对象太多。只简单划分几个生代,每个生代占用的内存都很大,这个时候使用 GC 性能就会很糟糕。
一种参考的解决方案就是将内存划分成很多个小块,类似在应用内部再做一个虚拟内存层。 每个小块可能执行不同的内存回收策略。
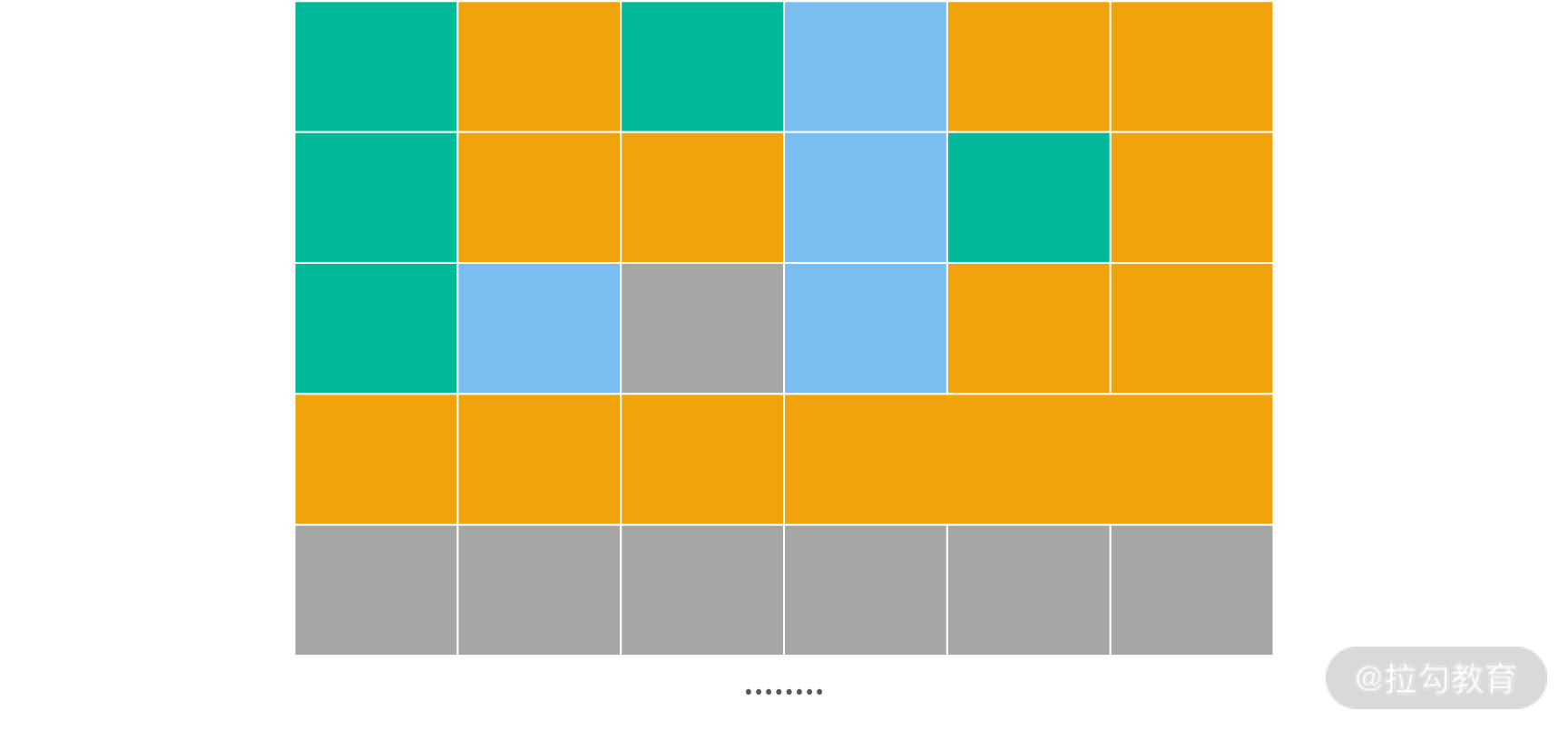
上图中绿色、蓝色和橘黄色代表 3 种不同的区域。绿色区域中对象存活概率最低(类似 Java 的 Eden),蓝色生存概率上升,橘黄色最高(类似 Java 的老生代)。灰色区域代表应用从操作系统中已经申请了,但尚未使用的内存。通过这种划分方法,每个区域中进行 GC 的开销都大大减少。Java 目前默认的内存回收器 G1,就是采用上面的策略。
总结
这个模块我们学习了内存管理。通过内存管理的学习,我希望你开始理解虚拟化的价值,内存管理部分的虚拟化,是一种应对资源稀缺、增加资源流动性的手段(听起来那么像银行印的货币)。
既然内存资源可以虚拟化,那么计算资源可以虚拟化吗?用户发生大量的请求时,响应用户请求的处理程序可以虚拟化吗?当消息太大的情况下,一个队列可以虚拟化吗?当浏览的页面很大时,用户看到的可视区域可以虚拟化吗?——我觉得这些问题都是值得大家深思的,如果你对这几个问题有什么想法,也欢迎写在留言区,大家一起交流。
另外,缓存设计部分的重点在于算法的掌握。因为你可以从这些算法中获得很多处理实际问题的思路,服务端同学会反思 MySQL/Redis 的使用,前端同学会反思浏览器缓存、Native 缓存、CDN 的使用。很多时候,工具还会给你提供参数,那么你应该用哪种缓存置换算法,你的目的是什么?我们只学习了如何收集和操作系统相关的性能指标,但当你面对应用的时候,还会碰到更多的指标,这个时候就需要你在实战中继续进步和分析了。
这个模块还有一个重要的课题,就是内存回收,这块的重点在于理解内存回收器,你需要关注:暂停时间、足迹和吞吐量、实时性,还需要知道如何针对自己的业务场景,分析这几个指标的要求,学会选择不同的 GC 算法,配置不同的 GC 参数。