01 我应该站在谁的肩膀上 - OSI vs TCPIP模型
相信很多人即使没吃过猪肉也看过猪跑(不知道谁说的老话,我要是猪肉都吃不起,去哪里看猪跑)。Anyway,我相信你即使不知道OSI 模型的详细内容,但你一定听过OSI 7层协议(可能不知道是哪7层)和TCP/IP 4层协议。
你一定会很疑惑,既生瑜何生亮,为什么有了OSI,还需要TCP/IP协议。那我们先来看一下什么是OSI网络模型?什么是TCP/IP模型?以及这两种模型的比较。
什么是OSI网络模型?
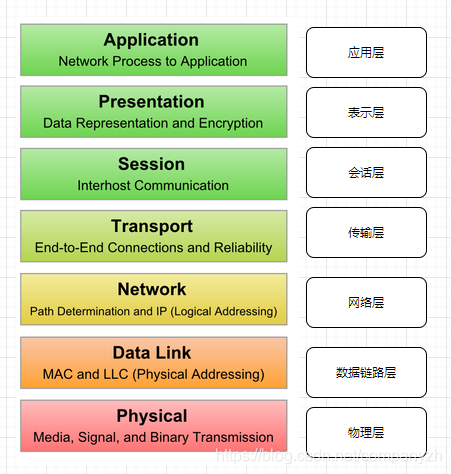
OSI英文全称叫做(Open System Interconnection Model). 中文全称叫做开放式系统互联模型. 也叫做网络7层模型,从下到上依次为,物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。
什么是TCP/IP网络模型?
TCP/IP 模型和OSI相比会简单一点,只有四层,分别为数据链路层,网络层,传输层和应用层。

什么是协议?
网络协议是一组确定的规则,这些规则确定如何在同一网络中的不同设备之间传输数据。本质上,它允许连接的设备彼此通信,而不管其内部过程,结构或设计是否有差异。(两个端点都需要了解协议才能进行交流)。
OSI和TCP/IP协议各有各的优点和缺点,我们先来看一下他们的共同点。
分层结构
他们都是基于分层的结构。那什么是分层以及分层的好处是什么呢?
- 将任务分为子任务,独立解决每个子任务
- 建立定义明确的界面层,使移植更容易
- 代码重用
- 可扩展性
- 标准化接口
我们来举一个例子来让你可以更好的理解这个模型。你或者你女朋友最喜欢的一句话。“xxx,你的快递到了”。那快递是怎么从义乌到你手上呢?我们就从你看上了某件商品之后开始。
- 你点击购买
- 消息发到商家的账户-知道有一个顾客要购买某一件商品
- 商品被商家放到快递箱子里,箱子上面贴上你的地址
- 顺丰小哥加上一些信息,扫一下barcode
- 当地办公室的司机把快递送上飞机然后送到转运站
- 从转运站再转到下一个离你最近的送货站
- 最后送到你的手上
你应该可以发现,每一步都是一层,可以详细的分成比如卡车运送层,商品层,地址层等等。希望这个例子可以对你的理解有所帮助。 PS: 你在做系统设计的时候,需要不需要考虑分层,自己仔细想一想好处和坏处。
那我们下面来看一下两种模型的优缺点
首先迎面走来的是OSI模型
OSI 的7层模型
我们上面也说过了从上到下是
- 7-应用层 -> 网络流程应用(表示的是用户界面,例如Telnet,HTTP)
- 6-表示层 -> 数据表示 (数据如何呈现,特殊处理->例如加密,比如ASCII,JPEG)
- 5-会话层 -> 主机间的通信(将不同应用程序的数据分开。建立,管理和终止应用之间的会话)
- 4-传输层 -> 端到端连接(可靠或不可靠的传递,例如TCP,UDP)
- 3-网络层 -> 地址和最佳路径(提供路由器用于路径的逻辑寻址,比如IP)
- 2-数据链路层 -> 媒体访问(将位组合成字节,将字节组合成帧,使用MAC地址访问,错误检测-比如HDLC)
- 1-物理层 -> 二进制传输(在设备之间移动bits。例如V.35)
一般来说把5-7层叫做上层,1-4层叫做下层。
让我再来稍微掰开的讲解一点。
- 应用层 - OSI模型的应用程序层直接与软件应用程序交互以提供所需的通信功能,并且它与最终用户最接近。应用层的功能通常包括验证通信伙伴和资源的可用性以支持任何数据传输。该层还定义了用于最终应用程序的协议,例如域名系统(DNS),文件传输协议(FTP),超文本传输协议(HTTP),Internet消息访问协议(IMAP),邮局协议(POP),简单邮件传输协议(SMTP),简单网络管理协议(SNMP)和Telnet(终端仿真)。你会发现这些都是有页面让你可以来操作的。应用层指的就是最高层。
- 表示层 - 表示层检查数据以确保它与通信资源兼容。它将数据转换为应用程序级别和较低级别接受的形式。第六层还可以处理任何所需的数据格式或代码转换,例如将扩展二进制编码的十进制交换码(EBCDIC)编码的文本文件转换为美国信息交换标准码(ASCII)编码的文本文件。它也可用于数据压缩和加密。例如,视频呼叫将在传输过程中被压缩,以便可以更快地传输,并且数据将在接收方恢复。对于具有较高安全性要求的数据(例如包含你的密码的短信),将在此层进行加密。这一层你可以只是读一下,不需要了解很多。
- 会话层 - 会话层控制计算机之间的对话(连接)。它建立,管理,维护并最终终止本地和远程应用程序之间的连接。第5层软件还处理身份验证和授权功能。它也验证数据是否已交付。会话层通常在使用远程过程调用的应用程序环境中明确实现。同理,这一层你也不需要了解很多。
- 传输层 - 传输层提供通过一个或多个网络将数据序列从源传输到目标主机的功能和手段,同时保持服务质量(QoS)功能并确保数据的完整传递。可以通过纠错和类似的功能来保证数据的完整性。它还可以提供显式的流量控制功能。尽管不严格符合OSI模型,但TCP和用户数据报协议(UDP)是第4层中必不可少的协议。这一层是你必须要深入了解的。后面会有详细的讲解。
- 网络层 - 网络层通过逻辑寻址和交换功能处理数据包路由。网络是可以连接许多节点的介质。每个节点都有一个地址。当一个节点需要将消息传输到其他节点时,它仅能提供消息的内容和目标节点的地址,则网络将找到将消息传递到目标节点的方法,并可能通过其他节点进行路由。如果消息太长,网络可能会在一个节点上将其拆分为多个段,分别发送它们,然后在另一节点上重新组合片段。网络层也是后面的重点。
- 数据链路层 - 数据链路层提供节点到节点的传输,即两个直接连接的节点之间的链接。它以帧的形式处理数据的打包和拆包。它定义了在两个物理连接的设备之间建立和终止连接的协议,例如点对点协议(PPP)。数据链路层通常分为两个子层:媒体访问控制(MAC)层和逻辑链路控制(LLC)层。 MAC层负责控制网络中的设备如何访问媒体以及允许传输数据。 LLC层负责标识和封装网络层协议,并控制错误检查和帧同步。 这一层只需要基本掌握MAC,不需要知道更多。
- 物理层 - 物理层定义了数据连接的物理规格。例如,连接器的插针布局,电缆的工作电压,光纤电缆规格以及无线设备的频率。它负责物理介质中非结构化原始数据的发送和接收。比特率控制在物理层完成。它是底层网络设备的层,从不关心协议或其他更高层的项目。这层你基本不用了解,除非你需要自己制作网线(我可是自己做过哦)。
那每一层怎么找到地址呢?
- 物理层 - 不需要地址
- 数据链路层 - 地址必须能够选择网络上的任何主机(MAC)
- 网络层 - 地址必须能够提供信息以启用路由(IP)
- 传输层 - 地址必须标识目标过程(PORT) 这些地址的信息都包含在每一层的头文件里,我们后面会详细讲。

优点
- 它可以帮助你标准化路由器,交换机,主板和其他硬件。就是说不管哪一家生产的硬件都可以互用,比如CISCO。
- 降低复杂性并使接口标准化
- 促进模块化工程
- 当技术发生变化时,可以用新协议替换老协议
- 提供面向连接的服务以及无连接服务的支持
- 它是计算机网络中的标准模型
- 支持无连接和面向连接的服务
- 它提供了适应各种协议的灵活性

缺点
- 协议的适配是一项繁琐的任务
- 你只能将其用作参考模型
- 它没有定义任何特定的协议
- 在OSI网络层模型中,某些服务在许多层中都是重复的,例如传输层和数据链路层
- 各层不能并行工作,因为每一层都需要等待从上一层获取数据
紧跟其后的这个年轻活力的小伙就是TCP/IP 协议
TCP/IP的4层模型
- 4-应用层 -> 对应于OSI的5-7层
- 3-传输层 -> 这个是和OSI的第四层想同的
- 2-网络层 -> 这个是和OSI的第3网络层对应的
- 1-网络访问层 -> 这个是和OSI的第1-2层所对应的
让我再来把TCP/IP也掰开一点
- 应用层 - TCP / IP模型的应用程序层使应用程序能够访问其他层的服务,并定义了应用程序用来交换数据的协议。最广为人知的应用层协议包括HTTP,FTP,SMTP,Telnet,DNS,SNMP和路由信息协议(RIP)。重中之重
- 传输层 - 传输层负责为应用程序层提供会话和数据通信服务。该层的核心协议是TCP和UDP。 TCP提供一对一,面向连接的可靠通信服务。它负责对发送的数据包进行排序和确认,并恢复传输中丢失的数据包。 UDP提供一对一或一对多的无连接,不可靠的通信服务。当要传输的数据量较小时(例如,该数据可以放入单个数据包中),通常使用UDP。
- 网络层 - 网络层负责主机寻址,打包和路由功能。 网络层的核心协议是IP,地址解析协议(ARP),Internet控制消息协议(ICMP)和Internet组管理协议(IGMP)。 IP是可路由协议,负责IP寻址,路由以及数据包的分段和重组。 ARP负责发现网络访问层地址,例如与给定Internet层访问关联的硬件地址。由于IP数据包传递失败,ICMP负责提供诊断功能并报告错误。 IGMP负责IP多播组的管理。 IP在此层中将标头添加到数据包中,称为IP地址。现在既有IPv4(32位)地址又有IP Ipv6(128位)地址。
- 网络访问层 - 网络访问层(或链路层)负责将TCP / IP数据包放在网络介质上,并从网络介质上接收TCP / IP数据包。 TCP / IP被设计为独立于网络访问方法,帧格式和介质。换句话说,它独立于任何特定的网络技术。这样,TCP / IP可以用于连接不同的网络类型,例如以太网,令牌环,X.25,帧中继和异步传输模式(ATM)。
优点
- 它可以帮助您在不同类型的计算机之间建立连接
- 它独立于操作系统运行
- 它支持许多路由协议
- 它使组织之间的互联互通成为可能
- TCP/IP模型具有高度可扩展的客户端-服务器体系结构
- 它可以独立操作
- 支持多种路由协议
缺点
- TCP/IP是设置和管理起来更加复杂。
- TCP/IP的浅层/开销高于IPX(Internet分组交换)
- 传输层模型不能保证包的传递。
- 在TCP/IP中替换协议并不容易。
- 服务,接口和协议没有明确的分离
总结
以上说了很多东西,是不是感觉很高深,你暂时不需要了解所有,当然也不可能要求你一下就明白所有。其实一句话来说两者的区别,那就是一个是理论的模型,一个是现实被做成了商品。
你需要记住以上的区别吗,我个人认为,大概读一遍就好,不需要背诵。不像上学时一样,让你背诵全文。即使是网络工程师也不会要求。并且我们以后会详细讲解每一层的功能。最后附上一个经典的图片,忘了是从哪里下载的,但是绝不是我自己的原创。如果知道的麻烦告知,我会把credit还给作者,你可以参考以下的这个图片。 好,这一小节就到这里。感谢你的学习。我们一起来开启这段神奇的旅程。

03 OSI的灵魂就是我 - 网络层
网络对网络的连接使互联网成为可能。 “网络层”是Internet通信过程的一部分,通过在不同网络之间来回发送数据包来进行这些连接。在7层OSI模型中,网络层是第3层。该层确定如何将数据发送到接收设备。它负责数据包转发,路由和寻址。在网络之间以数据包的形式传输数据段。当你向朋友发送消息时,此层将源IP地址和目标IP地址分配给数据段。你的IP地址是源,而你的朋友的IP是目的地。第3层还确定了数据传递的最佳路径。Internet协议(IP)是该层使用的主要协议之一,另外还有一些其他路由,测试和加密协议。

假设美国队长和黑寡妇连接到相同的局域网(LAN)来做给wayz(美版高德)做兼职配音,美国队长想要向黑寡妇发送消息。因为美国队长和黑寡妇在同一网络上,所以他可以将其直接通过网络发送到她的计算机上。但是,如果黑寡妇位于几英里之外的其他LAN上,则必须先处理美国队长的消息,然后将其发送到黑寡妇的网络,然后才能到达她的计算机,这是网络层的过程。
网络层可以想象成邮件载体,因为网络层的工作是弄清楚如何在网络之间获得最佳数据。我们几乎假设如果我们要调用第3层,那就是从一个网络转到另一个网络。甚至在数据中心内,你可能为Web服务器设置了一个网络,为数据库服务器设置了另一个网络。虽然它们物理上位于同一数据中心,但仍然是不同的网络,这无关紧要。因此,第3层就是使用路由表来了解网络在哪里以及谁可以访问它们。对我来说,这就像一个邮递员。你不一定知道朋友家在哪里。当你发送一封信给他们时,他们可能处于完全不同的州,国家或地区。邮递员根据他们的路由协议弄清楚,这类似于邮政编码,地址以及你所居住的地方。第3层的一些示例协议是IP,OSPF(即开放式最短路径优先),RIP(即路由信息协议)之类的东西,你真的不会再看到RIP了。有RIP,有RIP版本2,但是实际上,我没有遇到太多使用RIP的网络,但是我相信你可能对此有所了解,因为它在很长一段时间内都是非常流行的协议。最后,BGP是边界网关协议,Internet的核心路由使用BGP。理解起来很复杂,但是很有趣。
我们一直在说网络,那什么是网络?
网络是一组两个或更多连接的计算设备。通常,网络中的所有设备都连接到中央集线器,例如路由器。网络还可以包括子网或该网络的较小细分。子网是指非常大的网络(例如ISP提供的网络)能够管理数千个IP地址和连接的设备。将Internet视为网络中的网络:计算机在网络内相互连接,并且这些网络与其他网络连接。这样一来,这些计算机就可以与附近的其他计算机连接。
那网络层又干了什么呢?
与网络连接有关的任何事情都发生在网络层。这包括设置数据包采用的路由,检查其他网络中的服务器是否已启动并正在运行以及寻址和接收来自其他网络的IP数据包。这最后一个过程可能是最重要的,因为绝大多数Internet通信都是通过IP发送的。
网络层的主要功能
- 路由:当数据包到达路由器的输入链路时,路由器会将数据包移动到路由器的输出链路。例如,从S1到R1的数据包必须转发到S2路径上的下一个路由器
- 逻辑寻址:数据链路层实现物理寻址,网络层实现逻辑寻址。逻辑寻址还用于区分源系统和目标系统。网络层在数据包中添加一个标头,其中包含发送者和接收者的逻辑地址。
- 互联网络:这是网络层的主要角色,它提供了不同类型网络之间的逻辑连接。
- 分段:分段是将数据包分解为通过不同网络传播的最小的单个数据单元的过程。
网络层提供的服务
- 可靠的交付:该层提供的服务可确保数据包将到达其目的地。
- 带有延迟限制的保证传送:此服务保证在指定的主机到主机延迟限制内传送数据包。
- 有序数据包:此服务可确保数据包按其发送顺序到达目的地。
- 保证最大抖动:此服务可确保在发送方两次连续传输之间花费的时间等于在发送方两次接收之间的时间。
- 安全服务:网络层通过使用源主机和目标主机之间的会话密钥来提供安全性。源主机中的网络层对发送到目标主机的数据报的有效载荷进行加密。然后,目标主机中的网络层将解密有效负载。以这种方式,网络层维护数据完整性和源认证服务。
什么是数据包呢?
通过Internet发送的所有数据都被分解为称为“数据包”的较小数据块。例如,当美国队长向黑寡妇发送消息时,他的消息被分解成较小的部分,然后在黑寡妇的计算机上重新组合。数据包有两部分:标题(包含有关数据包本身的信息)和正文(正在发送的实际数据,比如说前方有监控,请减速慢行)。
在网络层,当数据包通过Internet发送时,网络软件会在每个数据包上附加一个标头,另一方面,网络软件可以使用标头来了解如何处理该数据包。(这部分会在后面讲ip的时候,详细讲解)
标头包含有关每个数据包的内容,源和目标的信息(有点像在目标和返回地址上标记信封)。例如,IP标头包含每个数据包的目标IP地址,数据包的总大小,在传输过程中是否已将数据包分段(分解成更小的片段)的指示以及多少个计数数据包经过的网络。
还记得我们之前说过在TCP / IP模型中,没有“网络”层。 OSI模型网络层大致对应于TCP/IP模型Internet层。在OSI模型中,网络层为第3层。在TCP/IP模型中,Internet层是第2层。换句话说,网络层和Internet层基本上是同一件事,但是它们来自Internet工作方式的不同模型。
什么是IP?
因为这一层主要的协议是IP。 那什么是IP呢?IP就是IP地址和IP地址用句点分隔的四个数字,代表网络上的第四个Rh标识设备。我们将I P地址分配给网络上设备的网络接口卡,并且我们的IP地址分为两部分。它具有网络部分或网络主管,并且具有主机部分。网络部分标识AH组联网设备。主机部分标识该特定网络上的单个设备。这与我们的地址将特定的街道地址识别为个人的方式非常相似。将房子的空气和邮政编码标识为一般区域,在该区域中,有很多房子的地址不同,但是它们都属于相同的邮政编码或地址。我们有邮政编码,有点像我们的网络长官,还有我们的主机部分,有点像我们的地址。我们在邮编中具有唯一标识或邮政编码,并且在邮编中具有通用标识。IP地址以四个十进制数字的格式写入。这些十进制数字中的每一个我们称为八位字节。因此203.0.113.10那里有四个八位字节。每个八位位组。它包含八个二进制位。因此,我们的IP/4地址始终为32位长。我们将其分为四组,每组八位,然后将它们转换回十进制,以便将其编程到计算机中并进行讨论。因为IP是那么的重要。我们后面会有一节专门讲解IP的课程。
那在这一层都有什么协议呢?
协议是一种公认的格式化数据的方式,以便两个或多个设备能够相互通信并相互理解。许多不同的协议使网络层的连接,测试,路由和加密成为可能,包括:IP, IPsec, ICMP, IGMP, GRE。你可以把这个当做一个窍门或者强行记忆也好,首先你要大概了解这个协议是做什么的,然后你知道了每一层是做什么的。这叫好像是一个连线题一样,把左右类似或者说相同功能连在一起,IP就不用说了,比如ICMP,全称是Internet Control Message Protocol。是一种错误报告协议,当网络问题阻止IP数据包的传递时,像路由器之类的网络设备会用于将错误消息生成到源IP地址。我给你介绍之后,还需要我告诉你他属于哪层吗?再来看以下GRE,不是你要出国考试的GRE,是一个协议(Generic Routing Encapsulation)- 通用路由封装是由思科系统公司开发的隧道协议,可以在Internet协议网络上的虚拟点对点链接或点对多点链接内部封装各种网络层协议。是不是很明显也是网络层的人。
这一小节可能讲的比较抽象。那是因为我们后面有专门的IP专题,所以不想多讲IP的事情。然而网络层的最大赢家就是IP。所以就从宏观来聊一下网络层。
04 要快还是要稳你说好了 - 传输层
现在,让我们继续前进。我们来一起看下一层。在上小节中,我们通过了IP知道要把包裹发给谁。我们现在必须进行设置在客户端和服务器之间建立某种会话或者说是连接,这其实和打电话时的情况非常相似,仔细想一下是不是?你打电话的时候,知道对方的电话号码也就是IP,那你怎么和对方通话呢。你不可能拿起电话就能直接说话了吧。你肯定希望它能和想要说话的人连接。你必须在自己和与之通话的人之间建立会话,对不对?我可以拿起手机,找到要呼叫的人的名字,或者在电话上拨打他们的电话号码。然后我会听并等待它响起。我会等我的朋友回答,当他们回答时,他们会打招呼。我会说,你好。现在,我们可以开始交流了。我现在说什么都没关系。但是在传输数据之前,必须经过特殊的过程,即拨打电话号码并通过协议进行连接。因此,数据网络中也会发生同样的事情。在OSI模型的第四层,我们使用一种称为“传输控制协议”,以允许我们在客户端和服务器之间建立此会话,以便可以说,是的,我们建立了该会话。现在,我想问你一些数据。OSI模型的这一层我们称为传输层,即第四层。
传输层为可靠的通信提供了完整的端到端解决方案。 TCP/IP依靠传输层有效地控制两个主机之间的通信。当IP通信会话必须开始或结束时,将使用传输层建立此连接。传输层是TCP/IP端口侦听的层。例如,尽管HTTP实际上可以在任何TCP端口上运行,但是HTTP侦听的标准端口是TCP端口80,这是标准。同样,端口80、1000或50000之间没有区别。任何协议都可以在其上运行。标准化的端口号用于帮助缓解为知名应用程序协商端口号的需求。
网络层协议只提供了点到点的连接,而传输层协议提供一种端到端的服务,即应用进程之间的通信。
那什么是点到点和端到端呢?
端到端是网络连接,点到点是物理拓扑。
端到端可以这样理解,比如说你老板去坎昆开会住在Grand Fiesta Americana Coral Beach Cancún。

让你负责订机票和酒店,对于你老板来说,从他/她家到这个酒店就是端到端。就是从A到B,但是老板可能瞬移过来吗,不会吧。你老板可能要先打车到机场,然后坐飞机可能先飞到美国,在转机坎昆,然后再打车到酒店,这其中的每一个步骤就是点到点。
所以说端到端其实是网络连接。网络想要通信,首先必须要建立连接,不管隔着千山万水,中间有多少机器和路由,都必须在两端(就是我们所说的Source和Destination)间建立连接,一旦连接建立起来,就说已经是端到端的连接了,所以端到端是逻辑链路,其中包含着无数个辛苦工作的点到点(就好像我们这些高贵的打工人一样)。

在这一层,我们知道的最有名的协议就是TCP和UDP。
我们来简单看一下TCP和UDP
TCP的介绍
TCP的全称是(Transmission Control Protocol)它是一种通信协议,通过该协议,数据可以通过网络在系统之间传输。在这种情况下,数据以数据包的形式传输。它包括错误检查,保证传递并保留数据包的顺序。
TCP使用流控制机制,通过一次发送太多数据包来确保发送者不会压倒接收者。 TCP将数据存储在发送缓冲区中,并在接收缓冲区中接收数据。当应用程序准备就绪时,它将从接收缓冲区读取数据。如果接收缓冲区已满,则接收器将无法处理更多数据并将其丢弃。为了保持可以发送给接收方的数据量,接收方告诉发送方接收缓冲区中有多少剩余空间(接收窗口)。每次接收到数据包时,都会使用当前接收窗口的值向发送方发送一条消息。
当你在浏览器中请求网页时,计算机会将TCP数据包发送到该网络服务器的地址,并要求其将网页发送回给你。 Web服务器通过发送TCP数据包流进行响应,你的Web浏览器将这些数据包缝合在一起以形成网页。当你单击链接,登录,发表评论或执行其他任何操作时,Web浏览器将TCP数据包发送到服务器,而服务器将TCP数据包发送回。
当提到TCP,你首先能想到的就是可靠。

所以TCP发送的数据包,在传输过程中不会丢失或破坏任何数据。这就是即使出现网络故障也不会损坏文件下载的原因。当然,如果收件人完全脱机,则你的计算机将放弃,并且你会看到一条错误消息,指出它无法与远程主机通信。TCP通过两种方式实现这一目标。首先,它通过对数据包编号来对其排序。其次,它通过让收件人将响应发送回发件人说已收到消息来进行错误检查。如果发件人没有收到正确的答复,它可以重新发送数据包以确保收件人正确接收它们。
也许TCP对于其他人来说,代名词是三次握手,TCP使用三次握手建立可靠的连接。连接是全双工的,并且双方彼此同步(SYN)和确认(ACK)。这四个标志的交换通过三个步骤(SYN,SYN-ACK和ACK)执行。“正常” 的TCP连接拆除是通过4次握手进行的。这个三次握手的协议其实和良好的通信是很相通的。
比如我曾经参加过一个training。是教你怎么和别人良好的沟通,其中一点就是重复确认。比如美国队长问黑寡妇,您吃了吗?黑寡妇回答,你是问我您吃了吗?美国队长说,是的。然后黑寡妇就可以回答,我吃了或者没吃,但是你有没有发现。在黑寡妇正式回答问题之前,是不是也使用了“三次握手”的原则来建立连接,下次你如果记不住的话,就想一下我说的这个例子。

那我们来看一下分手为什么要复杂一点呢。比如美国队长和黑寡妇谈恋爱,但是两人身高差太多,决定要分手,这时候美队和黑寡妇说,我觉得你很漂亮,但是我想和你分手,这时候黑寡妇说好的。我同意你的分手请求,但是作为女孩子这时候是不是要挽回一点面子,她会再说一句,记住了不是你和我分手,而是我和你分手。美队听了之后,只能回一个,好吧,我也同意和你分手,这样两人是不是就彻底分了。同理,我也希望你能记住美队和黑寡妇这段10秒钟的恋情是来帮助你学习TCP的分手过程。
UDP的介绍
其实UDP的优点还是很多的,除了不能保证错误检查和数据恢复之外,它与TCP协议相同。如果使用此协议,则无论接收端出现什么问题,数据都会连续发送。UDP不提供流控制。使用UDP,数据包以连续流的形式到达或被丢弃。它丢弃了所有的错误检查内容。因为所有来回通信都会引入延迟,从而降低速度。
当应用程序使用UDP时,数据包仅发送给收件人。发件人不会等着确定收件人是否收到了数据包,而是继续发送下一个数据包。如果收件人在这里和那里缺少一些UDP数据包,他们只是失去了,发件人不会重新发送它们(就好像某些无良快递一样,丢了就是丢了)。丢失所有这些开销意味着设备可以更快地进行通信。当需要速度且不需要纠错时,使用UDP。例如,UDP常用于直播和在线游戏。你可能不知道,QQ 就是以UDP协议为主,以TCP协议为辅的。感兴趣的你查一下微信是什么连接的。
假设你正在观看实时视频流,该视频流通常使用UDP而不是TCP进行广播。服务器只是向观看的计算机发送恒定的UDP数据包流。如果几秒钟失去连接,视频可能会冻结或跳动一会儿,然后跳到广播的当前位置。如果遇到较小的数据包丢失,则由于视频继续播放而没有丢失的数据,因此视频或音频可能会暂时失真。
这在网络游戏中也类似。如果你错过了一些UDP数据包,则当你收到较新的UDP数据包时,播放器角色可能会在地图上传送。如果你错过了旧数据包,就没有必要索要这些数据了,因为没有你,游戏将继续进行。重要的是游戏服务器上正在发生的事情,而不是几秒钟前发生的事情。放弃TCP的错误校正有助于加快游戏连接速度并减少延迟。
当然这也是我们后面要重点讲的两个协议。这里只是抛砖引玉。那是因为TCP和UDP是那么的重要。所以我们一定要深入的来探讨和学习。后面会详细到你想不理解都难。
05 是时候展现真正的技术了 - 应用层
可能细心的小可爱-你已经观察到了,我们虽然讲的是OSI,章节却是按照TCP/IP四层来讲的。所以我们今天会把会话层,表示层以及应用层一起讲。之所以这么讲就是也是因为第五和第六层可以不用考虑。在现代网络中,我认为它们并不完全重要(不重要在这里是说你在debug的时候,可以不用考虑,即使是网络工程师,当然作为软件工程师的你也不需要考虑这些)。我同意其他某些人的观点,存在即合理。有些协议确实在第五层和第六层起作用(当然是因为之前网络还没有那么发达,或者类似于IBM这种一家独大的时候,可以做一些事情来垄断,现在已经不存在了,就好像IBM这个公司你肯定知道,但是提到TOP IT公司你还会想到IBM吗,如果回答会,那你可能有点过时了,哈哈)。让我们再看回要讨论的问题。在这里是不是五个,六个和七个之间的区别并不是那么重要了。
会话层
会话层提供的服务可使应用建立和维持会话,并能使会话获得同步。会话层使用校验点可使通信会话在通信失效时从校验点继续恢复通信。这种能力对于传送大的文件极为重要。会话层,表示层,应用层构成开放系统的高3层,面对应用进程提供分布处理,对话管理,信息表示,恢复最后的差错等。
表示层
表示层是为通信提供的一种公共语言,以便能进行操作。这种类型的服务之所以需要,是因为不同的计算机体系结构使用的数据表示法不同。例如,IBM主机使用EBCDIC编码,而大部分PC机使用的是ASCII码。在这种情况下,便需要会话层来完成这种转换。现在,当我们使用键盘输入某些内容时,发生的事情是我们使用了一种称为ASCII的格式。 ASCII的作用是将每个字母,小写和大写以及键盘上的所有符号都转换为十六进制值。在本课程的稍后部分,我们将讨论十六进制编号系统,但是现在,只知道这是一种与十进制有点不同的计数方法,但实际上,它非常相似。它只从0到15计数,但不能由单个值到15计数,因此它从0到9计数,然后将A,B,C,D,E和F加进来凑到15。现在,仅需了解ASCII会将键盘上的任何字母都转换为该十六进制值。所以这里A是41。L是十六进制的6C数字,实际上是一个数字。空格是20,Y是79。如果我对其余所有字符都执行此操作,则得到的所有基数都属于我们,均以ASCII编写。你可以在这里看到一些相似之处,对吗?它表示为41 6c 6c 2079。好吧,这就是所有空间y。因此,在ASCII中,我们具有这种格式。ASCII是用于编码文本的开放标准。在20世纪70年代,IBM是一家规模庞大的硬件销售公司,IBM希望与众不同,以便你必须购买他们的硬件及其所有东西才能搭配使用,因此他们使用了一个称为EBCDIC的不同编码系统,EBCDIC所做的与ASCII相同。
它为不同的键盘字母分配了不同的十六进制值。表示层为我们做的是,如果你有一个运行非IBM系统的大型系统,并且需要与运行IBM的业务系统联网,则需要某种协议将ASCII转换为EBCDIC,你可以进行翻译,以便IBM机器可以理解该语言,而非IBM机器可以理解所传输的信息。表示层具有一些允许这种情况发生的协议。有时,我们拥有允许在表示层进行加密的协议,其中包括格式化图片等。在现代网络中,大多数这种格式设置完全在网络之外的应用程序内部进行。 EBCDIC在很大程度上已经死了,我们不再需要它了。
因此,表示层最终是有点过时的协议。这里有些过时的第二层是会话层。在会话层运行的协议称为Citrix ICA协议。不过,在大多数情况下,对于设计防火墙,网络,故障排除和支持的网络工程师而言,ICA协议在大多数情况下也可以在应用程序层运行。我们只是在规范中正式写了它,即ICA是第五层协议,而不是第七层协议。作为网络技术人员,当你进行故障排除时,不必担心自己是第五层还是第六层问题。所以这也是为什么现代的网络都是通过TCP/IP协议来进行实现的。OSI固然好,让每一层都那么的清晰明了。但是作为程序员的你一定清楚多一层就多一点复杂度。多了两层,肯定是有它的作用,当然相对应的也添加了“多余”。所以还是那句话OSI是标准,提到它就知道7层协议。它是那个标准,它是那个元老,但是随着网络的更新换代。很多东西可能已经不需要了。这一层基本就是介绍,当做一个历史来看就好了。不需要记住

现在我们来看一下应用层
我在这里问一个很经典的面试题,阿里有问过我这个面试题哦,当你在浏览器上输入www.taobao.com会发生什么?(自己试着来回答一下)。 敲Enter之后即告诉浏览器,嘿,我想在www.taobao.com上获取该网页,其中包含要观看的视频,照片和文字。当你这样做时,该https://www.taobao.com与服务器本身上的网站格式关联。所以我需要一个协议,该协议可使我将服务器上的网站转移到客户端上的Web浏览器。我使用称为超文本传输协议或HTTP的协议。此外,HTTPS为其加密版本。超文本传输协议的作用是将网页以称为超文本的格式编写,这是文本文档的基本格式,用于指示有关如何在Web浏览器中呈现信息的指令。这个超文本文档实际上是一个文件,就像Microsoft Word文档一样。我们可以使用HTTP或HTTPS传输该文件以获取加密版本。这里是HTTP,实际上是将网站从服务器传输到客户端的协议,也就是应用程序层协议,OSI模型的第七层。(我没有提及DNS以及其他一些发生的事情,因为我只是用这个作为一个例子。所以你面试的时候,这个不是面试的答案哦,只是提醒一下)。
如果我们现在看一下去掉第五层和第六层的OSI模型,那么我们就有了物理层,即电缆。我们具有数据链路层,该层允许一个设备与下一个设备对话,而下一个设备与下一个设备对话。我们拥有网络层,它为我们提供了一种寻址方案和一种机制,可将流量从Internet的一路一直移动到Internet的另一端。我们有第四层,即传输层,它使我们可以进行呼叫建立。因此,如果我们知道目的地的IP地址,则可以使用传输层和TCP来表示,我想和你一起传输一些数据,对吗?然后,我们有了应用程序层,它实际上将负责将所需的应用程序从服务器一直移动到客户端。
我们到这里就已经把OSI的7层模型都大致的讲解完了,希望你看完之后,对OSI的7层模型,有了一个全新的认识。当然其中还有很多没有细讲的东西,比如IP,TCP,UDP。但是你已经比过去的你知道的要多得多了。我希望你对OSI模型已经有了一个大概的认识,知道了每一层的作用和一些有用的协议。当然你对具体的协议还没有理解的那么深刻。但是不用着急,我们后面会慢慢的讲解。但是在这之前,我们要回归一下最基本的东西也就是二进制,如果你很熟悉,完全可以跳过下一章(但是我相信你还是能从我讲的学到你不知道的知识)。即使不是很熟悉,你应该也多少有一些了解,希望你可以温故而知新。有一个新的认识。
最后我们再来看一下在应用层都有什么协议。FTP,WWW,Telnet,NFS,SMTP,Gateway,SNMP,HTTP 。还是和之前一样,我们试着来匹配一下,做一下月老,看看你应该怎么连线。先来看一下FTP全称是File Transfer Protocol。文件传输协议是一种标准的网络协议,用于在计算机网络上的客户端和服务器之间传输计算机文件。 FTP建立在客户端-服务器模型体系结构上,在客户端和服务器之间使用单独的控制和数据连接。因为FTP 是文件传输协议,是对话协议,不属于基础层,所以它就被定义在上层了,也就是应用层了对不对。还有我们后面讲的重中之重HTTP(Hypertext Transfer Protocol)- 超文本传输协议:它是用于分布式,协作的超媒体信息系统的应用程序层协议。从定义上已经知道了它是应用层的协议了。我就不一一的讲解了。感兴趣的你可以去查一下上面列的每一个协议。
06 重回小学课堂 - 二进制101
我们今天开始进入新的一章-二进制。相信很多人知道二进制是0和1,但是具体的细节可能没有那么的清楚。如果你已经了解了,完全可以跳过这一章(虽然我还是建议你把这章好好看一下)。因为这一章本身就是为了温习一下基础知识。
现在就我们一起坐上这辆时光机器来重温一下曾经的学习。让我们进入二进制101的世界。正常计数时,我们以10为基数。我们通常不会去考虑规则,因为计数已成为我们生活中如此重要的一部分。大多数时候,我们使用的编号系统甚至没有怀疑或者注意过是什么规则,为什么只有从0-9。我们最有可能以10为底数,因为我们有10个手指。另一方面,二进制仅使用占位符的2个值(1或0)打开或关闭进行计数。因此,在十进制中,我们有10个值,从0到9。在二进制中,我们有2个值,0和1。上小学的第一天,老师就会让我们记住这些占位符以10的幂表示。我们从0开始计算那个占位符,然后我们最多计数1,2,3,4,5,6,7,8,和9。 当我们达到9时,我们用完所有值以填充此处的占位符。因此,我们必须添加另一个占位符,即十位数的占位符。然后我们可以再次开始算一个占位符,对吗?从1‑9、10一直到99,直到达到99,我们都用完了0到9的所有值,包括1和十位的占位符,因此我们必须添加另一个占位符。这次我们添加了百位的占位符。计数到999后,我们添加了另一个占位符,然后是一千,一万,再来是十万,然后是几百万,一千万,依此类推。因此,由于手指上有10个手指,我们采用这种方式进行计数,然后就演变为这种十进制计数系统。(知道为什么外星文明比我们先进吗,因为手指多。)
我们先来看一下为什么需要学习二进制呢?
二进制为什么重要?
- 二进制是编程的基础,但这与逻辑有更多关系,而不仅仅是数据存储。
- 布尔逻辑只有两个真值,“ true”或“ false”。布尔逻辑是计算机的基础。
- 在诸如信息论或安全性之类的更高级的CS学科中,从理论上讲,这与数据存储甚至数字系统无关,而与实际的二进制数学有关。
- 此外,如果你正在计算机上打字或对文本进行任何操作,那么你正在处理字符集。作为程序员,你必须了解某些有关字符集的知识。了解这些内容需要掌握使用位和字节存储数据的知识,以及可以在其中存储多少信息(256个不同的字节),这可以追溯到信息论。最后也涉及到数据存储。
- 不会二进制,不要奢望可以真正的理解IP,不信,你就跳过这章,直接看第三部分IP。
- 还有一点就是,二进制的运算是最快的,这也是面试的时候,会问到的点。我就问你,你想不想学吧。

二级制怎么转换成十进制呢

我们先来看一下这个,我有一个二进制数是1100 0000,其实它的每一位占位符依次是(128位,64位,32位,16位,8位,4位,2位,1位)。相信你已经看明白了,每一个占位符是上一位的占位数字乘以2。1乘以2就是2,2乘以2就是4,4乘以2就是8,8乘以2就是16.。。。以此类推。那怎么转换成10进制的数呢,就是通过占位符的数字来乘以那个位数的值也就是0或者1,比如这个例子是1100 0000,所以加起来就是128*1 + 64 * 1 + 32 * 0 + 16 * 0 + 8 * 0 + 4 * 0 + 2 * 0 + 1 * 0 = 192。 让我们再来试另一个数比如 0011 1010,那怎么计算呢 128 * 0 + 64 * 0 + 32 * 1 + 16 * 1 + 8 * 1 + 4 * 0 + 2 * 1 + 1 * 0 = 32 + 16 + 8 + 2 = 58。你自己可以多算几遍,相信你一定会掌握的。
十进制怎么转换成二级制呢

我相信你已经掌握了二进制到十进制,那反过来怎么算呢。让我们来算一下208。我们还可以用8位占位符(128位,64位,32位,16位,8位,4位,2位,1位)。从左面第一位也就是128位开始208-128是不是能得到一个正数呢,如果答案是yes的话,那你就可以在这位放一个1。然后208-128就剩80了。80减去64是不是也是一个正数呢。答案是yes,所以64位也是1,现在还剩80-64 = 16,16减去32是正数吗,不是,所以是0,16减去16是正数吗,答案是0。所以也可以放一个1,因为已经到0了,所以就不需要继续计算了,所以答案就是1101 0000,让我们来验证一下这个答案。128*1 + 64 * 1 + 32 * 0 + 16 * 1 + 8 * 0 + 4 * 0 + 2 * 0 + 1 * 0 = 208。这个是不是我们验证的那个十进制的数呢。答案是yes。让我们再来做一个测试,这回试一下47,从左面第一位也就是128位开始47-128是不是能得到一个正数呢,如果答案是no,那你就可以在这位放一个0。然后看下一位47 - 64 是正数吗?答案是no,所以这位也是0,再继续看,47-32是正数吗,答案是yes,所以这位是1,剩下的数是15,然后15 - 16 不是正数,所以是0,接下来的几位你就自己推算一下,所以答案是不是0010 1111,再让我们检查一下 128 * 0 + 64 * 0 + 32 * 1 + 16 * 0 + 8 * 1 + 4 * 1 + 2 * 1 + 1 * 1 = 47。
八进制
我们已经掌握了二进制,那现在就让我们来看一下8进制。八进制也被叫做Octal。其实原理都是一样的,这就是举一反三的时候,十进制是逢十进一,二进制是逢二进一,那8进制不用我说你也知道了吧。就是逢八进一。所以8进制的数就是0到7。你这时候可能会有疑问,二进制用在IP地址上,那8进制有什么用呢?
八进制广泛应用于计算机系统,比如ICL 1900和IBM大型机使用12位、24位或36位(是不是感觉无穷无尽,会不会有三进制,七进制,哈哈)。八进制是这些基础,因为他们的最理想的二进制字缩写大小能被3整除(每个八进制数字代表三个二进制数字)这里你可以想到了吧,所有的基础还是二进制,这也是为什么二进制是最重要和最基础的。四、八到十二个数字可以简明地显示整个机器。它也降低成本使得数字允许通过数码管,显示器,和计算器用于操作员控制台,他们在二进制显示使用过于复杂,然而十进制显示需要复杂的硬件,十六进制显示需要显示更多的数字。
然而,所有现代计算平台使用16 - 32位,或者64位,如果使用64位,将进一步划分为八位字节。这种系统三个八进制数字就能满足每字节需要,与最重要的八进制数字代表两个二进制数字(+ 1为下一个字节,如果有的话)。16位字的八进制表示需要6位数,但最重要的八进制数字代表(通过)只有一个(0或1)。这表示无法提供容易阅读的字节,因为它是在4位八进制数字。
因此,今天十六进制为更常用的编程语言,因为两个十六进制数字完全指定一个字节。一些平台的2的幂,字的大小还有指令更容易理解。现代无处不在的x86体系架构也属于这一类,但八进制很少使用这个架构,尽管某些属性的操作码的二进制编码变得更加显而易见。(我们在后面会讲解16进制)
八级制怎么转换成十进制呢
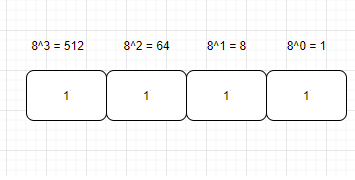
其实这个和二进制转成十进制是同一个原理。如果你在上面可以理解的很清楚了,那这里也没有什么难题,这又不是rocket science,right?好,让我来举一个简单的例子,我现在给你一个8进制的数12,那转成十进制是多少呢?让我们从最暴力的解法开始,就是穷举法。因为从8进制有0-7个数,所以从1 到 7 是没有区别的,然后当数值为8的时候,是不是8进制没有可以表示的东西。那是不是就要进一位了,所以八进制里面的10就是十进制的8,然后11就是9,12就是10,对不对。这种方法可以理解吗。如果我们用计算的方式来做,那是不是第一位是个位占位符,第二位是8位占位,第三位就是8的平方也就是64占位符以此类推。然后我来看一下这个例子12 = 1 * 8 + 2 * 1 = 10。这是不是我们穷举出来的结果。
我们再来仔细看一下这个占位符,不要嫌弃我啰嗦呀,都是为了让你可以更清楚,我们说的第一个占位符是1,第二个是8,第三个是64。我希望你能掌握规律,你仔细想一下第一个是不是8的0次方也就是1,第二个占位符就是8的1次方就是1,第三个也就是8的2次方也就是8*8 = 64。然后以此类推。
十进制怎么转换成八级制呢
好,那让我们来反过来看一下,十进制怎么转成8进制呢,道理同样相同,让我们来看一下这个例子54,54 小于64所以肯定不需要64占位符,现在看一下下一个占位符,54除以8 是不是等于6余数是6.所以8位占位符就是6,然后剩下的6除以1占位符。所以这个数值就是66。反过来验证一下。66 = 6 * 8 + 6 = 54。我现在如果让你写7进制或者6进制,你会写吗?其实原理都是互通的对不对?
当然这就是这节课索要包含的知识,也就是基础中的基础,但是看似简单,如果你没有学过,其实还是有一点点的小绕,相信我,这些知识就是我在读研究生的时候,都是每一节信号和通信相关的课程的第一课,你可以看出来它的重要性了吧。
08 16进制又是个什么鬼? - 16进制的讲解
十六进制这个词可能你第一次听会觉得很吓人,但是当你了解了它之后,很快你就会发现它是你的好朋友并且会爱上他。现在让我们一起来看看这个小可爱。
我们前面已经讲过了二进制,8进制以及你从小就知道的十进制,让我们来对比一下这些数值。对于从0 到9,对于16进制来说其实是没有区别的。
1 | Binary(二进制) 十进制 16进制 |
看到上面这个ABCDEF是不是感觉很神奇的操作,数字不够,字母来凑。可能你会觉得很奇怪,但是习惯了之后,你就会觉得还可以。那我们再来查看一下,十进制里的16怎么用16进制表示呢。我相信聪明的你一定想到了那就是“10”,当然这个10不是常见的10。
十进制怎么转换成16进制呢
假设我们现在要把数字95转成用16进制表示。和我们前面的方法类似,我们先用95除以16能得到什么呢,是不是等于5然后余数是15。所以答案就是5F。因为F表示的就是15对不对。
16进制怎么转换成10进制呢
我们还使用上面的案例来进行一下相反的操作,5F = 5 * 16 + 15 * 1 = 95。因为F表示15,所以使用15 * 1。其实你明白原理之后就会明白,这个很简单。
你可能会问哪里可以使用到呢,我给你一个鲜活的例子。那就是网页设计,不知道你有没有做过前端开发,在HTML和CSS上就是使用16进制来表示网页上的特定颜色。
到这里,你应该已经完全掌握了各个进制转换的精华,但是作为一个严谨的工程师,也为了让你们在将来面试的时候如果遇到这种进制的题可以对答如流。让我们来一起看一下面试可能会问什么类型的题。
面试问题1
给你2n + 1个数字,所有的数都会出现两次除了有一个数只会出现一次。找到这个数?
1 | 看一下这个例子 |
我希望你有看过我个人的文章,你就会了解我是怎么讲算法的,首先我们考虑一下最暴力的解法,你怎么做,你可以使用一个hashmap,把所有的数循环一遍,然后在查找这个hashmap,看哪个value是1,那个key就是你要找的对不对。但是这里你无形中使用了一个额外的数据结构对不对,也就是你的空间复杂度是O(n)。那我们下面来看一下可不可以优化这个。把这个空间复杂度从O(n)降为O(1)。
我们先来回顾一下小知识,还记得XOR吗,XOR的特点是什么,当0遇到0,或者1遇到1,就会变成0。就好像消消乐一样,那你再扩展一下这个概念,是不是任意两个相同的数字异或(XOR)之后是不是都是0,你想一下比如说数字3,二进制是011,那011异或011之后是不是0。所以我们来看一下上面的这个例子。1和1异或之后是1,2和2之后异或之后是0,4和4异或之后是0,最后得到的结果是不是就是我们要找的那个数也就是3。
可能你会有另一个疑问就是说顺序是不是有影响,让我们来看一下,3和4异或等于多少011和100 = 111,然后在和3异或之后也就是111和011 = 100也就是4, 如果和4异或111和100也就是011=3。结果是不是和你想的一样。
1 | public int findSingleNumber(int[] number) { |
面试问题2
给你两个数,你来决定需要翻转几个bits可以使两个数相同
1 | 看一下这个例子 |
是不是还是需要用到异或的特性,你异或这两个数,然后不断的使用>>>向右移,直到最后结果是0。然后你就可以知道有几位不同了。 这里就不给你们写代码了。因为代码很简单,主要是原理。感兴趣的你可以自己挑战一下。
当然这样的例题或者是面试题还有很多,在练习题里,会再给你们列出几道题,其实二进制也好,8进制和16进制也好,并没有什么特别难得问题,主要是转化你的思维,毕竟是计算机的思考方式。是不是你理解了之后,将来变成机器人的时候会更容易点(哈哈,开玩笑)。但是这个思维对你来说很重要,需要把基础还有原理理解清楚,然后根据特性来进行使用。主要的是异或运算,你也能看出来使用异或的地方很多,而且也是最有用的。希望你可以借助这一章来提升你对二进制的理解。好,那我们今天就到这里。
1 | public int bitFilp(int number1, int number2) { |
09 我想有个家 - 什么是IP地址
今天开始我们来看一下你可能听过的最多的一个概念,即使你不是工程师,你可能也听过这个词IP,当然可能IP的意思不一样。所以为了澄清,首先我们要来说一下我们的IP是什么?这里的IP不是Intellectual property,不是指的disney的Star wars。而是网络里面的IP即Internet Protocol。IP是一个很有用而且很复杂的概念。这也是为什么我要用一整章来讲解。
什么是IP?
那什么是IP或者说什么是IP地址呢?IP地址用由句点分隔的四组数字组成。我们前面的二进制里面也讲了这一点对不对。IP地址被分配给网络上设备的网络接口卡,并且我们的IP地址被分为两部分。它具有网络部分,另一部分是主机部分。网络部分标识联网设备。主机部分标识的是特定网络上的单个设备。这与我们的地址没有太大的区别。这与将特定的街道地址作为识别为个人的方式非常相似。将你房子周围的空气和邮政编码标识为区域,在一个区域里有很多房屋,但地址和门牌号都是不同的,你可能是住在一门,我是二门等等。但是它们都属于相同的邮政编码。我们的邮政编码,有点像我们的网络部分,还有我们的主机部分,有点像我们的地址。我们在邮编中具有唯一标识或邮政编码,并且在邮编中具有通用标识。
IP地址以四个十进制数字的格式写入。这些十进制数字中的每一个我们称为八位字节。因此203.0.113.10那里有四个八位字节。它包含八个二进制位。因此,我们的IPv4地址始终为32位长。我们将其分为四组,每组八位,然后将它们转换回十进制,以便将它们编程到计算机中并进行讨论。你想一下,那在每一组里的数字最大是多少?
1982年提出Ipv4时犯了一个巨大的错误,这也是我们需要克服的一个大障碍,这是将二进制转换成十进制而不是其他更有效的方式。(这像不像是你写的代码,会为后面的扩展产生影响和阻碍?其实很正常,你想想IP虽然有问题,但是也使用了将近30年。现在有了IPV6但是还需要一段时间来全面使用或者一起使用。)这里我们来思考一下或者是发散一下你的思维,现在这种形式如何识别地址的网络和主机部分呢?我们的地址始终包含网络部分和主机部分。但是应该如何确定哪个是网络部分哪个是主机部分呢?
地址类型
我们来看一下地址类型。我们可以从功能上来分类地址类型。基本上可以分为三类。
- 网络地址-它是系统中一组设备或一组IP地址的标识符。网络地址有点像我们的邮政编码,而没有与之关联的街道地址。邮政编码代表一个地理区域。我们的网络地址代表IP地址范围。网络地址有时称为网络前缀,或简称为前缀。
- 广播地址是第二种地址。广播地址是网络上所有设备的标识符。举个例子来说,在美国的话,纸质的邮件还是非常普及的。所以每家都会经常收到纸质的广告,比如说某某超市商品促销了之类的。这个就是广播,你会发现住在某一个区域的住户都会收到相同的广告促销。这个就有点像是广播地址。如果我有一个小公司想要发类似的广告,只需要去邮局然后说,我想把这个广告发给邮政编码xxxxx的住户,然后邮局就会帮我去投放了。广播地址的目的是可以一次将消息发送到网络上所有设备的地址。
- 主机地址是第三种。主机地址是确认在网络中的独一的设备。比如一台电脑,打印机或者是一个路由器。如果我们有一台设备比如说电脑想有一个IP地址。那么该计算机必须具有主机地址,并且不能为其分配网络地址或广播地址。前两种地址主要用于描述我们的网络,但是主机地址才是我们需要显示的应用到我们的设备上。
我们现在来深度剖析每一种地址类型,让你有一个更深层次的认识。
网络地址
先看一下这个例子
1 | 203.0.113.0 |
你在这里如果对子网掩码陌生,先忽略,我们后面会讲到。
如果你的地址的主机部分全部为零,就好像上面的例子那样,那么这个是网络地址。你永远不能将其分配给任何网卡。我下图标记出来了。如果全0或者全1。那就注定这不是一个普通的地址。

广播地址
先看一下这个例子
1 | 203.0.113.255 |
如果你的地址的主机部分为全部为1,就好像上面的例子那样,那么这个是广播地址。同理,你也永远不能将其分配给任何网卡。就好像上面说的,全0和全1都是特殊的。全0是网络地址。全1是广播地址。

主机地址
先看一下这个例子
1 | 203.0.113.10 |
我们上面讲的主机部分全是0的时候叫做网络地址,全是1的时候叫做广播地址,那其他的呢是不是就是我们需要的主机地址了。既然这个是主机地址了,是不是你就可以把它赋值给网卡了。可以赋给打印机,路由器等等。比如在这里,主机部分就是10。
所以,在这里子网掩码是一个不变量,那你的主机地址范围是不是就是在00000000 到 11111111之间的值。也就是1 到254。
私有和公有地址
私有地址只允许在一个公司内部使用,你仔细想一下,这说明什么,说明你在A公司的内部可以使用10.0.0.1,我在B公司也可以同样使用10.0.0.1对不对。这样会冲突吗?不会,因为是内部使用,互相是看不到的,为什么需要这样呢?开动你的小脑瓜想一下(下一小节会讲到)。当然不可能所有的IP地址都可以作为私有的,下面是所有私有地址的范围
1 | 10.0.0.0 -- 10.255.255.255 |
看透IP
我们之前说过数据的传输是靠Header来确定这是要传到哪里的数据。那我们来看一下IP的header是什么样子的?我懒得画了,就直接从网上找了一个。
我们还是一个一个的字段来讲解。
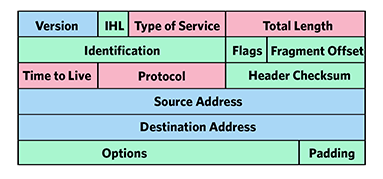
- Version(版本号)4bits:用来暗示版本号,我们一直说IPV4,那这里就是4对不对,那IPV6呢?
- IHL(Internet Header Length头部长度) 4bits:头部的长度
- Type of Service(服务类型)8 bits:因为是8 bits,所以可以分成下面的8个值。用于定义包的优先级,值越大,数据越重要,我就不翻译下面的意思了。感兴趣的自己查一下。
- 000 Routine
- 001 Priority
- 010 Immediate
- 011 Flash
- 100 Flash Override
- 101 CRI/TIC/ECP
- 110 Internet Control
- 111 Network Control
- Total Length(总长度)16 bits:总长度,包括头和数据
- Identification(标识) 16 bits: 一个序列号,与源地址,目标地址和用户协议一起,旨在唯一地标识一个数据报(Datagram)
- Flags(标志)3 bits: 当前仅定义了两个位。更多的位用于分段和重组。第二位是DF(Don’t Fragment)位。如果已知目标没有重组片段的功能,则此位可能很有用。但是,如果设置了此位,数据报一旦超过路由网络的最大大小,则该数据报将被丢弃。
- Fragment Offset(片偏移)(13 bits):此片段在原始数据报中的位置(以64位为单位)。这意味着除最后一个片段以外的其他片段必须包含长度为64位倍数的数据字段。
- Time to Live(生存时间)(8 bits):定义一个电报允许在网络中存活的时间,以S来计算。
- Protocol(协议)8 bits: 指示在目的地接收数据字段的下一个更高级别的协议,此字段标识ip头之后的数据包中下一个头的类型,举个例子。TCP的值是6,UDP的值是17。
- Header Checksum(首部校验)16 bits: 仅应用于头部的错误检测。
- Source Address(源地址)32 bits: 源IP地址
- Destination Address(目标地址)32 bits: 目标IP地址
- Options(选项)variable:编码发送用户请求的选项
- Padding(填充)variable:用于确保数据报头是32位长度的倍数
- Data(数据)variable:数据
下面来看一个具体的例子。不知道你有没有听过wireshark,这是一个用于包裹分析的工具,感兴趣的可以下载来试一下。
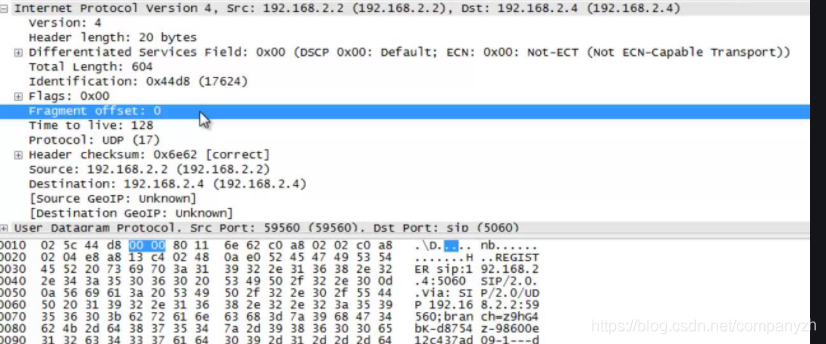
从上图你可以看出,你们包含着我们上面讲的header里面的内容,上面的是理论概念,这个图是在实际发送中的具体数据包里面有什么。比如你可以看到version:4也就是IPV4。然后就是Header length,TotalLength。。。等,你可以对着上面的理论模型来找到一一对应。
10 我可是住二环的人 - IP地址的组成和分类
通过上一小节,相信你对IP有了一个初步的认识。这一小节,和我一起来了解一下IP地址的黑历史。以及它的演变进程。
分类网络

现在和我一起来一次时间旅行,boom!我们回到了1981年,这一年开始出现了分类网络。我们来看一下它的工作方式是什么。这是子网掩码出现之前的事情。因此,如果你生活在1985年,那么你要在设备上输入IP地址。是没有子网掩码的。我们不需要子网掩码,为什么?因为它还不存在呢。也就是说还没有出生呢。分类网络确定了网络部分和地址的主机部分。根据地址类别,我们有5个A,B,C,D和E类。具体的分类看下面
1 | class Private IP Range |
从上面的分类可以看出,每一个类别的IP地址是固定的。A类地址是从0到127.255.255.255。然后紧接着的就是B类从128.0.0.0到191.255.255。你有没有发现127.255.255.255的后一个数值就是128.0.0.0,所以A和B其实是紧紧相邻的。然后再来看C的开始192.0.0.0是不是也是紧接着B的最后一个也就是191.255.255.255。所以C类地址就是192.0.0.0 到223.255.255.255。然后依次类推D类就是224.0.0.0到239.255.255.255。最后的E类也就是240.0.0.0到255.255.255.255了。
我们来分析一下A类的地址,其实就是前8位的字节是网络部分。看下面的这个例子。
1 | 10.0.10.0 |
B类的地址就是前16位的字节是网络部分
1 | 172.16.10.10 |
C类的地址就是前24位的字节是网络部分
1 | 192.168.0.10 |
D类的地址就是前32位的字节是网络部分,没有主机部分
1 | 224.0.0.6 |
D类地址主要是用于广播。这是CCNA的一个很重要的考点,但是你不需要了解CCNA,因为你不是网络工程师(这里指的是天天调试Switch和Router的工程师)。然后E类的地址只是用于实验,并不会实际的使用。所以你也能看到这种分法的使用其实很没有效率,这也是为什么有了子网掩码。当时设计的人可能做梦也没有想到会有物联网,就是你的冰箱和微波炉都需要一个ip。
无类寻址(IPV4最后的挣扎)
让我们再次坐上我们的时光机,来到1995年。从1995年以后,我们将开始谈论无类寻址,因为这完全是你在职业生涯中要做的事情。毕竟你现在是2021年的新新人类。它的工作方式是什么呢?那就是我们现在必须使用子网掩码。子网掩码是1994,1995年添加到IP地址上的一个技术。该技术的作用是说我们想要网络部分和地址的任何地方,我们将创建一个单独的数字,一个掩码。这是一个独立的数字,将全1放入我们要网络部分的相应位,将所有0放入主机的部分。看一下下面这个例子。
1 | 203.0.113.10 |
因此,看一下上面的例子,你可能会稍微清楚一点。以上发生的事情是我们有了ipv4,然后在它的下面,有一个称为子网掩码的东西。主题掩码通过在子网掩码中放置一个或我们想要的网络部分,并在想要宿主部分的位置用零来告诉我们地址网络的哪个部分是主机。因此,如果将其转换回十进制,则二进制的11111111会转换为十进制的255。因此,我们将此地址203.0.113.10与子网掩码255.255.255.0结合在一起,现在我们可以显式地将网络部分和主机部分分开。但是,子网掩码的值不一定必须为255.255.255.0。使用无类寻址,我们可以将网络部分移动到所需的任何位置。因此,如果我们的网络部分只需要八字节,我们可以将子网掩码的前8位的掩码更改为1,并将子网掩码的后24位更改为零。那看上去就是下面这样
1 | 10.0.0.10 |
当我们转换它时,我们得到255.0.0.0作为掩码,这简单地意味着我们IP地址的前8位是我们的地址的网络部分。其余的地址是主机部分,子网掩码不必每8位变化。它可以变成或者放在我们想要放的任何地方。因此,如果需要的话,你可以设置一个子网掩码比如前20位是网络部分,最后12位是主机部分。那会给我一个255.255.40.0的掩码。例子如下
1 | 10.0.0.10 |
当然这是一个不寻常的情况,子网掩码恰好位于八位字节的中间。稍后在进行子网划分时,这会导致一些异常的十进制数字从我们的IP地址中弹出。但是,实际上,我想提出的要点是子网掩码的功用。子网掩码是确定IP地址的哪一部分寻址网络部分以及哪一部分是主机部分的数字。
好,现在让我们温故知新一下,还记得上节课讲的地址类型吗,来做一下下面的这个练习题。
1 | 这个是什么地址? |
11 我已经没地方住了吗 - IPv6
IPV6的成长史
IPV6其实已经是一位80后。它生于八十年代后期,当时的工程师们已经意识到IPV4的空间正在迅速耗尽。然后到了1995年左右,IPV4进行了一次挣扎。那就是实现了子网技术(我们前面有讲过),这样就可以缓解IP地址不足和遍及全球的问题。从那时起已经过去了20多年,我们现在才刚刚开始看到IPV6在世界上的快速发展和部署。(我记得我2011年的时候想要去考CCNA,IPV6的知识设计的很少)。那么这是否意味着我们将立即转成IPV6吗?那当然是极不可能的。比如在医疗保健领域。IT的技术不是那么的先进。整个商业领域中尚不支持IPV6。因此,我们必须要找到一种折中的办法。你先去洗一下脸,清醒一下。忘记IPV6已经三十多岁了还一事无成。忘记某些领域完全不支持IPV6。我希望当你读到这篇文章的时候,内心是充满希望,是充满着对明天美好的憧憬。我们来看一下IPV6的工作原理。他本身是一个阳光帅气的中年大叔(每位大叔都是潜力股)。只是还没有完全的开花。
IPV4 vs IPV6
俗话说的话,没有对比就没有伤害,但是不对比,我们又怎么能知道两者的区别以及强弱呢。那我们就来无情的对比一下IPV4和IPV6。
IPV4
首先IPV4是32字节长,有4个八位位组。 比如192.168.0.10。转成二进制就是11000000 1010100 00000000 00001010
IPV6
IPV6呢却比IPV4要长很多。有128位。表示的方式呢,也是16进制的。比如这个例子2001:0DB8:0123:007D:0000:0000:00A5:53B5。
IPV6的话,也同样分为网络部分和主机部分。一般是前64位作为网络部分,这个不是必须的。却是极力推荐的,因为IPV6就是这么设计的。可能你会觉得这个IPV6的地址太长了,这是不是太难记了。这位80后的钻石王老五已经想到了。为了可以吸引更多的漂亮妹子。它做了一些改变。比如前缀0优化。这是什么意思呢?
1 | 比如说你现在手上有1元,那你写成01元还有001元还有0001元有区别吗?是不是都等于1元。 |
这里提示一个潜在的错误,那就是::这种简写只能用一次。比如下面这个例子就是错误的
1 | 2001:DB8:123::A5::53B5 (X) 你想一下这个为什么是错误的呢? |
如果你都无法判断,你怎么可能要求计算机知道哪种是你需要的呢?所以这个是要切记的点。
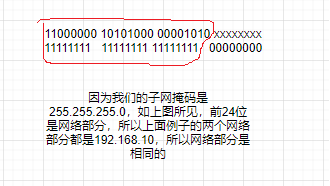
我们知道了IPV6的结构,那IPV6是怎么运作的呢,理论上来说和IPV4运作非常相似。如果有两台设备用电缆连接在一起。他们想要互相通信的话,这些地址的网络部分必须匹配。比如这个例子
1 | 192.168.10.10 |
如果我的IPV4不具有相同的网络部分,那么这些设备就无法就行通信。比如下面这个例子。
1 | 192.168.55.10 |
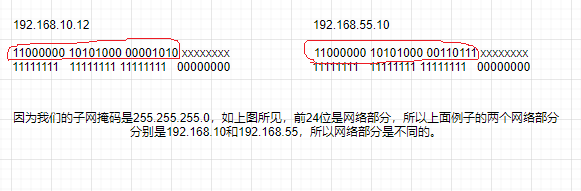
从这个图的红色范围里,你可以清楚的看到两个IP地址的网络部分是完全不同的。所以无法直接进行通信。除非你在中间添加一个路由器。
IPV6和IPV4的原理是相似的。如果网络部分相同,之间是可以互相通信的。比如
1 | 2001:CA7:3:B::10/64 |
如果我稍微的修改一下,比如下面这样,那他们就不能直接通信了。当然路由器还是可以解决问题的
1 | 2001:CA7:3:A::10/64 |
我们来放大我们的场景到Internet。当在Internet上进行通信时,我们需要使用的是称为IPV6的全球单播地址,用于全球通信。还需要一个链路本地地址来进行本地的通信。让我们继续向下一起来看一下IPV6的地址类型。
IPV6的地址类型
- 单播地址
- 全球单播地址
- 链路本地地址 - 用于本地的通信。格式必须是FE80::/10
- 环回地址 - ::1/128 (还记得IPV4的环回地址是多少吗127.0.0.1)
- 未指定地址 ::/128
- 唯一本地地址 FC00::/7, 这个地址是不可以和公共网络进行交流的,这点和IPV4不同,IPV4的话,即使是私有地址,通过NAT还是可以和公网通信。但是在IPV6中,却无法左到这一点。所以这个唯一本地地址对你做实验和练习的时候比较有用,但是不适合设置你的网络环境来和公网通信。
- 组播地址
- 一对多的通信。主要用于企业内部
- 任播地址
- 一个IPV6地址赋给多态机器(Wait a Sec。这时候你是不是会有疑惑,这样是不是违规了?你的猜测是正确的,那你开动脑瓜想一想,有什么场景可以这么使用)–> 负载均衡(Load Balancing)
IPV6的地址数量
你是不是会有一个疑问?就是我们之所以使用IPV6就是因为IPV4的地址太少了,快被用完了,所以才有了IPV6,那么IPV6有多少地址呢?我可以负责任的告诉你,很多很多。真的是太难以计算了,我们来看一个单一的网络地址吧。比如网络部分已经确定了,然后只考虑主机部分的64位。就是说一个确定的IPV6网络地址上有多少个主机地址可以分配,就是2的64次方,计算出来是18,446,744,073,709,600,000。我已经不知道这个数字怎么念出来了,所以就给你一个“准确的”数字,那就是很多很多。你觉得IPV6会用尽吗?我只能说世事无绝对,但是基本上我们这一代是不用操心这个问题了。估计你不需要学习IPV8了。
12 向左还是向右 - IP路由
我们上一小节了解了未来的这个钻石王老五IPV6,现在让我们回来继续了解当今还高高在上的IPV4。这就是理想很丰满,现实很骨感,IPV6固然好,但是现在还是IPV4的世界,所以我们还是要知己知彼。
子网的框架
我们先来看一下子网的框架。还是先看一个例子
1 | IP:203.0.113.10 |
我们前面是不是已经讲过或者说介绍过了子网掩码的问题。为了进行子网划分,我们必须首先转换为二进制。也许还有别的方法,但是我始终觉得二进制是解决这类问题的杀手锏。所以,当我们使用这些地址时,请切记我们要先转换为二进制。
1 | IP:11001011 00000000 01110001 00001010 |
我们现在来看的是一种新的表示方法。这个例子中255.255.255.0 你来算一下,实际上是前多少位作为网络地址。是前24位对不对,所以你可以写成/24。这样看上去是不是就简洁了很多,那写出来的样子就是203.0.113.10/24。这么酷炫的写法怎么会没有名字呢,它叫做无类域间路由。英文全称是Classless Inter-domain Routing,一般使用简写CIDR。
拆分子网到更小的网络
我们来看一个稍微复杂一点的实例。比如说你听了我的课之后,充满了信心,决定要自己开一个公司。而且还要开一个连锁企业,直接就在全国部署8个办公地点。北京,上海,重庆,天津,杭州,苏州,武汉以及云南(老师地理知识有限)。你去找ISP(互联网服务提供商)帮忙,他们分给了你一个IP的区段203.0.113.0/24。但是你需要8个网络地址,你怎么办呢?让我们来分析一下
1 | 203.0.113.0/24 这个是给你的 |
你需要的是8个网络对不对,你算一下2的几次方=8。结果是不是3,所以你需要3个bits就可以。说明什么问题,因为前24位是ISP给你的,你不可以变,所以你可以变得就是后8位,但是你又需要8个网络,所以你需要3个bits来帮助你划分,就是下面这样
1 | 11001011 00000000 01110001 000xxxxx |
既然是又多了3bits是固定的,那你是不是要使用/27来作为子网掩码了。小考题,如果需要10个网路,你怎么分? 好,我们继续来看,我们先看第一个网络11001011 00000000 01110001 000xxxxx
1 | Network 1 |
我再来带着你看下一个
1 | Network 2 |
所以以此类推,你的8个网络写出来是这个样子的。自己先练习一下
1 | Network 1 -> 203.0.113.0/27 |
那以上的网络怎么进行通信呢?通过路由器。
路由器的工作原理
什么是路由器呢?我从百度百科上copy了这个无聊的定义。(专业的事情交给专业的人来做)
无聊的定义
路由器是连接两个或多个网络的硬件设备,在网络间起网关的作用,是读取每一个数据包中的地址然后决定如何传送的专用智能性的网络设备。它能够理解不同的协议,例如某个局域网使用的以太网协议,因特网使用的TCP/IP协议。这样,路由器可以分析各种不同类型网络传来的数据包的目的地址,把非TCP/IP网络的地址转换成TCP/IP地址,或者反之;再根据选定的路由算法把各数据包按最佳路线传送到指定位置。所以路由器可以把非TCP/ IP网络连接到因特网上。
相信你和我一样,看完定义和没看一样,还是一头雾水,好,那怎么办呢?小实例走起,让你可以理解的更加透彻。假设我们现在有一个小的网络地址10.0.0.0/24。我们只需要把它拆分成两个网络,怎么拆呢?经过了上面的8个,这两个小意思吧。
1 | 10.0.0.0/24 |
好,我现在有了两个网络,他们之间怎么通信呢?这个就是路由器登场的时候了,左边的网络是10.0.0.0/25 中间是路由器,右边是10.0.0.128/25。你要做的就是把这两个网络地址放到路由器的两端,路由器的作用就是在网络间传输数据的。说白了路由器就是在里面有一个路由表,里面写好了这个通信是从哪里来到哪里去。
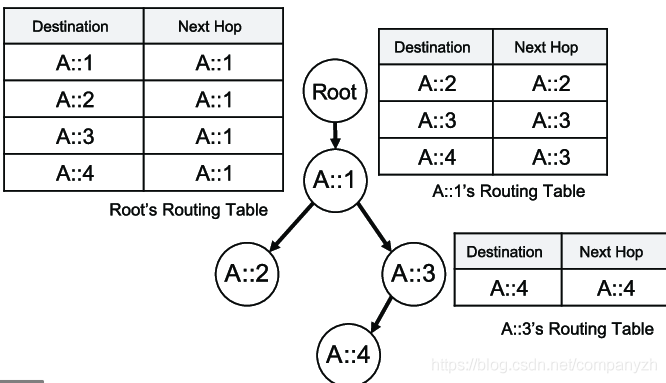
比如上面这个图,左边的这个表就是存在于Root里面,里面会记录上,不管你想去A::1,A::2,A::3,A::4。你的下一站都是A::1。 再来看一下右上角的那个路由表,这个表示存在于A::1中的。当你想去A::2的时候,下一站就是A::2,当你想去A::3和A::4时,下一站都是A::3。 自己看一下右下角那个表应该明白了吧。
因为你毕竟不是网络工程师,所以不太需要知道更多关于路由器的细节。上面这个图我都可以不用讲,但是不说,总感觉缺点什么。看到这里就可以了。给自己一个鼓励。你已经完成了IP部分的学习,其实很是包含很多东西的,如果你只是简单的看看,估计什么也没有学会,IP的学习还是要坐下来,用心的去思考,去计算。毕竟好记性不如烂笔头吗。
13 我能给你安全感 - TCP(一)
不知不觉我们已经来到了第四部分,这里我们会开始来详细的讲解TCP和UDP,也就是传输层部分。我们首先来看一下协议中的王者TCP。相信你最熟悉的就是三次握手了。
我们上一章详细讲解了IP,也就是第三层网络层的主要协议,现在我们开始看一下传输层的重要协议TCP。
TCP
TCP的全称是Transmission Control Protocol。这个协议的目的就是创建一个Session,通过这个Session来传输数据。
我们在数据链路层查看了源和目标Mac地址,并看到了这些Mac地址是使我们能够将流量从一台设备发送到其自己局域网中的另一台设备。我们又看了网络层,也就是IP,了解了网络层的地址如何使我们能够从一个网络上的一个设备与世界其他地方的另一个设备进行通信。现在又到了TCP,TCP所要做的就是允许我们在网络上的两个设备之间创建会话,然后通过这个会话来传输数据。
我们现在来看看它是如何工作的。TCP使用一种称为客户端服务器模型的东西。比如我有一台PC或一个客户端,和一个Web服务器。我的客户端被认为是客户,因为运行某一种Web浏览器比如Chrome或者FireFox。这个Web浏览器就是一个HTTP的客户端。(HTTP超文本传输协议是我们用于传输Web页面的协议)。在HTTP的服务端需要有完全不同的软件在运行,也就是我们说的服务器,服务器是有很多的选择,比如Apache是一个非常流行的开源Web服务器。当然还有老牌的微软IIS等等。现在这里要做的就是客户端看做是一个设备说“你能给我发送网站吗?”。服务器会回答说,给你,这是你要的网站”。但是我们使用的是倒叙模式,在我们能够做到这一点之前,我们必须在两方之间建立一个会话。
三次握手和四次挥手

通过我这个灵魂画手的画作,你应该可以看出三次握手的精髓,那就是客户端会先向服务器端发送一个SYN,然后服务器端会发送回一个SYN-ACK。(ACK一般表示收到)然后客户端会再回复一个ACK。经过了三次通信也就是三次握手之后,这才能建立起连接,说明双方都没有问题,可以开始唠嗑了。就好像我们之前的例子还是美国队长和黑寡妇姐姐唠嗑。聊完之后。不能突然就断开了吧。这样太没有礼貌了。所以需要经过一个流程也就是我们说的四次分手。这是一个非常优雅的过程。首先服务端会发一个FIN消息。然后客户端回一个FIN-ACK。然后客户端会发送一个自己的FIN 消息。然后服务器发送一个FIN-ACK。这样双方就终止了通信。就好像黑寡妇姐不想和美国队长说话了,她会说,我要去给绿巨人做饭了,BYE BYE,然后美国队长会说,好您了,收到。那我也去给小美队抱孙子去了(这是两条消息),黑寡妇说,好的,您快去吧。这样两人就挂断了通信。这样是不是很容易理解。当然4次分手不是唯一的断开的方式。还有一种方式叫做Reset。
我们把整个的通信过程退后两步来看。想象一下客户端只是向Web服务器询问该网页。服务器回应说,这是网页。现在可能发生的事情是,任何时候任何一端都可以发送TCP重置消息(reset)。为什么它会发送TCP重置消息而不执行四次分手呢?因为有时我们可能在PC和Web服务器之间安装了一个安全设备,如果网络中发现某些不应该在网络上传入和传出的内容(比如小电影,一不小心就飙车了,但是开车犯法呀,切记)。这些设备的安全措施可能会发送TCP重置。该设备通常被编程为发送TCP重置并仅关闭两个设备之间的通信,所以这种情况的发生是很不友好的。其中一端(在这种情况下可能是Web服务器)将发送TCP重置。一旦这个客户收到了RST,连接就会立即关闭。我们将无法再发送数据。哪端都可以发送这个RESET。任何时候都可以。完全取决于你使用的软件。还是看我们的例子。美国队长和黑寡妇聊天,但是呢黑寡妇的老公在另一个房间默默的拿起了电话在监听,这时候美国队长和志玲姐姐开个玩笑,你的内衣真好看。绿巨人觉得你怎么可以开车,和美国队长说了一句,你给我滚(RST),然后就挂断了。这样是不是更容易理解。(这些只是开玩笑的例子呀,不要当真,是为了加深你的理解,如果你是任何一位的粉丝,有冒犯到,我提前说个对不起呀)。

端口号
我们看传输层寻址之前再来穿插一下端口号(我的思维就是这么活跃)。
端口号的范围从0到65535,通过端口号被分为三个不同的类别。
- 公认端口(Well-Known)0-1023
- 注册端口(Registered)1024-49151
- 临时端口(Ephemeral)49152-65535
服务器端口号是为非常特定的服务器应用程序层协议设计的。客户端的这些临时端口号主要用于一个会话的临时时间段,然后可以将该端口号扔掉或放回池中,以后我们可能会也可能不会重复使用该端口号。这些客户端端口号将在我们网络上的不同TCP会话中重复使用。
你想一下,你所熟悉的公认端口号有哪些?
- HTTP - 80
- HTTPS - 443
- FTP - 20,21
- SSH - 22
- Telnet - 23
公认端口
这些端口已经存在很长时间了,是经过实践检验的协议,所以称为公认端口。诸如Http使用端口80,https(这是HTTP的加密版本,使用443)。FTP,出于不同的目的使用了两个不同的端口号,这使它使用起来有点麻烦和复杂,尤其是对于通过防火墙。SSH,使用端口22。Telnet使用端口23。当然还有很多就不一一列举了。
注册端口
然后是注册端口,它们可以是官方的也可以是非官方的。官方的意思就是该自定义应用程序的组织已经将使用的端口号注册到了Internet Assigned Numbers Authority(IANA)。比如微软的Microsoft Windows Internet Name Service (WINS)。它就是注册了端口号1512。还比如Cisco HSRP或者叫做Hot Standby Router Protocol注册了端口号1985。以及Microsoft Point-to-Point Tunneling Protocol (PPTP)点到点协议注册了1723。这三个例子都是正式注册的端口号。
还有另一种程序当然就是非官方的,比如游戏Civilization(文明)。使用的就是端口号2033。这意味着我们知道这个游戏将使用这个端口,但尚未正式注册。这是否意味着我们不能使用它了呢?当然不是。我们可以使用它。我们只需要知道某个特定的程序会使用它即可。
所有这些公认和注册的端口号会赋给应用层上的程序。服务器会监听这些端口号。
我们还是用例子来讲解。看下图。
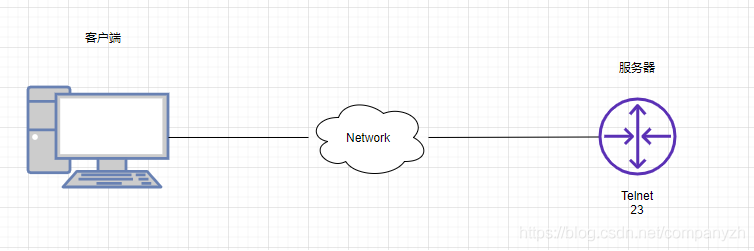
我有一个PC的服务端在左边,右边我放一个路由器,在这个路由器端,我配置的服务器是telnet,将路由器配置为服务器似乎有点奇怪。但是,在进行TCP通信时,请记住,我必须有一个设备作为客户端,而另一个设备必须是服务器。所以,为了使我的客户端可以Telnet到Router上,我必须在路由器上启用Telnet服务或者设置Telnet服务器。PC端我将使用我们熟悉的Putty作为客户端来访问。现在这个路由器一直在监听端口23,客户端将选择一些临时端口号(比如49160)用作其在传输层的源端口地址。我现在想将消息从客户端发送到服务端。我要使用源端口49160和目标端口23(代表Telnet)。这个时候需要做的是建立一个Segment也就是协议数据单元。
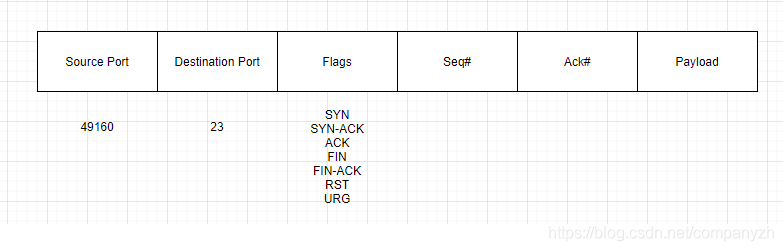
从上图可以看出,这个数据单元里包含一个源端口,一个目的端口,一些标志,一个序列号,一个确认号,然后是我们的有效负载。在那个标志的地方就是我们要发送的信息,还记得前面握手和分手时候发送的SYN,ACK等等吗?然后我们的客户端要发送这个给Router,其实协议数据单元只是包裹的一部分。看下图我们来认识一下,要发送的数据单元是什么样子。
而这个数据单元实际上只是包裹(Packet)的一部分。
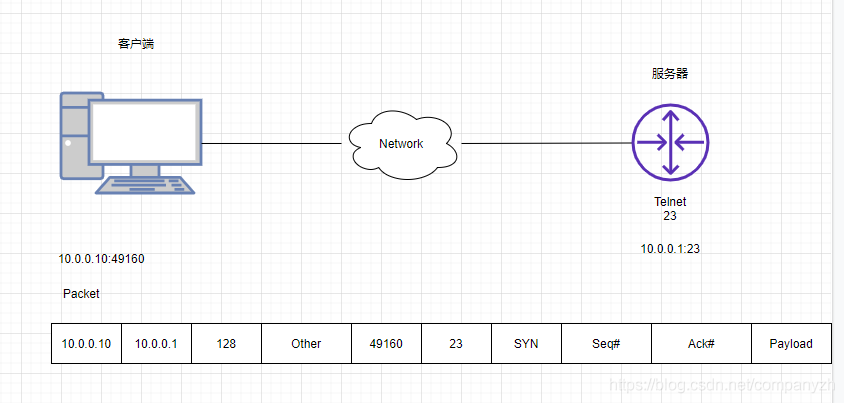
从图上你可能会注意到我使用的地址是10.0.0.10:49160和10.0.0.1:23这个就是我们所说的Socket,Socket就是IP地址和端口号的组合。我们下一步是要把我们的Packet做为一部分放到Frame里,然后发送出去。然后路由器也就是服务器那边会像剖洋葱一样,一层层的剖开,把Packet从Frame里取出,再把Segment从Packet里取出。然后再做出一个类似的动作,形成一个新的Segment,Packet,Frame然后再发送给客户端。。。这样是不是就形成了三次握手。然后就可以开始传输数据了。听我这么讲完,是不是不仅仅知道了三次握手,还知道了应该怎么握手,以及握手前有没有洗手。
14 我那不为人知的秘密是什么 - TCP(二)
我们之前学习IP的时候,就是把IP的header彻底的分析了一番是不是,既然我已经给自己挖了这个坑,就一定要把这个坑填好,我们现在来一起学习一下TCP的header。
TCP Header
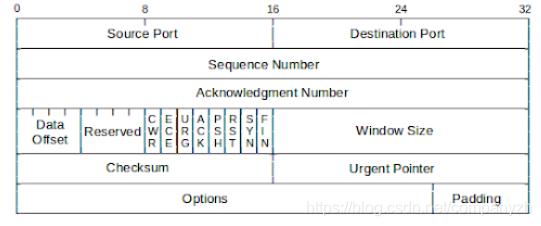
上图就是一个TCP Header的文件。我们还是一点点的来分析。 Source Port(源端口):源TCP的用户 Destination Port(目标端口):目标TCP 用户的端口 Sequence Number(序列号): 第一个数据字节的序列号(SYN标志除外)。如果设置了SYN,则此字段包含初始序列号(ISN)。下面的例子很严重依赖这个序列号,你想不明白都难。 Acknowledgment Number(确认号): 包含TCP期望接收的下一个数据的序列号。 Data Offset(数据偏移): 头中32位字的数量。 Reserved(保留): 为以后保留使用。 Flags(标识):这里有几种数值,我在下面扩展讲。 Window (窗口大小):TCP流量控制的一个手段,用来告诉对端TCP缓冲区还能容纳多少字节。 CheckSum(校验): 由发送方填充,接收方对报文段执行CRC算法以检验TCP报文段在传输中是否损坏。 Urgent Pointer(紧急指针):一个正的偏移量,它和序号段的值相加表示最后一个紧急数据的下一字节的序号,接收方可以通过此来知道有多少紧急的数据用过来。 Options + Padding:可选和填充项。
Flags
CWR:拥塞窗口减少标志 ECE: ECN响应标志被用来在TCP3次握手时表明一个TCP端是具备ECN功能的 URG: 紧急标志 ACK: 确认标志,还记得三次握手吗 RST: Reset连接,(看林志玲内衣的例子,我相信你一辈子都不会忘) SYN: 同步序列号 FIN: 发送方没有数据了,想想四次分手
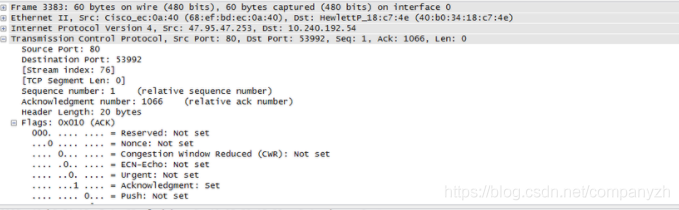
我们来看一下这个图,这个还是用wireshark抓下来的包,你可以从图上清楚的看到我们上面讲的TCP header都在实际的包中。
那背后无形的大手
我们现在开始进行更深层次的讨论,那就是TCP如何提供可靠的传输呢?简单的说就是使用序列号和确认号。
到目前为止,我们了解了三次握手以及握手背后的本质。其中包含SYN,SYN-ACK和ACK。然后建立连接开始通信。我们现在就来看一下通信是怎么实现的?比如说下面这个图 
客户端要从服务器获得这个精美的图片,但是图片太大,不可能一次性的发送,服务器要做的就是把它分割成几个部分。还记得我们之前看的那个Segment部分里的Payload吗?这个图片就可以放到那个部分。这个payload最大可以使用的容量是1460 bytes,所以你不能放超过这个限制的数据。我们之前的那个Segment里面是不是还有序列号和确认号。因为我们还没有发送或者接收任何的数据。所以我们可以给这个序列号为1。确认号也是1。序列号代表我发送的数据的第一个字节数。我还没有发送任何数据,所以最开始是1。我把这个图片分成固定的大小,比如说每一小部分就是250 bytes,那么我们上面说的最大容量是1460 bytes。所以我们可以在这个payload里面放五个图片分割之后的部分对不对。那就是1250 bytes,然后把这个Segment包装到Packet里,然后从服务器端发送到客户端。 然后客户端收到这个Packet,是不是要开始剖洋葱,把Packet打开,从Segment里面取出这5个分割的图片部分,然后组装这个图片。客户端这个时候已经收到了从1到1250字节的数据对不对。然后该到客户端操作了。
客户端也要开始构建自己的Segment了,这个Segment要确认收到了刚刚的1250 bytes的图片数据。这里要注意,客户端发送的这个序列号还是1,为什么呢?因为客户端还没有发送任何的数据给服务器对不对,所以序列号还是1。客户端可以发数据也可以不发数据,我们这里比较重要的是什么?是这个确认号,现在的确认号是1251。聪明的你会不会问为什么是1251不是1250,这里你要记住,这个确认号要永远比你接收到的最大的字节数加1,因为客户端收到了1-1250,之所以要发送回1251,是为了告诉服务器你现在可以发送1251这个字节后面的数据了。然后把这个Segment封装到Packet里,发送给服务器。
服务器收到之后,打开这个包裹,看到消息,说好的,你已经收到了1-1250,我现在开始发送1251,是不是又可以放5个图片的部分到payload,然后把序列号改成1251,确认号还是1,然后走你,再发送给客户端。
客户端这个时候还是重复上面的动作,拆开包裹,取出照片,组合收到的照片部分。也许你还很年轻,但是在大概1992年的时候下载图片其实就是这样,你会发现没有下载完的图片会一点点的展示,有的部分有,有的没有。当然我这里只是给你掰开了细细的讲。让你可以明白的更加透彻。这个时候客户端又要重新构建了,你自己想一下,这个确认号和序列号应该是什么,是不是序列号还是1,因为还是没有数据要发送给服务器,然后确认号这个时候是2501了吧。因为客户端已经收到了2500 bytes了。需要告诉服务器的是我要开始接收2501以后的字节了。
然后这个球又到了服务器这边了,我就不再讲的那么细致了,简写一下,就是现在的新Segment,是不是序列号变成2501了,确认号还是1。世界不可能永远那么美好。这个时候,当服务器把这个消息发给客户端的时候,由于某种原因,可能是哥斯拉入侵。这个消息弄丢了。世界末日了吗?当然不会。这个时候是TCP展现真正技术的时候了。我们来看一下TCP是如何解决这个问题的。
现在数据丢了,但是服务器还不知道这个消息是不是丢了,因为它只是发出去了一个消息,后面什么都不知道了。当然客户端也不知道发生了什么。因为客户端什么都没有收到。当然我们这里是放慢了100倍的来讲解,实际上,在现实中,如果一个packet丢失了,服务器那边可能已经开始发送新的Packet了,Anyway,我们继续我们这边的慢动作。服务器那边因为不知道发生了什么,又继续发了一个新的Packet,序列号是3751。当客户端收到这个包裹的时候,会放到对应的位置,但是问题来了。是不是缺少2501-3750这个部分。这个时候客户端会发送一个特殊的Segment,在FLAG部分,发送的是SACK也就是Selective ACK, 确认号是5001 2501-3750。这说明什么意思呢?这是告诉服务端,我收到了5000,但是2501-3750我没有收到。所以我需要5001之后的部分以及2501-3750这部分。客户端把这Segment打包好后发给服务器。
服务器收到了之后呢,自然表示很惊讶对不对,但是作为信誉极好的卖家来说,既然快递丢了,我已经重新发送,于是又重新构建了一个新的Segment包含2501-3750这部分的数据发送给客户端。不可能总是丢同一个包裹吗,这次就很正常的发送给了客户端。客户端收到了之后,就又开始拆包,组装。客户端知道应该要放到哪里,因为有序列号告诉客户端,这个数据要放到哪里。然后再发送会ACK的Segment,告诉服务器我现在需要5001以后的数据。然后发给服务器。
这个时候服务器把最后的部分都发送给了客户端,客户端也完美的拼接好了照片,但是客户端不知道已经完全发送完毕了。客户端会继续的发送说,我需要6251之后的数据。但是服务器端是知道数据已经全部发完了,所以服务器会发送一个Segment,其中的Flag部分是FIN。还记得这个吗?这个是要开始分手的标志了。当然这个时候Payload上什么数据都没有。然后就开始了分手流程。完成了四次分手。这个会话就结束了。当然客户端会给服务端一个五星好评呀。因为毕竟没有丢失数据吗。这就是一个TCP从建立,传输然后分手的全过程。这其中虽然发生了一点小意外,但是TCP凭借着出色的确认号和序列号机制保住了稳定传输这个称号。
希望你不要觉得我讲的很啰嗦。因为我是希望你能彻底的理解这个过程,还有文字的表达毕竟不如语言表达。总之还是希望读者可以彻底的理解和掌握这部分的知识。当然如果你去阿里面试的时候,千万不要把我这一篇原原本本的讲给面试官呀,不然面试官会听睡着,然后默默的和你开启四次分手了。好。希望你可以彻底明白。
15 不问收没收到,就问快不快 - UDP
我们前两小节学习了传输层的TCP,其实在同一层上存在着两名王者,另一位就是UDP。一山不容二虎,为什么在同一层需要TCP和UDP两个类似的协议呢?那他们的区别和优势又各是什么呢?
还是那句老话,存在即合理,我们之前讲的TCP在传输数据之前需要通过三次握手来确保稳定的连接,然后再开始传输数据,而UDP却不然。UDP是客户端说我需要数据ABC,服务器会直接发送过来,所以这个传输自然是没有任何的保证。他们之间没有任何的会话连接,只是说我需要数据,然后服务器就会给数据,就是这么简单,就是这么“美好”。所以这里没有三次握手,没有可靠的通信,没有序列号,没有确认号。UDP就是用于有效率的传输,当然大多数时候,你不需要选择,因为你没得选,比如HTTP,你只能使用TCP。
客户就是上帝,客户是怎么选择的
TCP和UDP作为传输层的两大支柱,选择权当然是在更上层的客户手里,也就是应用层。我们来看一下应用层是怎么抉择的。下面是一个列表
- HTTP
- HTTPS
- Telnet
- SSH
- FTP
- SFTP
- POP3
- IMAP
- SMTP
- DNS
- SNMP
- TFTP
通过列表的形式把这些表示层的协议列出来,让你看的更清楚一点。我们现在一起来看一下这些并应用程序层协议以是如何使用TCP或UDP的。这些名词可能有点抽象,因为你不会“直接使用”http或Telnet。通常,你打开浏览器并访问网站,所有这些事情都是在幕后发生的。这也是我们整个网络学习的重点,这样你就可以了解那些幕后不为人知的故事。我们来一起大致过一下这些协议。Http和https用于网络的传输。Telnet和SSH用于远程的连接。Telnet是没有加密的,SSH是加密的版本。FTP是文件传输协议和SFTP是安全文件传输协议。也是同一样东西的未加密和加密版本。POP3,IMAP,SMTP这三种协议是邮件相关协议。用于接收和发送邮件。POP3用于读取Email,SMTP用于发送邮件。IMAP是一种协议用于读取和发送邮件以及一些其他的功能。我们现在的现代邮箱系统,比如OUTLOOK和这个Gmail都是使用IMAP而不是POP3。然后这个DNS可以看做是我们的Internet电话簿。下面的这个SNMP全称是Simple Network management protocol,这个协议是用于收集有关我们网络上设备的信息,以填充监视服务器。最后TFTP叫做Trivial File Transfer Protocol,可以看做是FTP,它是用于传输小的文件和简单的传输。
以上的每一个协议,我们都赋予了一个传输层的端口,比如常见的HTTP是80,HTTPS是443。Telnet是23,SSH是22,FTP有两个端口,分别是20,21,SFTP是22。POP3使用110和995取决于不加密还是加密。同理IMAP 143端口用于不加密,993用于加密。SMTP 25用于不加密,587用于加密,DNS使用53,SNMP使用161, TFTP使用69。
这些协议不是使用TCP,就是UDP,或者是同时使用。
TCP
TCP基本上被以上大多数的协议所使用。TCP是非常常见的。基本上在DNS之前的所有的协议都是使用TCP。这不是由你来决定的,而是那些指定和编码这些协议的创作者决定的。他们选择的就是TCP。
UDP
DNS,SNMP和TFTP都是使用UDP,实际上DNS和SNMP既可以使用TCP也可以使用UDP。即使是这种情况,你还是没有选择权,那谁决定呢,一般来说是由协议的创建者,或者是去实现这个协议的编码人员来决定使用什么协议。基本上大多数的情况下DNS和SNMP都是使用UDP来进行通信。
不管你使用TCP还是UDP,在下一层都是IP,对不对
一句话来形容UDP那就是-UDP为我们提供了效率,这也是我们使用它的重要原因之一。TCP在使用中有太多的开销,当然这也取决于我们要完成的工作。还记得我们讲TCP的那个图像传输的例子的时候,TCP具有序列号和可靠通信的机制,我们可以通过TCP中的这些确认号来索取我们遗失的部分图像。但是在其他一些场景中,我们并不总是需要这些开销。DNS就是这个例子。
DNS是Domain Name System域名系统。可以看做是IP地址和名字对应的数据库。DNS拥有一个主机名或具有映射到IP地址的域名的主机名的数据库,以便我们可以访问 WWW.CSDN.net 并获取一些与之对应的IP地址,以便我们构建数据包和将信息发送到该网络上。
你现在只需要知道DNS就是当你想获取 www.csdn.net 的主机名,DNS为你提供它的IP地址。就像电话簿一样,当我们有一个人的名字并且我们尝试查找他的电话号码的时候。DNS使用UDP端口53来进行查找。这意味着当我的工作站将消息发送到网络上以查找CSDN的IP地址时,我们将使用UDP和端口53进行查找。让我们看看它是如何工作的。
- 你首先要使用 ping www.csdn.net,然后发送这个ping的消息,就好像说,嘿,CSDN的IP地址是多少,这个请求就会被发送给DNS。
- DNS服务器给你回复,嘿, CSDN的IP地址是8.8.8.8 通过UDP,你只需要这么两个消息,一个询问一个回答。问题就已经解决了。
如果你使用的是TCP呢? 假设你可以重写这个DNS的查找,你只允许使用TCP来完成这项工作。
- 客户端要先发SYN消息
- DNS服务器发回SYN-ACK消息
- 客户端又发送ACK消息
- 然后客户端发送,嘿,CSDN的IP地址是多少
- DNS服务器给你回复,嘿, CSDN的IP地址是8.8.8.8
- 然后关闭这个会话,客户端发送FIN消息
- DNS服务器发回FIN-ACK消息
- DNS服务器发另一个FIN消息
- 然后客户端发回FIN-ACK消息
你来对比一下TCP和UDP之前差了多少步。所以说要安全是有代价的。UDP只需要两个消息,而TCP需要9个消息。你也许会问,那如果使用UDP,这个DNS的查询消息丢失了怎么办?它可以发送另一个请求呀。即使是发送四次,一共也才8个消息吧。效率还是比TCP要高呀。所以不管什么技术没有完美的,要看你的场景和你PM的需求。
16 我为什么与众不同 - TCP高级篇(拥塞模型)
首先我们可以肯定的是TCP协议是可靠的。这就是我们前面讲的TCP知识。它是可靠地从网络上的一个端点到另一端点获取数据,但是它不希望使两者之间的网络不堪重负。TCP不想非常快的就开始发送数据,这样会导致拥塞和数据包丢失。同样,TCP也不想“欺负”其他的网络,把其他所有协议都淘汰掉,优先考虑自己的流量。因此,通过TCP拥塞控制,TCP能够确定网络上的拥塞并相应地调整其传输速率。
这可能与你想象的有一点不同。通常,我们开始传输该文件,并且我们想象的是,发送速度逐渐提高,并逐渐接近带宽。我们能够用吞吐量完全填满网络,并且该文件能够尽快通过链接传输。就像下图一样
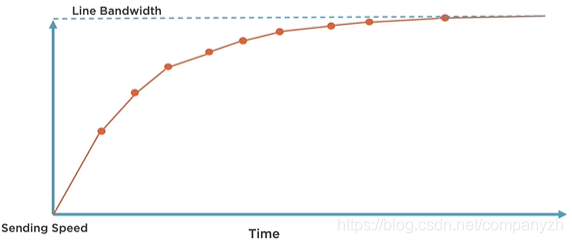
但是理想很丰满,现实很骨感。下图是在Wireshark的吞吐量图。
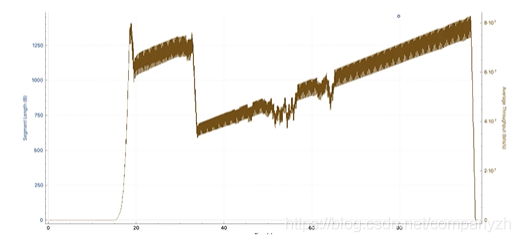
从图上可以看到吞吐量的变化。最初会上升,然后略有下降。它会先恢复一段时间,然后再次下降,然后随着时间的推移缓慢重建。因此现实是,TCP不会完全填充网络,当我们将文件从一个端点传输到另一个端点时。会有很多事情来控制。造成这种情况的原因是,TCP被设计为在端点之间具有不可预测的网络的情况下非常智能,现实也确实如此。今天,我们正在处理无线,高延迟,高损耗,多路径,高拥塞的情况。因此,这两个端点需要确定它们之间网络中正在发生的事情,并尽其最大可能地填充它,并以最有效的方式将数据从A点移动到B点。而TCP正是通过拥塞机制来进行控制的。这也是为什么它很重要的原因。
拥塞窗口
让我们想象一下,在客户端,我们有一个大小限制为65535的TCP接收窗口。那么,无论中间的网络大小如何,发送方都只能一次将65535放到网络中传输。现在,如果我们不传输大量数据或处于非常低的延迟环境中(例如端点之间为1毫秒),则接收窗口可能是足够的。但是,如果我们试图通过高延迟的链接来传送大量数据,窗口接收的数据量也不会减少。但是无论哪种方式,发送者都受到接收窗口的限制。这是拥塞窗口起作用的地方。
让我们想象一下,客户端的接收窗口现在大大增加到1GB。那么使用的是1GB的接收窗口。客户端很自信的堆服务器说:“嘿,服务器,给我你所有的东西,我能处理。你最多可以发送1GB的未确认数据。但是在这里发件人需要做出决定,也就是思考一下。在引起拥塞问题之前,它将在网络上发送多少,是1GB吗还是512MB还是10Kb?该服务器知道还有其他TCP连接和使用。它知道并非所有链接都相同。因此,该服务器不知道中间是哪种网络。我们有穿越海洋的T1连接吗?这两个端点之间是否有卫星连接?还是说客户端只是一个交换机端口?所以最开始的时候,服务器不知道一次发送多少,并且它不希望引起流量问题并引起争用和拥塞,这将导致数据包丢失。因此,该服务器可以传输的数据量是拥塞窗口或接收窗口的最小值。哪个值较小,就使用哪个值。我们的这个例子,接收器有很大很大的接收窗口。除非我们之间有一个非常非常牢固的网络,否则我们不可能在拥塞窗口实现这一目标。这里变得有些意思了。TCP接收窗口的大小会在TCP的头中。还记得上一节讲的TCP Header中有一个Window Size吗?

因此,当工作站发送确认甚至数据包时,它总是会告诉你必须使用多少窗口大小。在上面照片中,可以看到实际的真实窗口大小值为262,但由于我们使用的是窗口缩放,所以实际上是一个更大的值。在这里我们可以看到对方可以一次发送33536。这个不是问题,因为我们在接收缓冲区中可以拥有的数据量。我们永远不会在包头中看到它。实际上,挖掘并找出实际值是什么,几乎是不可能的。原因之一是因为这个数字一直在变。TCP总是增加拥塞窗口或减少拥塞窗口,这取决于它从网络之间确定的结果。因此,我们能做的最好的就是查看该拥塞窗口,并确定这是吞吐量缓慢问题的根本原因吗?
拥塞算法
我们知道了拥塞控制机制是什么,让我们一起来看一些算法及其工作原理。TCP拥塞控制机制决定发送方如何使用网络上的带宽。还可以决定该设备遇到丢失或高延迟时将退后并恢复的速度。现在让我们来看一些拥塞控制算法的名字?也许你以前听说过其中一些。比如vegas,Reno,NewReno,CUBIC等等。有很多不同的算法。随着时间的流逝和网络的变化,我们发现它们已经经过调整和优化,可以在不同类型的网络上更好地运行。例如,当网络具有更高的带宽和更高的延迟(跨过海洋下面的40GB连接通道)时,我们开始意识到需要对TCP发送算法进行更改,可能需要使它们更具“攻击性”,而不必仅仅因为丢失一个数据包就减缓传输的速度。同样,一些常见的拥塞控制算法,取决于操作系统,使用的TCP版本,安装的补丁程序,这些都会对使用哪种算法产生影响。我们来更深入地了解一下这些算法为何不同。
聊这些算法之前,你自己先想一下都需要考虑什么?第一个想到的核心组成部分是不是初始窗口大小(这个是不是很重要,小了,会慢,大了,会丢失)。初始窗口就是发送方在传输文件时立即发出的完整MSS(Maximum segment size)数据包的大小。假设我们的服务器使用的是非常保守的拥塞控制机制,它一次只发送两个全尺寸数据包。在发送更多数据之前,它会等待这些数据包的确认返回,返回后,将可以继续发送更多内容。初始窗口大小的决定,网络上发出了多少个数据包,这些都取决于拥塞控制机制的使用。
比如在NewReno的某些实现中,开始的窗口大小是四个MSS大小的数据包,这是初始窗口设置。在许多CUBIC算法的实现中,使用10个MSS作为初始窗口。初始窗口是拥塞算法的核心,这表示的是最开始发送多少数据包。
拥塞机制的另一个核心组件是慢启动。什么意思呢?就是我们的服务器,它发送两个完整的MSS到客户端,然后从客户端收到确认,整个过程很顺畅。然后再测量一下在发送数据和接收确认之间的等待时间,服务器会认为整个流程没有问题。之后服务器会将下次发送的MSS数量翻倍,,它将在下一次发送四个MSS,然后等待这些确认返回。重复上面流程,如果还是很顺畅,会继续的将发出的数据包数量加倍。这是一种常见的机制,你会在Reno和NewReno等一些较旧的算法中看到这种机制。

慢启动
我们来详细看一下慢启动的过程。

在我们的图表中,我们可以看到,时间是底部X轴表示往返时间,Y轴表示发送包的数量。发送站通过发送两个完整的MSS来启动。它等待第一次网络往返的确认返回,然后将拥塞窗口加倍,接下来将为第二次往返发送四个MSS。如果这些都出去了,那么认为没有任何问题,那么我们将再次加倍,第三次网络往返传输将获得8个MSS。如果所有这些都被成功接收,并且我们收到了很好的回覆,继续再次加倍。现在,在某个时候,根据算法以及该算法能够从网络中确定的延迟时间,该算法将设置一个慢启动阈值(图中的1),这意味着你可以将网络上现有的MSS数量加倍直到碰到这一点。在这种情况下,我们说该数量为16。在那之后,我们从慢启动机制更改为避免拥塞机制。这就是说,对于每个网络往返,我们将只添加一个,而不是将网络上的MSS数量加倍。因此,对于第五次网络往返,我们将有17个MSS(也就是16 + 1)。对于第6次网络往返,我们将有18个MSS(17 + 1),这将缓慢增加拥塞窗口,直到遇到丢包或拥塞为止(图中的2)。当我们遇到超时或发送数据包却没有收到响应时会发生什么?这时候,大多数拥塞控制算法所采用的是让步。(在较早的日子里,这个数字实际上会回到一半)。将拥堵窗口缩小一半(图3),然后从慢启动重新开始,直到再次达到慢启动阈值。但是,随着时间的流逝,网络连接的带宽不断提高,在某些情况下,延迟也有所增加,这种倍增的后退策略有点激进了。就像我们在这里看到的那样,仅由于遇到单个数据包丢失,我们就损失一半的吞吐量。
 因此,为了解决此问题,使用了另一个核心组件那就是-快速恢复。快速恢复可以帮助我们做的是,我们从拥挤窗口中的那个高点退回,但并不是一半的腰斩。而是退后一点然后再慢慢重建。
因此,为了解决此问题,使用了另一个核心组件那就是-快速恢复。快速恢复可以帮助我们做的是,我们从拥挤窗口中的那个高点退回,但并不是一半的腰斩。而是退后一点然后再慢慢重建。
我们前面提到了,使用哪种拥塞控制算法取决了很多事情?初始窗口,最初发出了多少个MSS?是否使用慢启动机制,还是快速启动?慢启动阈值如何设置?什么时候开始避免拥堵?是否使用快速恢复?还是如果遇到一些损失,会重新回到慢速启动?我们是否只会在看到数据包丢失的情况下才后退,还是等待时间的变化会导致我们放慢速度?所有这些都取决于你所使用的TCP算法,并且它们都是不同的。让我们来看一些常见的拥塞算法及其独特之处。
- NewReno是你可能听说过的一种,在2000年代,它非常流行,许多不同的系统都在使用它。现在NewReno还在使用,但是在长肥网络(LFN,long fat network)上它的性能很差(比如海底隧道这种网络)。如果你通过跨海洋的10GB连接发送文件,但效果不佳,则可能需要进行调查是否使用了NewReno。
- CTCP - 这是Windows Server 2003和Windows 7上的默认拥塞控制机制。
- CUBIC - 是在Windows 10和MacBooks上默认使用的。原因之一是因为它在长肥网络中效果非常好。它可以快速建立其拥塞窗口,并且不会非常迅速地退后。如果看到丢失的数据包,它不会退缩到一半。
- Westwood - 你不是经常能看到这种机制,它是专为处理有损网络而设计的。
- 最后是BBR - 这是Google专门开发的;它可以在大多数服务器中使用,并且你还可以在Linux操作系统上进行实验。
拥塞检测机制
TCP如何知道出现问题并相应的退出其拥塞窗口?决定拥塞算法退避的主要方法有两种
- 第一种是丢包。因此,在这里我们可以看到服务器发送了两个数据包,并且得到了很好的确认。然后发出四个数据包,其中一个数据包丢失。这就是说,我试过发出四个,但是效果不好,既然这样我就坚持每次网络往返都使用2MSS。
- 另一种拥塞检测机制是测量延时。服务器发送了几个数据包。就好像短跑比赛一样,这时候按下启动秒表。当看到这些数据包的确认返回时,便可以停止该秒表并测量延迟。该等待时间(延迟)不应该有显着变化。通常,仅当某处的链接出现拥塞时,它才会发生变化。让我们再想象一下,该服务器发送了几个数据包,但是这次要花费更多的时间才能从客户端取回确认。说明什么问题?是不是说明发生了拥堵。
拥塞机制可以算是TCP比较高级一点的知识,希望你能对TCP的知识有了一个更深层次的理解。
17 来,先看看我的家谱 - HTTP的身世
我们今天开始来看一个重中之重的话题,那就是HTTP。开始我们的话题之前,不知道你面试的时候有没有遇到过HTTP的问题呀。我们先来自我检测一下,下面的这些题你都能回答上来吗?
- Http与Https的区别?
- URI和URL的区别?
- HTTP方法有哪些?
- 一次完整的HTTP请求所经历。
- 常见的HTTP相应状态码。
什么是HTTP?
http是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。
题外话->我面试阿里的时候呢, 就被问到了知不知道HTTP2. 当时呢回答了,但是之后想了一下. 感觉这个是一个既深入又不深入的话题. 说不深入呢, 无非就是一个协议吗, protocol,对不对?深入呢, 就是我们接下来要探讨的东西。我们不仅要讨论什么是HTTP, 还要讨论对我们工程师来说不管是建网站呀, 还是应用或者是对API都有什么影响。可能有的同学根本就不知道有这个http/1.1,http/2或者说http/3的. 就是说你只是知道http, 但是不知道还分这个1,2,3。
HTTP的成长史
早在 HTTP 建立之初,主要就是为了将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。也是说对于前端来说,我们所写的HTML页面将要放在我们的 web 服务器上,用户端通过浏览器访问url地址来获取网页的显示内容,但是到了 WEB2.0 以来,我们的页面变得复杂,不仅仅单纯的是一些简单的文字和图片,同时我们的 HTML 页面有了 CSS,Javascript,来丰富我们的页面展示,当AJAX的出现,我们又多了一种向服务器端获取数据的方法,这些其实都是基于HTTP协议的。同样到了移动互联网时代,我们页面可以跑在手机端浏览器里面,但是和PC相比,手机端的网络情况更加复杂,这使得我们开始了不得不对 HTTP 进行深入理解并不断优化过程中.
HTTP重要里程碑的时间点
- Http0.9 -> 1991
- Http1.0 ->1996
- Http 1.1 -> 1999
- Http2 -> 2015
Ok。世界在进步, HTTP也在进步, 大家第一次接触网络的时候是什么时候还记得吗?Amazon和yahoo大家知道吧。现在他们这个网站华丽呼哨的, 最早的时候是什么样子你们知道吗, 看看这两个图片。
就是这样. 就是几个名字, 几个链接, 再来几张图片(不知道如果现在Amazon还是这个首页的话,我会愿不愿意加入), 如果大家现在能够穿越回去, 那你简直就是大拿呀, 神一样的存在。(题外话->顺便推荐一下back to future这个电影呀)。
是不是你点一个图片链接,就跳到另一个类似的网页。如果幸运的话, 给你几张画。你就美的屁颠屁颠的了,所以那个时候没有太多和用户交互的东西, 顶多就有一个search box对吧。当然那时候网速也差, 我记得我当年上网用那个”猫”,连续下载了两天,就不告诉你下什么了。我家亲戚打不进来电话,那个着急呀. 那个时候的网速是多少知道吗,9600 bits per second,56k。这还算是奢侈的。
1998年有一个大神叫这个nielsen 发表了这个尼尔森定律(高端用户带宽将以平均每年50%的增幅增长,每21个月带宽速率将增长一倍)和这个摩尔定律差不多。
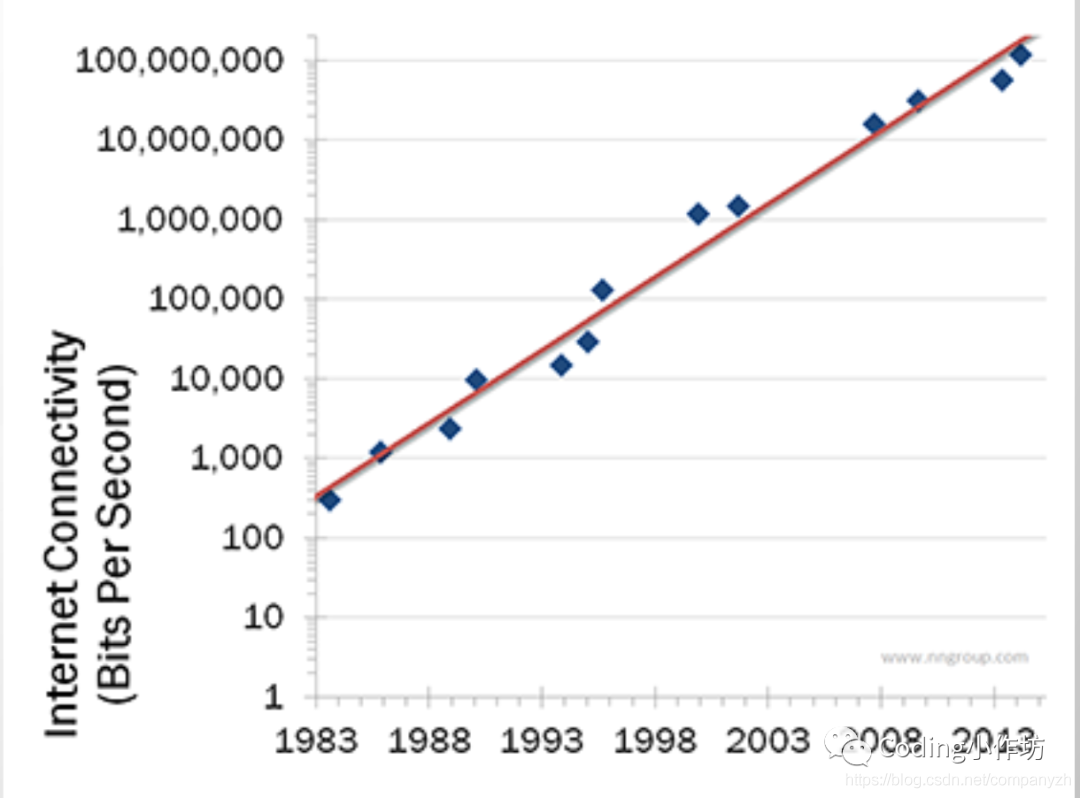
但是他这个呢是说网速的bandwidth,就是带宽。从1983到2014吧-差不多满足他的预测。后来又有了手机上网, 光纤就打破了他的预测。我们家的好像是500m的吧。所以我能同时看这个netflix还能同时下载。当然网民也从这个1993年的2亿5千万到现在不知道几十亿了。大家猜猜哪个国家的网速是最快的(中国台湾)? Ok. 言归正传呀, 如果网络世界这么美好的话,为什么需要HTTP/2. 跟他有什么关系。
如果一个现成的协议已经用了二十多年为什么需要一个新的协议。为什么要去修复他呢, 对吧。老话说的话,存在即合理,没坏就被碰, 这是我的老话呀。所以我们要问的是, 有什么问题 -> what is the problem?大家猜一下。1996的时候有一个人, 写了一篇论文就这个”It’s the latency, stupid” 愚蠢的延迟。这个人解释说我们面临的最大问题不是带宽而是延迟。为了让大家更好的理解一下,我给大家解释一下什么是带宽, 什么是延迟。
带宽
带宽是在被用来描述信道时,带宽是指能够有效通过该信道的信号的最大频带宽度。
延迟
延迟是在传输介质中传输所用的时间,即从报文开始进入网络到它开始离开网络之间的时间。
通俗点就是说一条高速公路,带宽表示的是有几条车道。延迟就是走过某段距离所花费的时间,当然影响的因素很多比如限速, 是否拥挤等等。对于我们的网络世界呢, 现在有两个因素。一个是页面的容量,现在都讲究这个富(rich)客户端。一页都几mb甚至几十的都有。这个必然会延长加载时间。如果你仔细观察的话,你就会发现很多这些内容吧,还不是你想看的,而是广告。我们花费了很多的带宽就下载广告。但是这就是现在的互联网没办法。
Ok,另一个更大的因素是什么-Latency,Latency是有限的。他是受到光速的限制的。这就意味着在一个真空的环境下, 没有任何干扰,基本上80-200ms可以从A -> B。Latency会影响你的load time也就是加载。你增加你的带宽, 加载的时间会按比例的缩小。但是当你加到某一个速度的时候, 你会发现增加带宽对于减小加载的影响会越来越小。比如1mb的网速, 加载一个页面需要3秒, 5m->1.5秒,10m-> 1.3秒。加载速度会影响这个用户的行为。如果一个页面加载时间过长,用户会放弃加载,失去兴趣。Amazon发现100ms的延迟会失去1%的用户。1s的延迟会失去7%的用户,想象一下如果你是在cart and checkout就是这个购物车-结算组,你把这个latency减少了一秒。用户增加了7%,意味着什么?意味着你可以为公司带来更高的收入,给你们组分红,给你升职,出任ceo,赢取白富美。因为你做到了, 别人没做到呀。(有点想的太美啦)
为什么现在的网页会有这个问题呢?以前的网页是什么, html和这个文字附带连接,就是一个请求。外部的文件比如css,js很少。现在呢,大量的连接,有些还需要从第三方去下载。所以一个请求添加了多个请求。一个典型的报纸的首页会有400个请求,是不是很可怕。如果你在放大的去看某一个请求,你会发现这个请求会被分成不同的区域有着不同的时间,你可以看到这个队列时间,DNS查找时间, 最初的连接,下载等等。
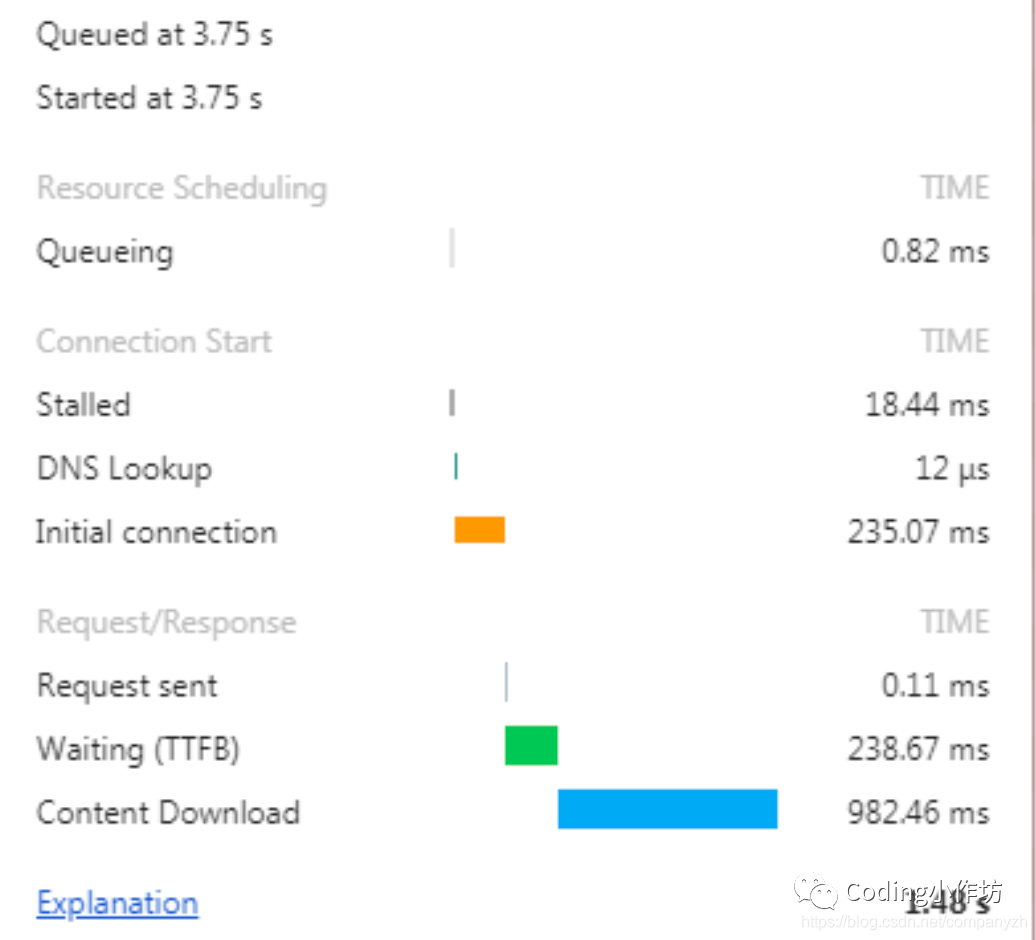
其实你要是明白这个网络模型的话, 这个问题其实是TCP的问题(你是不是心想,TCP咱熟呀,HTTP和TCP这两哥俩有啥关系)。看这个TCP/IP 模型呀。从上到下是应用层,传输层,网络层,链路层和物理层。所有的传输在传输层, 在这里就是TCP。一个简短的例子,发送一段简单的文字, 然后返回。首先是TCP连接也就是所谓的三次握手。基本上客户端先发一个sync(Synchronization packet)给服务器。然后服务器发送sync-ack(Synchronization Acknowledgment)也就是表示收到,然后再发一个sync。Client在回一个ack表示我也收到了。这个连接就算完成了, 然后开始发送请求, 收到回复。你会发现这段连接没有任何的实际数据,可是全程需要一段时间,比如94ms(我上次测试的一个数据)。连接建立就需要90ms,是不是很浪费时间, 这还不算完,TCP关闭同样需要四次分手。(之前讲过的内容呀,忘了的同学,回去再看一下)
最初91年的时候当HTTP/0.9出现的时候, 一个请求回复。很简单, 没有所谓的头信息什么的,就是内容。一个请求就是建立TCP连接,传送, 关闭TCP。HTTP/1.0的时候,引入了头信息,但是也不多。整个过程也还是这么简单。HTTP/1.1的时候呢加入了几个新的特点。
HTTP1.1的特点
- 提供了更多选择的缓存头来控制缓存策略。
- 带宽优化及网络连接的使用。HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址。因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
- 最重要的是长连接,有一个叫做Connection的信息,默认设置为keep-alive。就是说可以用一个连接来传送多个请求和回复。不需要打开,传,关闭,打开,传,关闭,而是可以在一个TCP连接里,做多次传输,然而这个并没有完全解决TCP“浪费时间”的问题对不对, 还是需要打开和关闭一次。
- 错误通知的管理: 在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除 大家知道哪些状态码。
常见的状态码
以下的状态码是需要你背诵全文的。
比如
- 200, 201(成功请求并创建了新的资源)
- 202(已经接受请求,但未处理完成)
- 400 (客户端请求的语法错误,服务器无法理解)
- 401(Unauthorized) 请求要求用户的身份认证
- 403(Forbidden) 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404(服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面
- 500(服务器内部错误,无法完成请求)
18 我都这么成功了,你却说我不行 - HTTP 的特点和缺点
上一小节我们做了这个关于HTTP的介绍。那我们今天来看一下, 到底HTTP有什么缺点, 我们必须要把这个功不可没的元老换掉呢。
队头阻塞(Head-of-line blocking) :
你想这么一个场景呀。客户发了Data1,回复收到,然后发了Data2, 但是丢了, 客户端这边不会等呀, 继续发Data3,但是server这边收到了Data3,却没有Data2,就苦苦的等呀等。直到收到了Data2,发ack2给客户端, 才会继续。所以在server这边,这个就会增加时间。也就是不能给他的应用层发送任何消息,直到排好序。请求好像瀑布模式,之前的请求会阻拦后面的请求。
HTTP1.1还记得吗,在持久连接的基础上,进一步地支持在持久连接上使用管道化(pipelining)特性。管道化允许客户端在已发送的请求收到服务端的响应之前发送下一个请求,借此来减少等待时间提高吞吐。如果多个请求能在同一个TCP请求发送的话,还能提高网络利用率。但是因为HTTP管道化本身可能会导致队头阻塞的问题,以及一些其他的原因,现代浏览器默认都关闭了管道化。
流量控制 Flow control
另一个TCP影响HTTP的问题是Flow control也就是流量控制,用于处理拥塞。如果有两台挨着的电脑连接100m的网,可以开始传送100m来回,没有任何问题。如果这个服务器不能处理100m就要降到50m,但是如果提前知道,这个也没问题,我们可以设置成50m。但是现实世界是,我们没有两个互联的电脑对吧。成千上万的电脑,路由,交换器以及各种机器。每一个机器都有他自己的限制。如果一开始设置一个特别高的速率的话,会造成拥挤, 阻塞网络。如果速率低的话,又会没有效率,TCP处理的方法就是流量控制flow control(就是我们TCP章节讲解的拥塞机制),意思就是可以根据网络的反应来不断的条件传输速率,TCP的实现方法是慢启动, 选一个很小的window size,然后增加。如果开始产生不良反应,降低。这个慢启动会影响所有TCP连接和每一个http请求。所以TCP为了保证可靠并且能够处理拥塞。TCP给HTTP带来了一系列的影响也就是延迟。终于我们的主角HTTP2该出来拯救世界了? 还没有. 主角上场之前, 都会有很多其他的小罗罗对吧。
SPDY就是这样一个产物
SPYD

2012年Google如一声惊雷一样提出了SPDY的方案,优化了HTTP1.X的请求延迟,解决了HTTP1.X的安全性,具体如下:
- 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个TCP连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
- 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- Header压缩。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
- 服务端推送(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。
SPDY构成图

但是大佬们能让你Google独大吗, 于是基于SPDY发表了升级版也就是我们的HTTP2。 HTTP2.0和SPDY的区别
- HTTP2.0 支持明文HTTP传输,而SPDY强制使用HTTPS
- HTTP2.0 消息头的压缩算法采用HPACK而非SPDY采用的DEFLATE - http://zh.wikipedia.org/wiki/DEFLATE。
Http2是一个二进制协议。二进制肯定比这个文本要好传输呀。它呢保持Http1.1里面的所有语义,比如Http1.x里面定义的所有头文件,资源等等。所有的工作都是用来解决Http1的缺点。如果通俗的讲,Http2是关于什么的?, 它是关于performance的。
下面说一个小的知识点呀

你知道SPDY,这个是google自己研发的解决http1.x的效率问题的协议对不对。后来Http2就出来了,Google就放弃使用SPDY了,是一个类似但是不一样的协议呀,现在这个协议已经不用了,Chrome在2016年就已经不用了。http2是15年正式发布的。

从上图,你可以查看浏览器的哪个版本支持HTTP2。你仔细看一下,基本已经都支持了,很多网站也都声称实现了Http2。
HTTP2
我们来深入看一下Http2。
Http1.1中,使用明文发送请求,拿到回复
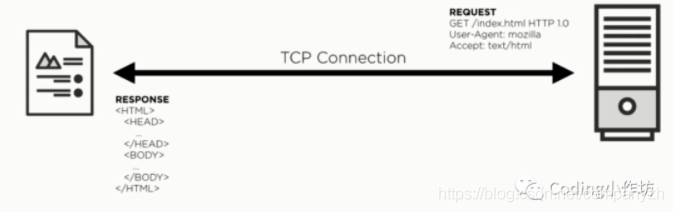
HTTP2中可以看出,使用的是二进制,但是内容必须和http1.1包含的内容是一样的,Verb(请求方法,知道有几种吗?9种,分别是GET,HEAD,POST,PUT,DELETE,CONNECT,OPTIONS,TRACE,PATCH),Resource(资源)以及其他的头文件等等。同样回复中也包含相同的内容,唯一的区别就是从明文变成了二进制。Http2和http1.1是不兼容的。但是我们需要Http2可以在现在的www的架构上运行,我们不可能把几十年创建的架构, 网络全部重建。如果Http2不能在现有的url上工作,那就是一场噩梦呀。所以这就是Http2必须能在http1的基础上工作。
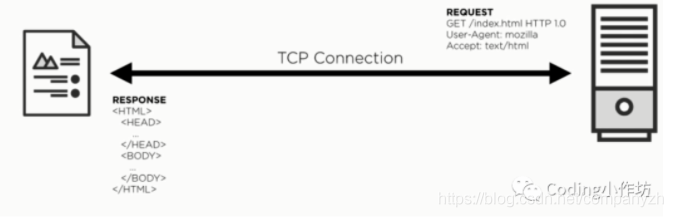
为了在Http2使用明文, 客户端需要发一个升级请求包含在头信息-> h2c。如果服务器支持http2,它会返回101表示换协议。返回信息,升级h2c。如果服务器不支持连接升级,会返回200或者404的状态码。
Frame(桢) 是HTTP2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流。
流->已建立的连接上的双向字节流。
• 消息-> 与逻辑消息对应的完整的一系列数据帧。
19 我老了,让我儿子来吧 - HTTP2
上一小节我们讲了HTTP1的缺点以及简单的介绍了一下HTTP2。 这一小节,让我们来认识HTTP2多一点。
多向请求和响应(解决了http1.x的队列阻塞)
多向请求与响应在 HTTP 1.x中,如果客户端想发送多个并行的请求以及改进性能,那么必须使用多个TCP连接。这是HTTP 1.x交付模型的直接结果,该模型会保证每个连接每次只交付一个响应(多个响应必须排队)。更糟糕的是,这种模型也会导致队首阻塞,从而造成底层TCP连接的效率低下。HTTP 2.0中新的二进制分帧层突破了这些限制。客户端和服务器可以把HTTP消息分解为互不依赖的帧,然后乱序发送,最后再在另一端把它们重新组合起来。把HTTP消息分解为独立的帧,交错发送,然后在另一端重新组装是HTTP 2.0最重要的一项增强。事实上,这个机制在整个Web技术栈中引发了一系列连锁反应,从而带来巨大的性能提升。
- 可以并行交错地发送请求, 请求之间互不影响。
- 可以并行交错地发送响应, 响应之间互不干扰。
- 只使用一个连接即可并行发送多个请求和响应。
- 消除不必要的延迟,从而减少页面加载的时间。
- 不必再为绕过 HTTP 1.x限制而多做很多工作。
HTTP2.0多路复用有多好?
HTTP性能优化的关键并不在于高带宽, 而是低延迟。TCP连接会随着时间进行自我「调整」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度(还记得我们讲的TCP拥塞机制吗)。这种调整则被称为TCP慢启动。由于这种原因,让原本就具有突发性和短时性的HTTP连接变的十分低效。HTTP/2通过让所有数据流共用同一个连接,可以更有效地使用TCP连接,让高带宽也能真正的服务于 HTTP的性能提升。
请求优先级
把HTTP消息分解为很多独立的帧之后,就可以通过优化这些帧的交错和传输顺序,进一步提升性能。为了做到这一点,每个流都可以带有一个31比特的优先值:0表示最高优先级; 2的31次方-1表示最低优先级。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流,消息和帧。具体来讲,服务器可以根据流的优先级,控制资源分配(CPU、内存、带宽),而在响应数据准备好之后,优先将最高优先级的帧发送给客户端。
每个来源一个连接
有了新的分帧机制后,HTTP 2.0不再依赖多个TCP连接去实现多流并行了。现在每个数据流都拆分成很多帧。而这些帧可以交错,还可以分别优先级。于是,所有HTTP 2.0连接都是持久化的,而且客户端与服务器之间也只需要一个连接即可。每个来源一个连接显著减少了相关的资源占用:连接路径上的套接字管理工作量少了,内存占用少了,连接吞吐量大了。此外,从上到下所有层面上也都获得了相应的好处。
- 所有数据流的优先次序始终如一。
- 压缩上下文单一使得压缩效果更好。
- 由于TCP连接减少而使网络拥塞状况得以改观。
- 慢启动时间减少,拥塞和丢包恢复速度更快。
大多数HTTP连接的时间都很短,而且是突发性的。但TCP只在长时间连接传输大块数据时效率才最高。HTTP 2.0通过让所有数据流共用同一个连接,可以更有效地使用TCP连接。
流量控制
在同一个TCP连接上传输多个数据流,就意味着要共享带宽。标定数据流的优先级有助于按序交付,但只有优先级还不足以确定多个数据流或多个连接间的资源分配。为解决这个问题,HTTP 2.0为数据流和连接的流量控制提供了一个简单的机制:
- 流量控制基于每一跳进行,而非端到端的控制。
- 流量控制基于窗口更新帧进行,即接收方广播自己准备接收某个数据流的多少字节,以及对整个连接要接收多少字节。
- 流量控制窗口大小通过WINDOW_UPDATE 帧更新,这个字段指定了流ID和窗口大小递增值。
- 流量控制有方向性,即接收方可能根据自己的情况为每个流乃至整个连接设置任意窗口大小。
- 流量控制可以由接收方禁用,包括针对个别的流和针对整个流。
上面这个列表是不是让你想起了TCP流量控制? 如果是的话,恭喜你, 回答正确。这两个机制实际上是一样的。然而, 由于TCP流量控制不能对同一条HTTP 2.0连接内的多个流实施差异化策略,因此光有它自己是不够的。这正是HTTP 2.0流量控制机制出台的原因。
HTTP 2.0标准没有规定任何特定的算法、值,或者什么时候发送WINDOW_UPDATE帧。因此,实现可以选择自己的算法以匹配自己的应用场景,从而求得最佳性能。
服务器推送
这是HTTP 2.0新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源而无需客户端明确地请求。为什么需要这样一个机制呢?通常的Web应用都由几十个资源组成,客户端需要分析服务器提供的文档才能逐个找到它们。那为什么不让服务器提前就把这些资源推送给客户端,从而减少额外的时间延迟呢?服务器已经知道客户端下一步要请求什么资源了,这时候服务器推送即可派上用场。事实上,如果你在网页里嵌入过CSS、JavaScript,或者通过数据URI嵌入过其他资源,那你就已经亲身体验过服务器推送。HTTPS协商过程中有一个环节会使用ALPN(Application Layer Protocol Negotiation)发现和协商HTTP 2.0的支持情况。减少网络延迟是HTTP 2.0的关键条件,因此在建立HTTPS连接时一定会用到ALPN协商。
Header 压缩
在HTTP/1中,我们使用文本的形式传输header,在header携带cookie的情况下,可能每次都需要重复传输几百到几千的字节。为了减少这块的资源消耗并提升性能,HTTP/2对这些首部采取了压缩策略。HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;首部表在 HTTP/2 的连接存续期内始终存在,由客户端和服务器共同渐进地更新;每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值。

升级
那怎么升级呢?
前文说了HTTP2.0其实可以支持非HTTPS的,但是现在主流的浏览器像chrome,firefox表示还是只支持基于 TLS 部署的HTTP2.0协议,所以要想升级成HTTP2.0还是先升级HTTPS为好。 以nginx为例
nginx官方提供了两种方法,第一种是升级操作系统,第二种是从源码编译新版本的nginx,我们用第二种方法.当前nginx最新的稳定版本是1.18,在服务器上执行以下命令:
1 | wget http://nginx.org/download/nginx-1.18.0.tar.gz # 下载 |
configure的时候后面可以带参数,参数可以用原先老版本nginx的参数,包括安装路径之类的,这个可以通过执行nginx -V得到,使得新nginx的配置和老nginx一样。如果configure提示缺一些库的话就相应地做些安装,基本上就是它提示的库后面带上devel,如以下提示:
1 | ./configure: error: the Google perftools module requires the Google perftools |
展望未来 - HTTP/3

虽然HTTP/2解决了很多之前旧版本的问题,但是它还是存在一个巨大的问题,主要是底层支撑的TCP协议造成的。前面提到 HTTP/2 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。但当这个连接中出现了丢包的情况,那就会导致 HTTP/2 的表现情况反倒不如 HTTP/1了。
因为在出现丢包的情况下,整个TCP都要开始等待重传,也就导致了后面的所有数据都被阻塞了。但是对于 HTTP/1.1 来说,可以开启多个 TCP 连接,出现这种情况反到只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。
那么可能就会有人考虑到去修改TCP 协议,其实这已经是一件不可能完成的任务了。因为TCP存在的时间实在太长,已经充斥在各种设备中,并且这个协议是由操作系统实现的,更新起来不大现实。
基于这个原因,Google就另起炉灶搞了一个基于UDP协议的QUIC协议,并且使用在了HTTP/3上,HTTP/3之前名为HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3最大的改造就是使用了QUIC。
因为HTTP/3离我们相对还远一点。我们就不多说了。
20 稳重的大外甥 - HTTPS
我们前面在讲解HTTP1和HTTP2的时候,有意无意的提到过HTTPS。现在来认真的分析一下这位名正言顺的皇亲国戚。
Certificate Authorities
Certificate Authorities - 证书颁发机构(CA)是HTTPS能够实现安全通信的必要的基本组成部分。这些颁发的证书要加载到网站中,以便客户可以安全地进行通信。每次你通过HTTPS的连接来浏览网站时,该网站的拥有者都会使用颁发机构给的证书来验证其对该域名的所有权(这么好的事,怎么会是免费的呢?这个是需要花钱买的,比如GlobalSign这个公司就是卖Certificate的)。
让我给你举个CA的例子。让我们一起来看一下csdn的网站,如你所见,它是通过HTTPS提供的链接。
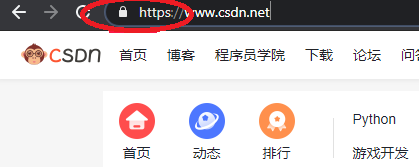
有挂锁,点击挂锁会有绿色的安全。
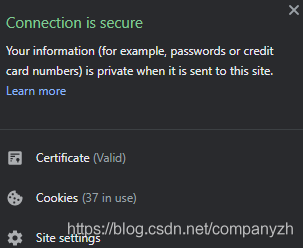
一切看起来都不错。让我们继续点击Certificate,看看谁颁发了证书。
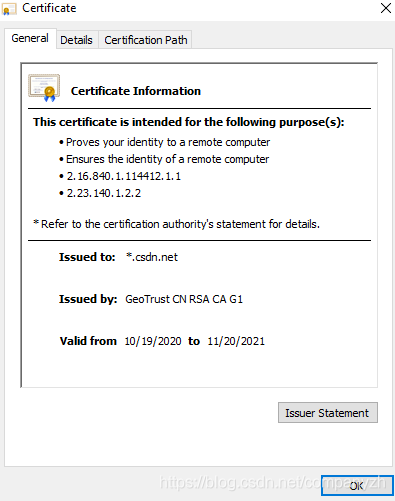
我们可以看到它是由GeoTrust颁发的证书。这是一种非常简单的方法,可以检查哪个CA向我颁发了安全通信的证书。就像刚刚的例子一样,很容易去检查谁颁发了证书。事实上CA很多,比如,GlobalSign,DigiCert,还有csdn使用的GeoTrust等等。那这种证书是怎么工作的呢?或者说怎么确保安全和不安全呢。
- 首先,你的机器要信任这些CA。
- CA签署证书。
- 从网站返回到浏览器后,你的计算机就会通过参考本地受信任的授权机构列表来验证证书是否合法。
我们来一起看看如何找到这个认证。按Windows + R来运行命令,然后输入certmgr.msc来打开应用程序。你能看到本地证书管理器。我们感兴趣的受信任的根证书颁发机构。如图。

是不是可以看到我刚刚举例的几个CA都在其中。我们可以在这里看到很多其他名称,其中一些可能是熟悉的,还有许多其他名称是不熟悉的。Windows也可以信任根据需要下载的其他CA。因此,不仅限于我们在此处列出的证书颁发机构。
此CA列表由Windows使用,由Internet Explorer使用,由Chrome使用。但Firefox不使用它(就是这么傲娇,你能咋地)。 Firefox管理自己的CA列表。感兴趣的话,你可以通过菜单,选项,高级,然后在此处的“证书”选项卡上,查看证书。这里我就不多讲了。
有时删除CA会导致使用该CA的任何网站提供服务的证书无效。比如一个机构颁发的证书安全性严重下降,这使攻击者可以欺诈性地为不受控制的域颁发证书。Microsoft可以立即将它们 从Windows和Firefox的证书颁发机构列表中删除,那他颁发的证书也就无效了。还记得第一步是什么吗?是你的计算机要和CA信任。所以成为CA承担着巨大的责任,如果不十分谨慎地履行其职责,后果可能很严重。所以,要点钱就要点钱吧。
SSL 和 TLS
探讨完了CA,我们来一起看一下SSL和TLS。它们在讨论HTTPS的时候,也是不可回避的话题。并且它们往往可以互换使用。例如,人们通常在说SSL时其实说的是TLS。让我们谈谈它们的实际含义以及背后的黑历史。
SSL
SSL的全称是Secure Sockets Layer也就是安全套接字层,它最初是由Netscape于90年代初期构建的。版本1. 0没有被外部使用,从版本2. 0开始也就是1995年开始问世。这确实是我们第一次开始在网络浏览器中大规模使用安全传输层。随后是第二年的版本3.0。这是SSL的最后一个主要版本。SSL确实存在了很长时间,直到2014年,当我们遭受POODLE攻击时,SSL才真正的寿终正寝(江湖上只流传着哥的传说)。
TLS
接下来让我们谈谈TLS。 TLS全称是Transport Layer Security(传输安全层)。1999年作为SSL3.0的升级版现身,它原本打算成为SSL的继任者,这也是关于这两个术语的第一个真正重要的观点。自本世纪初以来,TLS一直是网络上实现HTTPS的标准。 SSL停下了,TLS的时代开启了。版本1. 1于2006年问世,而版本1. 2则在此后2年问世也就是2008。2018年TLS 1.3上线了。随着这些新版本的发布,我们可以看到安全性和速度等方面的进步。它们继续使安全通信变得更强大,更快和更高效。
现在的挑战是,你在交流中总是会有两个参与者。对于HTTPS,通常会有一个浏览器和一个服务器。他们会协商使用哪种实现方式。例如,你可能有一台服务器,可以在任何地方实现TLS1.2。现在,如果客户端出现并说,我只能工作到TLS 1.1。则通信将回退到普遍支持的最高协议版本也就是1.1。
POODLE攻击后发生的重大变化之一是,开始完全取消对SSL支持。这是因为使POODLE如此有效的部分原因是,攻击者可以迫使通信从TLS降级为SSL,来完美的利用它的弱点。由于SSL至今已经深入我们的脑海,因此人们经常表示TLS时说SSL。这已经变得有点口语化了。例如,如果我要构建一个Web应用程序,并且我想强制应用程序使用安全连接,我设置了一个名为需要SSL的属性。现在,它根本不需要SSL,它需要HTTPS,并且使用TLS来实现。但是它仍然被称为SSL。
TLS 握手 – 怎么又握手呢?还有完吗
当客户端(例如浏览器)想要通过HTTPS连接到服务器时,它们会开始进行TLS握手。这是客户端和服务器需要相互协商并就如何安全通信达成一致的地方。此握手由客户端问候开始,并且在此请求中,客户端还会将例如它支持的最高级别的TLS和其他信息(比如受支持的密码套件)一起发送。然后,服务器将以服务器问候响应。并在响应中就协议版本和密码套件达成一致,并将其公钥提供回客户端。现在,客户可以根据其证书颁发机构列表来验证该公钥,在这里我们是为了验证我们是在和我们认为的这个服务器来交流。也就是她是我那个女神,不是什么抠脚大汉冒充的。(这里需要注意的一件事是,此初始通信尚未加密,这只是谈判阶段)。所以,中间的人可以看到客户端正在尝试与服务器通信,并且可以知道两者的身份。这段通讯还没有任何的内容;只是试图协商初始连接。客户端现在可以与服务器执行密钥交换,并且此响应使用服务器的公共加密密钥;服务器现在可以向其返回服务器完成的响应;这样便可以开始安全通信。当你基于HTTPS构建应用程序时,你要了解的一点是,这里存在一个协商,你可以看到哪个客户端和服务器正在互相交谈,并且一旦安全地建立了通信,那么请求和响应的内容就会被加密。举个例子,就好像看直播,美女问你要私聊吗,大家都知道是谁在和谁协商,一旦协商好,两人就去私密房了,至于干点啥就是保密的,你就不知道了。(我没有开车呀,不能是一起学网络协议吗?)。这就是TLS握手的过程。
返其道而行
赶紧拉上窗帘,我要在这里给大家介绍一个小网站,它就是badssl.com。
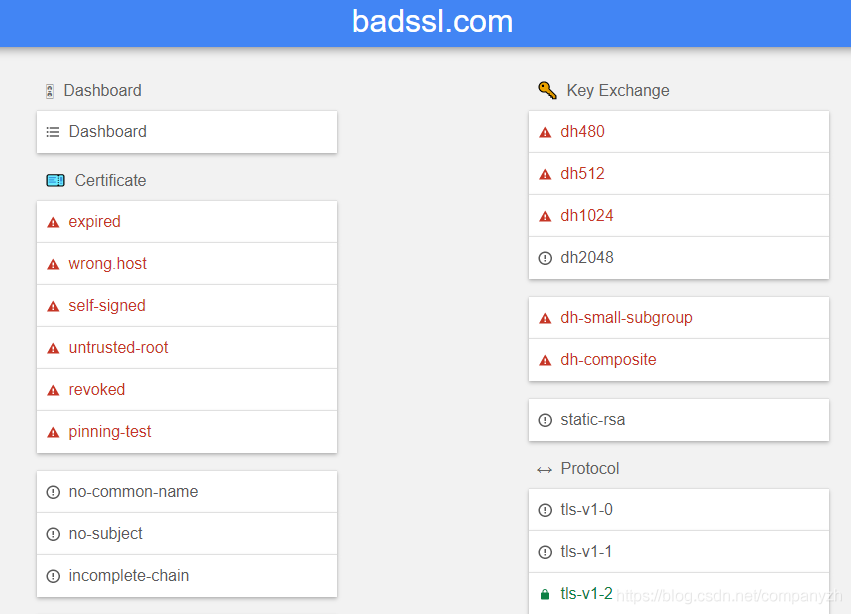
那这个神秘的网站是干什么的呢?它可以让您测试TLS的错误实现。因为这个网站说明了HTTPS可能出错的所有情况以及它在应用程序中的配置方式。比如,如果你向具有过期证书的网站发出HTTPS请求,该怎么办?
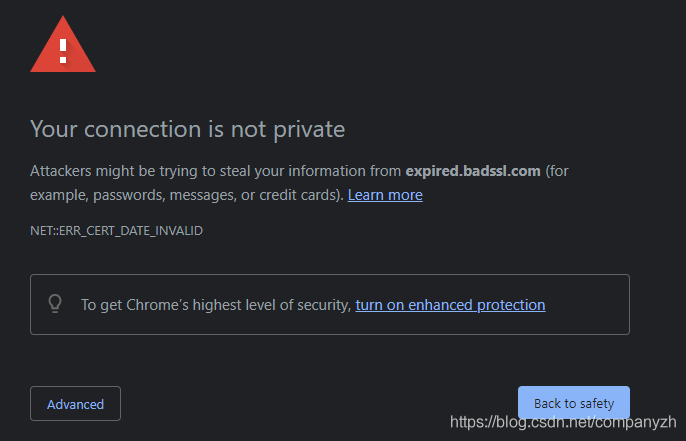
如图所示,Chrome会给一个非常明显的警告。这正是我们所期望的。你可以通过Inspect然后点击Security来查看这个证书。
下图就是这个证书
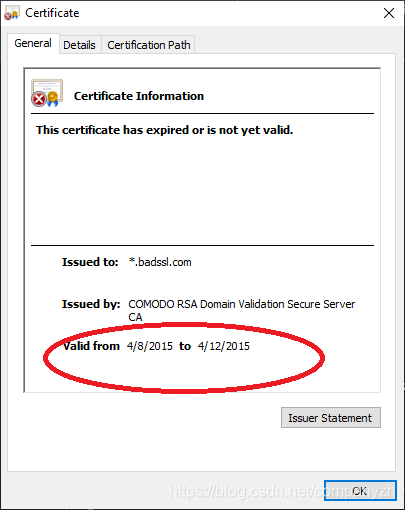
你可以看到这个证书是什么时候过期的,非常适合查看服务到期后客户端的行为。这也使我们有机会了解不同客户的行为方式。我就不一一列举了,感兴趣的你可以自己研究一下这个网站,看看对你有没有吸引力。
21 HTTP的高级篇 - HTTPClient(Java)
HttpClient API
HttpClient API是在2018年9月发布的Java 11中引入的。但是,它早在Java 9的前一年就已经可以作为预览功能使用。因为API需要一段时间的打磨才能变得成熟和完善。所以,从Java 11开始,HttpClient API是Java标准库的一部分。这意味着你不需要再向应用程序添加任何外部依赖关系即可使用此API。 HttpClient API替代了在Java标准库中存在了很长时间的HttpURLConnection API。稍后,看我心情要不要说一下为什么需要替换此API。与HttpURLConnection一样,新的HttpClient API支持HTTP 2和WebSocket通信。而且它还支持HTTP的早期版本。 HttpClient API的另一个重要功能是,它提供了同步阻塞和异步非阻塞的方法来执行HTTP请求。HttpClient API的设计目标是在常见情况下易于使用,但是在复杂情况下也具有足够的功能。
HttpClient
HttpClient API提供了三个重要的类型。所有这些类型都存在于java.net.http包中。首先,有HttpClient类本身。其中包含两个重要的方法:
- send->send方法执行对服务器的同步和阻塞调用。
- sendAsync->sendAsync方法执行异步的非阻塞调用。
你不能直接实例化HttpClient类。有一个newBuilder方法为你提供了一个构建器类。HttpClient API中的大多数类型都使用了这种构建器模式。
HttpRequest
发送方法的参数之一是HttpRequest。 HttpRequest包含你希望获得的所有信息,例如请求所针对的URI,可能需要与请求一起发送的HTTP headers,以及指示它是GET,PUT,POST还是其他HTTP的方法。与HttpClient相同,你不能直接构造HttpRequest。但是可以通过构建器来做(HttpRequest.Builder)。Builder总是返回不可变的对象。所以,一旦创建,无论是HttpRequest还是HttpClient 都无法更改了。有请求那就必然也会有响应。
HttpResponse
我们来看一下HttpResponse类型。除了URI,headers和statusCode,通常HttpResponse中最重要的部分是正文。这就是HTTP服务器返回的有效负载。了解了这三种类型,你就可以开始使用API来执行HTTP请求了。我们来看一个最简单的示例。
Hello World 小程序
从创建HttpClient实例开始。我们知道你可以使用构建器模式来执行此操作。但是,HttpClient上还有一个名为newHttpClient的静态方法,该方法将返回应用了所有默认设置HttpClient实例。我们的这个例子就以使用它开始。然后,我们需要创建一个请求。在这里,我们将构建器模式与HttpRequest.newBuilder方法一起使用。我们可以将URI传递给newBuilder方法,我们使用csdn的网址。默认情况下,HttpRequest构建器将向服务器构造一个GET请求。现在,我们只需调用build并返回一个HttpRequest即可。到目前为止,还没有执行实际的HttpRequest。我们只创建了Client和一个请求。现在我们需要发送一个请求。我们可以调用client.send方法并传递刚刚创建的HttpRequest。 send方法还有第二个参数,我们传入一个所谓的BodyHandler(不用理会,只是一个过客)。client.send方法返回一个HttpResponse对象,该对象包装成字符串并提供了有关很多响应的元数据。是不是很简单。代码如下
1 | HttpClient httpClient = HttpClient.newHttpClient(); |
为什么HttpURLConnection被打入冷宫
我现在心情还不错,来给你们说一下为什么HttpURLConnection被打入冷宫。

这是一个悲伤的故事,那是一个寒冷的冬天。。。(回归正题)这其中有多个原因为什么需要替换HttpURLConnection,首先这是一个非常古老的API。 Java的第一个版本于20多年前1996年发布。HttpURLConnection被添加到Java的JDK 1.1中,该版本于1997年发布。这也刚刚好是HTTP 1.1的被设计出来的时间。在对HTTP请求和响应以及典型的交互模式进行建模方面,事情并没有现在那么清晰。现在看来,HttpURLConnection及其相关类中有很多过度抽象(谁告诉我抽象是好事来着,你出来,我保证不打你)。这些抽象使映射HttpURLConnection方法中发生的情况和实际HTTP发生的情况变得相对困难。
该API太旧了(就是说你老,你能咋地),它不包含泛型,枚举和lambda,因此在现代Java中使用时感觉很笨拙(过时)。虽然从Java 11,HttpURLConnection已被HttpClient取代,我还是希望你能了解一下HttpURLConnection API。你还是可能会在旧代码中遇到它。只有通过查看旧的API,你才会欣赏到HttpClient给你带来的改进。
1 | try{ |
说明一下,这并不是使用HttpURLConnection的最佳实践,因为它不能解决所有使用API的用例。我只是举一个例子。以此来指出一些与API不带优雅的地方。比如,这个第二行的类型转换,第三行没有Enum。因为在设计此API时还没有枚举这个概念。所以,你可以在此处轻松输入格式错误的字符串。然后可以向连接请求输入流,但这就是原始输入流。因此,我们需要编写一个辅助方法,在本例中为readInputStream,以获取原始输入流并将其转换为有用的东西。那是相当底层的操作。所以,不应该在新代码中再使用HttpURLConnection。
但是,如果你还没有使用Java 11并且没有访问HttpClient API的权限怎么办?你仍然不应该使用HttpURLConnection。在这种情况下,最好查看用于执行HTTP请求的第三方库。包括Apache HttpComponents项目,该项目提供HttpClient API,还有Square的OkHttp,这是Java的另一个开源HttpClient,还有更高级的库,例如JAX-RS REST Client。该REST客户端不仅执行HTTP请求,而且应用了REST原理,并且可以自动将JSON响应映射到Java对象。无论如何,现在都不应该使用HttpURLConnection API。如果你使用的是Java 11,请使用我们现在正在谈论的HttpClient API,如果不是,请使用这些第三方组件之一。
HttpClient的配置
我们不可能在一篇文章中,把一个API完全讲透,但是我们还是尽量的把一些关键点讲出来。现在来更深入地研究一下HttpClient API,包括诸如处理headers,接受cookie以及执行具有请求主体的HTTP请求的功能,这些请求与到目前为止所看到的HTTP GET请求不同。但是在继续使用这些功能之前,让我们更深入地了解一下HttpClient本身的配置选项。我们之前使用了新的HttpClient方法,该方法为我们提供了所有默认设置的HttpClient。作为HelloWorld来说,还不错。但是通常你要自己调整一些配置选项。所以,使用构建器API创建HttpClient时,有几个选项可以影响使用此HttpClient完成的请求的行为。这些配置选项中的大多数不能在请求级别覆盖。如果针对不同类型的请求则需要不同的配置,也就是说需要创建多个适当配置的HttpClient实例。我们将重点关注与安全性无关的配置。
HTTP Version版本
第一个配置是HTTP版本。使用HttpClient.newBuilder创建构建器后,可以使用version方法配置将使用的HTTP版本。版本枚举本身嵌套在HttpClient类的内部,一共有两个选项
- HttpClient.Version.HTTP_1_1
- HttpClient.Version.HTTP_2
HTTP 2是默认选项,如果HttpClient配置为HTTP 2,但是服务器不支持HTTP 2的话,它将自动回退到HTTP 1.1。 HTTP / 2流量看起来与HTTP / 1.1流量完全不同。您也可以根据个人要求配置版本。
Priority 优先级
第二个配置是优先级。由于仅在HTTP 2协议中指定了优先级,所以这个配置选项仅影响HTTP 2的请求。优先级设置采用1-256范围内的整数,包括这种情况下的边界值。较高的数字表示较高的优先级。
Redirection 重定向
另一个设置与重定向策略有关。默认情况下,HttpClient配置为从不重定向。这意味着,当对要重定向到另一个URI的服务器执行请求时,HttpClient将不会遵循此重定向。你还可以将HttpClient配置为在服务器响应重定向状态代码时始终遵循重定向。最后,有一个正常的重定向策略,它与始终重定向相同,只是从安全资源重定向到非安全资源的情况除外。从安全位置重定向到非安全位置通常是安全问题。这就是为什么建议使用常规重定向策略而不是使用Always策略的原因。
- HttpClient.Redirect.NEVER
- HttpClient.Redirect.ALWAYS
- HttpClient.Redirect.NORMAL
Connection Timeout超时
它需要一个java.time.Duration,并且这是HttpClient等待建立与HTTP服务器连接的时间。如果未配置connectTimeout,则默认设置为无限期等待,这肯定不会是你想要的。connectTimeout与建立与服务器的TCP连接有关。如果花费的时间比配置的connectTimeout长,则将引发异常。
Custom Executor自定义执行器
最后,还有一个配置选项,用于设置供HttpClient实例使用的自定义执行程序。 HttpClient使用执行器来执行异步处理。默认情况下,在构建新的HttpClient时,它还会为此HttpClient实例化一个新的私有线程池。在某些情况下,你可能希望在不同的HttpClient之间共享一个执行程序。你可以通过自己创建或获取执行程序并将该执行程序传递给HttpClient构建器上的executor方法来实现。比如
1 | Executor exec = Executors.newCachedThreadPool(); |
综合的例子
1 | HttpClient client = HttpClient.newBuilder() |
请求的有效负载
我们一直都在使用简单的GET请求作为案例,这些请求不会将负载传输到HTTP服务器。我们现在来看一下如何创建包含有效负载的请求。此有效负载可以是纯文本,可以是JSON,也可以是任何任意二进制有效负载。通常,HTTP POST的请求主体中包含有效负载。
除了HttpRequest.Builder上的GET方法外,还有一个POST方法。与GET方法一样,POST方法也带有一个参数,即所谓的BodyPublisher。此BodyPublisher负责产生与POST请求一起发送的有效负载。从这个意义上讲,BodyPublisher与我们之前看到的用于处理响应有效负载的BodyHandler类似。 它告诉HttpClient如何在给定Java对象的情况下构造HTTP请求的主体。你可以在BodyPublisher的类上找到现有的预定义BodyPublisher。比如,HttpRequest.Builder上还有PUT方法,这将使BodyPublisher提供的主体有效负载创建一个HTTP PUT请求。
- POST(BodyPublisher publisher)
- PUT(BodyPublisher publisher)
除了POST和PUT之外还有其他HTTP方法,例如PATCH。但是,并非每个HTTP方法在HttpRequest.Builder上都有其自己的方法。如果要创建除GET,POST或PUT之外的请求,则必须在HttpRequest.Builder上使用method方法。
- method(String method, BodyPublisher publisher)
方法采用两个参数,其中第一个是表示要请求执行的HTTP方法的字符串,以及一个BodyPublisher。
Headers and Cookies
你已经了解了如何使用主体创建HTTP请求。客户端向服务器执行HTTP请求时,它必须定义要使用的HTTP方法(比如GET)和要获取的资源比如 /index.html。但是,HTTP请求还有更多的要素。它还包括headers。
headers是简单的键/值对,其中可能包含有关请求的其他元数据。一个示例是主机头。比如
- Host:www.csdn.net
如你看到的,它显示为Host :值是www.csdn.net。主机标头是HTTP 1.1和更高版本的必需标头之一,它由HttpClient根据创建请求时传递的URI由HttpClient自动为我们管理。除了这些强制性和自动管理的标头之外,有时你还希望向请求中添加其他标头。例如,您可能想添加一个accept标头。
- Accept: text/html
accept标头告诉服务器我们想要的首选响应类型,此处表明我们想取回HTML文档。诸如accept之类的标题是HTTP规范的一部分,但它们是可选的。因此,如果你想添加这样的标头来执行请求,则必须为此做一些工作。也可以向HTTP请求中添加任意的,未指定的标头。在API中的写法就是这样
1 | HttpRequest.newBuilder(URI.create("https://csdn.net")) |
如果你要有多个标题,那当然也可以。只需重复使用header方法,直到将所需的所有标头添加到请求中即可。甚至可以使用headers方法而不是header方法一次性添加多个标题。标头始终需要偶数个参数,因为每个标头名称都必须带有一个值。如果您添加相同的标头,使用相同的标头名称,并多次使用不同的值,那么所有这些值都会出现在标头中,因为HTTP定义了标头可以具有多个值。如果你要绝对确定标头没有多个值,则也可以使用setHeader方法,该方法也可以使用标头的名称和标头的值,但不必将值添加到标头中替换当前值。
当你构建请求并通过HttpClient发送请求时,HttpClient将负责以正确的方式将标头和值添加到HTTP请求。对于HTTP 1.1和HTTP 2,它的执行方式完全不同。 HTTP 1.1是纯文本协议,并且标头将添加到此纯文本中请求。 HTTP 2是一个二进制协议,标头将以二进制格式编码,甚至经过专门压缩。不过你不用担心这些,对于你来说,API是相同的,复杂性全都隐藏在HttpClient的实现中。
还有另一种与HTTP紧密联系的机制,HTTP本身是无状态请求响应协议。我们从服务器请求一些东西,服务器提供响应,然后客户端和服务器彼此相忘于江湖。但是,在许多情况下,你希望保持有关服务器和客户端之间交互的某些状态(我就是忘不掉我的前女友,这可咋办)。

Cookie是一种主要用于浏览器的方式。 Cookies包含服务器定义的状态,但是状态由客户端保留,然后在必要时再发送回服务器。有趣的是,这种机制是基于标头构建的。服务器还可以在响应中包含标头。并且,当服务器包含Set-Cookie标头时,客户端应将此标头解释为要保留给下一个请求的状态,这也是该机制在浏览器中的工作方式。当浏览器看到Set-Cookie标头,并且在标头的主体中包含一些键-值对时,它将把这些名称/值对存储在与请求域相关联的所谓持久性cookie中。然后,每当对同一个域提出新请求时,浏览器将包含一个Cookie标头。 Cookie头的值是先前存储的名称/值对。这样,浏览器和HTTP服务器可以在不同的无状态HTTP请求之间创建持久状态的错觉。当然,只有当服务器和客户端都知道Set-Cookie和Cookie标头时,整个设置才有效。你可以尝试使用HttpClient自己实现此目的,因为它全都与Set-Cookie和Cookie标头有关。因为关于Cookie的行为方式复杂性要很高,所以你其实并不想自己管理。好消息是HttpClient为我们提供了一个用于配置cookie的处理。你可以使用setCookieHandler来配置HttpClient使用它。如果你希望HttpClient使用cookie,那么一种快速的入门方法是使用CookieManager类。 CookieManager是CookieHandler的JDK内部的具体实现。在此示例中,我们创建一个新的管理器,第一个参数是Cookie持久存储在其中的CookieStore。

1 | CookieManager cm = new CookieManager(null, CookiePolicy.ACCEPT_ALL) |
还是那句话,不可能把所有的内容在一小节上全讲解,如果有人感兴趣的话,给我在文下留言,如果留言多的话,我会再整理一篇。
22 想来我家,你自己查呀 - DNS
我们的课程已经过一大半了。先给自己一个奖励。当然也感谢你愿意继续的和我这段学习旅程。我们今天一起来看一下DNS。其实前面已经多多少少讲了一些DNS的工作原理。今天还是由浅入深的来看一下。

主机文件和DNS缓存
我将从hosts文件开始我们DNS的旅程。自DNS诞生以来,hosts文件就已存在。当Internet还仅仅由MIT,军方和少数其他组织组成的时候,hosts文件时一种对IP地址解析名称的简便方法。但是随着互联网的发展和壮大,你能否想象拥有一个包含每个网站及其相应IP地址的主机文件?答案当然是不可能的。hosts文件也是IP地址引擎的最开始的名称。 DNS就是从此发展起来的。每当我们讨论主机文件时,我们都必须要讨论DNS缓存。当DNS需要将名称解析为IP地址时,有几个地方需要来检查。第一个位置就是检查本地计算机,因此,第一步,DNS会在每台机器上本地查看。第二步,在读取主机文件后,再发送给DNS服务器之前,会查找DNS缓存。DNS确实非常努力地尝试在本地对IP地址进行DNS解析。因此,查询的顺序就是本地文件,DNS缓存最后才是DNS服务器服务。根据操作系统的不同,编辑主机文件有所不同。
Windows
如果你使用的是Windows操作系统,可能是Windows 7、8、10或任何服务器操作系统,那么你想要做的就是打开提升的命令提示符。如果你不熟悉,请单击“开始”按钮,键入cmd,然后在出现命令提示符时,右键单击并选择“以管理员身份运行”。然后,键入记事本,然后输入主机文件所在的路径。比如 notepad C:\Windows\System32\drivers\etc\hosts,你可以进行任何更改,最后一步是刷新DNS缓存,因为刷新DNS缓存时,将读取主机文件并将其放入DNS缓存中。
Mac & Linux
在Mac操作系统上,你将启动Terminal。输入sudo nano /private/etc/hosts,然后对该主机文件进行任何更改。刷新DNS缓存。在Linux机器上,可以键入sudo vim /etc/hosts。修改文件然后刷新DNS缓存。
DNS在本地找不到怎么办呢?
上面看到了DNS查找的流程。那如果DNS在本地找不到呢?
你试想一下,我们有大量的网站和IP的对应。这些不可能存在一个DNS服务器上,对不对。所以,就好像我们的王牌对王牌一样,要一个个的去传,一个个的去问。因为当我么去问一个DNS服务器答案时,如果它不知道答案,它将要问别人也就是另一个DNS服务器,当然也是不得不去问别人。
比如说我有一个工作站,在该工作站中有一个本地DNS服务器。我现在要输入https://www.csdn.net/。 该DNS查询转到DNS服务器,这个是本地的服务器,不是csdn的,所以它不知道答案。它会说我不知道答案,但是我可以帮你问下一个人,于是把请求发到了Root也就是根服务器,问,你知道大名鼎鼎的csdn的IP地址吗,这个ROOT服务器会说,我也不知道,但是我可以帮你问问.net DNS服务器。于是你又问.Net DNS服务器,你知道大名鼎鼎的csdn的IP地址吗,这个.net DNS服务器会说,对不起,我不知道,但是我能帮你问问csdn的DNS服务器。然后你就又去问csdn服务器,这个服务器说,我当然知道了。IP是47.95.164.112。然后你可以去访问这个IP地址了,你就可以看到华丽辉煌的csdn网站了。然后你本地的DNS服务器会把这个记录也就是csdn.net = 47.95.164.112放到DNS缓存里。这样当你女朋友也想去csdn学习的时候,就不需要再继续上面那些复杂的查询了。可以直接得到csdn的IP了对不对。
你可能会有疑问是不是,那就是这个本地的DNS服务器是怎么知道根服务器的呢。这个就是我上面提到的根提示。
根提示
这个根提示也就是Root Hints,在互联网上不止一个。它们存储在名为CACHE的文件中。你如果可以接触到一个Windows的服务器的话,可以从Systemroot\system32\dns文件夹中找到这个文件叫做CACHE.DNS。你可以查看并且编辑。
1 | HOSTNAME(主机名) IP ADDRESSES(IP地址) OPERATOR(拥有者) |
权威与非权威的回应
权威的回应,就好像是上面的例子,你的工作站和你的DNS服务器在同一个DNS Zone。比如这个DNS服务器是test.com DNS Server,那么这个服务器上会有所有和test.com相关的DNS对应信息,你如果想查询www.a1.test.com,你可以直接通过这个DNS服务器来查到。像这种可以从DNS拿到消息,而且这个消息不是在Cache里,而是在它的Zone里面的情况就是权威的。因为这是最可信的。当然这个例子不一定准确呀,就好像你想知道你二叔家的地址,是不是问你爸给的答案是最准确的。因为他们是在同一个ZONE里面。
非权威的就好像我们上面的那个例子,问了A,然后问B,然后问C,最后才找到。这个就好像你想去二叔家,你就一路的去问,比如说你知道住北京,然后有人说,你二叔在东城,然后有人说在东城的某一个区域,(我不是北京人,不太了解具体地址呀)。就这样一路吻下去,最后才找到,所以这个就是非权威的。
其实看到这里,我相信聪明的你已经大概知道了DNS的结构,至少你应该知道上面提到的根就是DNS的最开始需要检查的地方。下面我们来看一下DNS的结构。
DNS的结构 DNS的最高的级别就是我们上面提到的Root,一共有13个。然后下面就是.com,.net ….,这个叫做Top Level Domain也可以简写成TLD。ICANN(Internet Corporation for Assigned Names)负责大部分TLD的分配。专门负责TLD的叫做TLD服务器。然后根据不同的Top Level会有Second Level,比如.Mil很明显就是军方使用,下面可以有Army,Navy。Edu很明显是教育,下面可以有MIT,Berkeley,然后就是比如csdn的Domain在.net的下面,这样看起来是不是就很清楚了。
DNS Zone
DNS Zone一共有两种
- Forward Lookup Zone(正向查找) - 这个是Host Name to IP,就是你给我Hostname,我给你查IP
- Reverse Lookup Zone(反向查找) - 和老大相比,这个老二并不怎么受欢迎,那就是给你IP,找到对应的HostName,什么地方会用到呢?比如Microsoft Exchange Servers和其他的邮件服务器去验证这个源域名来确保这个邮件是来自于合法的域名,当然还有一些比较老的工具,比如NSLookup,traceroute,SMTP
DNS Zone Type
主区域(Primary Zone)
- 权威的区域信息。
- 具有区域数据的读/写副本。
- 接受来自客户端的动态更新或动态DNS。
次要区域(Secondary Zone)
看这个例子,比如说你有一个网站,同时有两个办公地点,北京和上海。在北京的站点,有一个DNS服务器。在上海的站点则没有。假设你有50个客户,他们都被指向北京站点以使用该DNS服务器。在两者之间,我们有一个WAN链接,但是你为了贪图小便宜吧,这不是最大的WAN链接。有的时候它就会崩溃了,上海站点中的可怜用户无法再访问任何需要DNS解析的内容了。要解决此问题,你可以复制一份你网站DNS区域从北京站点到上海站点的服务器,然后你可以将所有50个客户端指向该本地上海DNS服务器。使用客户端DNS配置,你可以配置多个DNS服务器供客户端查询。因此,如果你希望将这些客户端指向北京站点,则可以在这些客户端上具有主DNS服务器,然后将它们指向上海站点,则可以具有辅助DNS服务器。也可以反过来,由你自己来决定怎么设计这种模式。一旦你在上海站点上关闭了DNS服务器,你的客户端就可以将所有查询本地发送到该DNS服务器,而他们不再需要依靠不稳定的WAN链接。辅助DNS区域,我们获得辅助DNS区域的方式是执行区域传输。从主DNS服务器获取区域的副本。
DNS 区域传输 (Zone Transfer)
现在假设你开始第一次去索要复印件,你就拥有了一切,这个叫做AXFR。之后,每一次的传输完毕了之后,叫做IXFR(Incremental zone Transfer),只是给我从上次更新之后的数据就可以。现在,存在于辅助DNS区域上的信息被认为是权威的。因为当客户端向辅助DNS服务器询问问题时,如果这个响应的解决方案位于该计算机本地,则它被视为权威响应。辅助区域是只读的。你不能在辅助DNS区域上进行动态更新。只有主数据库才能发生动态更新,但是你可以在主服务器上进行动态更新,然后将数据复制到辅助DNS服务器。
DNS区域传输是通过端口53执行的。你可能会问自己,这个传输是UDP还是TCP?(如果你这么问,说明你已经迷恋上了网络协议,而且恭喜你,你已经可以算是入门了)。如果所有数据可以放进一个数据包,则它通过UDP传输。如果有太多数据(如初始AXFR中的数据),则复制将在TCP中执行,因为它必须分解数据并将其放入单独的数据包中。所以当涉及到防火墙的时候,你需要知道的是传输是通过UDP还是TCP,答案是两者都可以。
缓存DNS服务器 (Cache Only DNS Server)
这是最简单的DNS服务器
- 你所要做的就是安装DNS,工作就完成了!
- 它不包含任何区域(zone)。
- 缓存是在一段时间内建立的。
发生的情况是,你将客户端配置为将其DNS查询发送到上面没有区域的DNS服务器。客户询问该服务器的任何问题,都必须走出去并找到答案。找到答案后,会将答案放入其本地缓存中。因此,这就是仅缓存DNS服务器的工作方式,它会在一段时间内建立缓存。重新启动该服务器后,将刷新缓存。
资源记录(Resource Record)
在正向查找区域中可以放置不同类型的资源记录,其中一部分普通的。还有其他一些根据你所运行的DNS不同而产生的特定类型的资源记录。
普通资源记录(Common Resource Record)
- 主机记录是最常见的资源记录之一。 A记录是IPv4 host记录。AAAA就是IPv6 host记录。
- PTR或指针记录是驻留在反向查找区域中的记录,这些记录指向正向查找区域中的主机记录。
- CName是计算机的昵称。如果你的环境中有一台服务器,并且你希望所有人出于任何原因使用不同的名称来访问它,则可以将CName记录设置为指向主机记录。比如你的地址可能是sfredsddsd.com,你完全可以改为shuaige.com这样其他的人也好记。
- SRV记录或服务定位记录表示机器上运行的不同类型的服务。例如,在Microsoft环境中,如果客户端计算机想要查找域控制器,则它将向DNS服务器发送查询,询问该域的SRV记录,然后它将获得一个域控制器的列表,该列表它可以针对用户的任何目的进行身份验证。
- MX记录。这些是邮件交换记录,它们表示邮件服务器。在Microsoft环境中,它将是交换服务器。
- NAPTR。通常用于互联网电话中的应用。一个例子就是会话发起协议(SIP)中服务器和用户地址的映射。
特殊的资源记录(Special Resource Record)
- NS或Name Server(DNS Server)。名称服务器记录表示DNS正在该服务器上运行,这就是使它成为Name Server的原因。
- SOA或Start of Authority或者是一个提供权威信息的DNS服务器。
把以上的原理了解清楚了,你的DNS知识就也足够了。
23 来的早,不如来得巧 - NAT
为什么需要NAT?
IP地址被设计为全球唯一且可全球访问。IP寻址是支持Internet端到端体系结构的基础。1990年代初期,Internet的爆炸性增长不仅预示了IP地址空间耗尽的危险,而且对IP地址本身也产生了即时的需求。现在,我们需要连接大量的用户网络和家用计算机,它们都需要大量的IP地址。 IPv4寻址方案中只有40亿个地址,而我们拥有的计算机比这多出十亿,当然也有比这个数字大的多的多的人口。这就更加造成了IP地址的不足。NAT就在这个时候出现了。它可以满足这一快速上涨的需求(这就是所谓的,站在风口上,猪都能起飞)。它突然为我们提供了数十亿个内部可使用的地址,这就扩大了我们可以使用IPv4在Internet上使用的IP数量。 NAT在没有采用IPv6的任何情况下就已经出现,如果不是那样的话,我们可能也不需要NAT。

什么是NAT?
NAT的全名是(Nerwork Address Translation),也就是网络地址转换。它是一种协议,用于在从一个网络穿越到另一个网络时修改源和/或目标IP地址。换句话说,此协议将修改我们的源IP地址,例如我们网络上的内部IP地址,并且在出Internet时将其替换为自己的公共IP地址(就好像在家怎么都无所谓,出门了就必须要装扮起来,和别人看上去有所不同)。
NAT也可以反向使用。如果有人从外部进入我们的Web服务器,他们将转到防火墙上的公共IP地址,然后它将转换为我们Web服务器上的内部IP地址。这样,他们就永远不知道内部的实际IP地址是什么。
那是什么设备使网络地址转换起作用呢?
- 首先我们有防火墙。它们与这节提到的网络地址转换一起工作,并且在数据出到Internet时也将私有转换为公有。
- 路由器以及所有相关设备的情况,它们都会剥夺源IP地址。
- 交换机也可以,但是交换机必须要有一个特定的功能,那就是必须具有InterVLAN功能才能使用NAT,这基本上意味着该交换机已变成路由器,可以在其中将数据从一个子网路由到另一个子网。如果我们使用不具有InterVLAN的第2层交换机,则它所能做的就是将其转发到路由器上,然后路由器提供NAT服务。
NAT的存在价值就是需要更多的IP地址并向潜在的黑客隐藏我们自己的内部地址。正是因为NAT为我们执行了这两项功能,因此在IPv4网络中使其变得无价。
NAT类型
NAT一对一转换
最简单的NAT提供的是IP地址的一对一转换。基本的NAT可用于互连两个不兼容的IP网络地址。例如,如果我们的私有IP为10.1.1.2,它将通过NAT转换为9.9.9.9(这也被称为静态NAT)。当消息发送到公用计算机并使用防火墙或路由器提供的IP替换IP时,它会隐藏其内部IP地址。
我们现在来看一下NAT是怎么遍历的。如果我们使用内部PC从右下角的10.1 .1 .2私有IP开始,则流量将通过交换机上升并通过防火墙。这也就是流量从我们的内部IP转换为公共IP 9.9.9.9的地方。在到达Web服务器时,Web服务器仅看到公共IP,不知道私有IP是什么(就好像有一个笑话,你在北京上海工作的时候叫什么Linda,Lisa,但是回了村是不是叫二狗和翠花,但是你在外面工作的时候,没人知道你”内部”的名字吧。没有贬低呀,只是举个例子,这个道理是一样的)。可以参考下面这个图
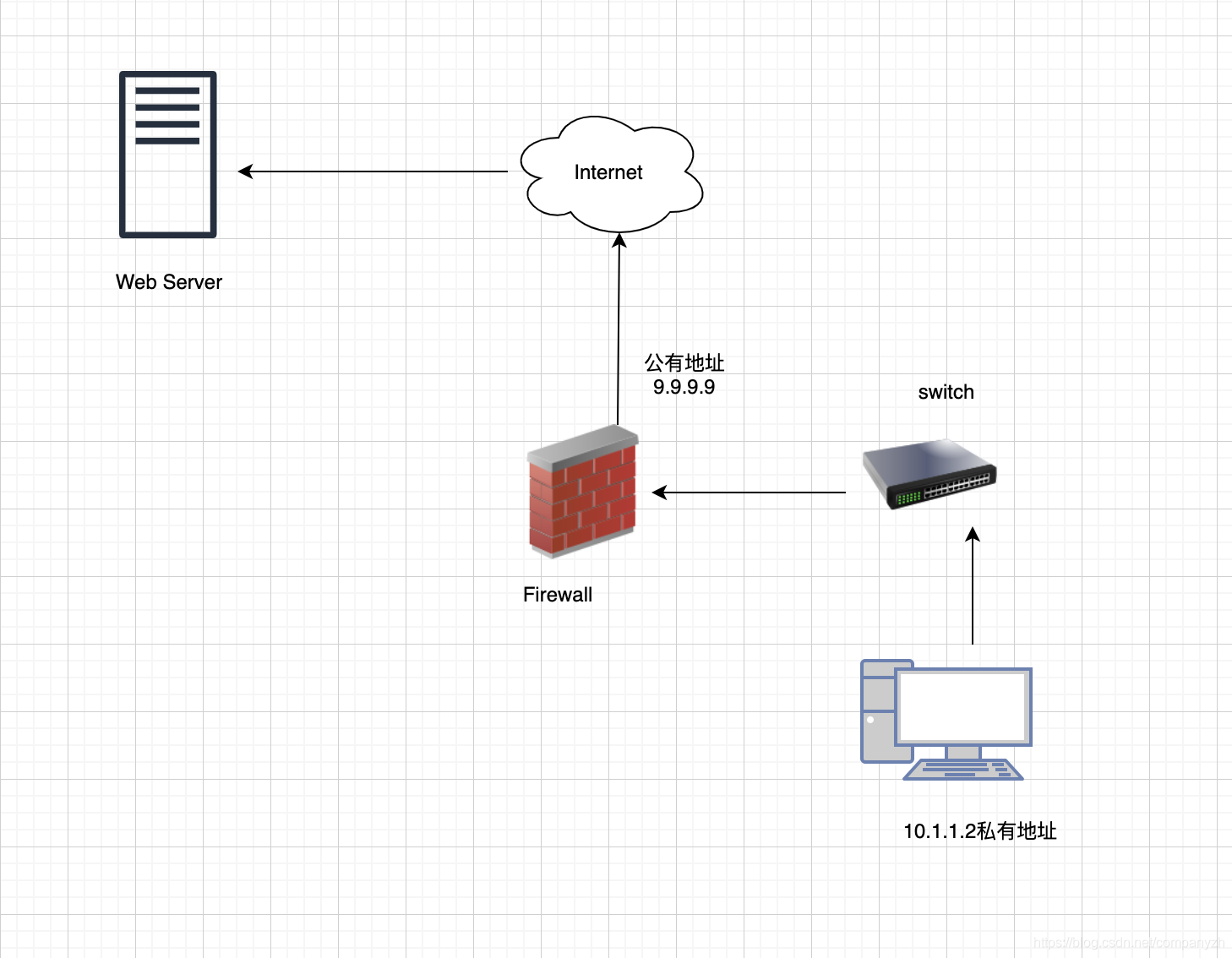
NAT一对多转换
一对多NAT是最常用的NAT,因为它可以保留公共网络上的IP地址。局域网中计算机的所有内部地址有时会出入Internet以查看网站或使用其他服务。他们所有人都会将其内部地址隐藏在公共IP或防火墙后面。你还可以创建一个包含多个公共IP的池,以使黑客猜测这些IP的来源。你必须分配一个IP地址区域,而不是在防火墙外部分配一个具体的IP地址。在这种情况下,它称为“少对多”,而不是“多对一”。当你在防火墙的公共端上只有一个IP地址,并且内部有许多设备都需要因为不同的目的转发流量就外面的花花世界转一圈时,我们使用一种称为NAPT的设备。这个设备也称为PAT或者Port Address Translation也就是端口地址转换。让我们再次看一下NAT遍历,但是这次,我们将要从外部PC开始,然后将其连接到Internet,之后再通过我们的公共防火墙。至此,它将进入我们的网络内部。这也是讲9.9.9.9转换为10.1.1.1 - 3。这些服务器中的每一个都执行不同的操作,所以它们侦听不同的端口,这也是为什么我们看到Web服务器侦听端口80,而电子邮件服务器侦听端口是25。可以参考下面这个图

我们要做的是使用端口地址转换将其拆分。这确实可以节省公共IP地址,因为我们使用两个提供两种不同服务的公共服务器,并且使用了端口地址转换,但是使用了单个公共地址。今天使用的最常见的NAT类型对于IP保留和安全性非常有用。尽管这个方案不是完美的解决方案,但由于安全性和缺乏可用的公共IP,NAT具有许多功能,如果没有它,将无法使用当前的IPv4。
NAT环回
另一种网络地址转换类型称为环回,也称为反射。它是基于RFC 1483,指的是位于公共IP地址上的主机名IP,但实际的服务器位于你自己的局域网内。所以当你想访问此网站时,看起来像要通过防火墙,然后再次重新进入内部。通常来说,除非防火墙启用了RFC 1483这个功能,要不然防火墙是不允许这样做的。
NAT环回是一种NAT功能,如果局域网内部有需要由同一网络中的其他设备访问的资源,则可以使用大多数防火墙和路由器将其打开。
IPV6和NAT的关系
我前面提到过NAT出现的时候,还没有IPV6,那他们两个是不是竞争关系呢?网络地址转换在IPV6中并不常用,因为IPv6的设计目标之一是恢复端到端网络连接。引入NAT时,端到端连接断开了,因为NAT设备会从源IP中剥离信息,这是端到端通信正常工作所必需的。
IPv6具有2的128次幂,这就是使得NAT允许保存的地址的需求变得多余。因为IPV6可以为每个设备分配唯一的全局可路由地址。 IPv6-to-IPv6网络前缀转换或NPTv6是一项实验性规范,主要是为了实现隐藏内部IP地址的功能,使其不会隐藏到可用于网络地址转换的Internet。它是无状态的,这意味着它不存储有关连接两侧的任何信息,并且达到了端到端主体。 NPTv6不会像IPv4中那样将整个地址从私有地址转换为公共地址,而只会转换为IPv6地址的前缀位。尽管并没有普遍使用基于IPv6的NAT,但是该技术正在发展,因此端到端连接将继续起作用,同时也是出于安全目的而混淆内部IP地址。
NAT影响的应用
网络地址转换会影响几种不同的应用程序。我们在这里来看看其中的一些例子。
- 第一个是处于Actve模式的FTP或文件传输协议,它使用单独的连接来控制流量和传输文件内容。当需要文件传输时,发出请求的主机通过其TCP/IP地址识别相应的数据连接。如果发出请求的主机位于简单的NAT防火墙之后,则IP地址和端口号的转换会使服务器接收的信息无效。
- 另一个例子是会话启动协议(SIP VOIP Calls)),它可以控制许多IP语音通话,并且存在相同的问题。 SIP使用多个端口建立连接并通过实时传输。在遍历网络地址转换之前,必须知道IP地址和端口号。
但是,有一些特殊的技术可以解决这些问题,我们使用软件来解决这一问题。解决这些问题的方法之一是应用程序层网关(Application Layer Gateway)。应用层网关软件或硬件可以解决许多这些问题。 ALG软件模块需要在NAT防火墙设备上运行,并且它会更新由于地址转换而无效的任何有效负载数据。 ALG需要了解他们需要修复的协议,因此每个有此问题的协议都需要一个单独的ALG。解决该问题的其他方法还有STUN或ICE。 STUN代表(Session Traversal Utilities for NAT) NAT的会话遍历实用程序,它专门用于解决由NAT引起的VoIP和流式传输的实时问题。当然这些只是做个介绍。聪明的你是不需要知道这些细节的,一般只有真正的硬件网络工程师才需要知道的更多(你已经知道的太多了)。
NAT的局限
再好的技术都不会是完美的,那我们来看一下NAT当前实施起来的局限性和安全性问题。根据VMware的说法,NAT会造成一些性能损失,因为NAT要求发送到虚拟机和从虚拟机接收的每个数据包都必须位于NAT网络中,这是不可避免的性能损失。
其次,NAT并非完全透明。网络地址转换通常不允许从网络外部启动连接。尽管你可以手动配置NAT设备以建立服务器连接。但是实际情况确是,某些需要从服务器启动连接的TCP和UDP协议无法自动运行,而有些协议可能根本就无法运行。
NAT提供了一些防火墙保护。标准NAT配置提供基本级别的防火墙保护,因为NAT设备可以启动来自专用NAT网络的连接。但是,如果没有其他手动配置,外部网络上的设备就无法启动与专用NAT网络的连接。 NAT在扩展IPv4地址的数量和隐藏我们的内部地址方面很有用,但是它并不完美。权衡利弊,在没有完全实施IPv6之前,NAT是解决这两个问题的最佳且唯一的解决方案。
NAT的成功就说明了,来得早,不如来得巧。兄弟们,加油吧!
24 辛苦的邮政 - SMTP
什么是通信?
什么是通信?这个可能是一个比较文绉绉的词,说白了就是计算机之间的交流,唠嗑。我们从出生开始就一直在唠嗑。所以你应该对这个词不陌生。你细想一下,你唠嗑是为了啥,是不是在交流我们的需求。而且唠嗑也是我们用来了解某人的方法,比如你看上了一位美女,你直接要微信是不是比较鲁莽,除非你和老师一样帅(开玩笑)。

你是不是应该先去聊聊天,唠唠嗑,然后再要微信。在微信上可以继续的聊天,交流你们之间的感受。因此,交流是将我们的想法与其他人联系起来的机制。
好,现在不要想小姐姐了,想想比较实际的。思考一下每天与你们交流的所有人。和工作中的同事你们会交流什么?是不是会包含项目的进展,项目取得了哪些成功?潜在的困难是什么?回到家中,你还会与朋友和家人就生活中发生的事情进行交流,可能是重要的事,也可能只是一个有趣的事情,也可能是令人兴奋的事情。现在微信比较流行了,但是使用电话也是一种很好的交流方式。你可以给你的朋友打电话。或者是给你刚认识的小姐姐打电话,你先介绍你自己,让这个美女知道他正在和刚才认识的那个帅哥说话。然后你可能会说,嘿,听说市中心有一家新的咖啡店开业?你要不要尝试一下?然后你是不是就和小姐姐有了一次潜在约会的机会。当然这里不是教你怎么约小姐姐,就像电话可以帮助我们交流和交换思想一样,互联网也是一种交流机制(这个才是我们的主题,虽然刚才讲的东西可能才是你最关心的,现在把思想收一下,回到主题上来)。它在我们的生活中发挥着巨大作用,也真真切切的影响着我们如今的沟通方式。只要考虑一下你每天使用Internet在计算机上完成的所有工作即可。你可以创建文档和PPT来更新你的项目进度,并与同事共享该信息。你可以浏览互联网以阅读自己喜欢的小说。看自己喜欢的小电影。阅读有关电视节目的信息(比如巡回检察组,我之前天天追剧到不行),查看电影放映时间好约小姐姐一起,阅读或查找餐厅评论(去哪里约小姐姐),还可以使用互联网购物。你细想一下所有这些活动都可以通过使用协议来实现。协议是你的计算机用于与包含我们要使用的所有信息的其他网络进行对话的机制。
SMTP的历史
在1960年代的计算机初期,人们不得不使用大型主机才能相互通信。下面这个老照片就是大型计算机,你能想象有一个这样的计算机在你家里吗?

我们今天拥有的小型便携式笔记本电脑,平板电脑和智能手机在那个年代是根本不存在的。大多数大型机是由大学,大型企业和政府所有的。随着越来越多的大型机变得普及,所有者也希望与其他大型机所有者建立联系。就好像单机游戏再好玩,你也会希望和别人一起玩,对不对。所以,他们需要找一个办法来进行沟通。因此,在此期间,这些人创建了许多不同的协议,并使用这些协议来允许所有这些大型机相互通信。最终,为了大家能一起玩”魔兽世界“的这个愿望,SMTP协议诞生了。
SMTP协议允许这些大型机作为邮件服务器。因为文本能够通过连接的网络从一个大型机发送到另一个大型机。有时,文本可以直接发送给收件人。但有时则要困难一些,文本必须通过几个大型机才能到达目的地。因此,随着越来越多的大型机连接到网络,要传送的文本到达其目的地变得越来越复杂。 SMTP作为一个协议,可用于在使用大型机的人员之间传输这些文本。随着SMTP协议在其早期的发展,它已经进化了很多,正因如此,它也广泛的应用了。 SMTP协议运行得非常好,最终在1982年8月成为电子邮件通信的全球标准。在1982年,创建了RFC 821(RFC 821就是提供了有关什么是SMTP以及其如何工作的说明手册)。多年来,SMTP协议还在不断的完善自己,它在2008年10月又对自己进行了更新(RFC 5321)

SMTP是什么?
好,了解了SMTP的历史,就好像你看了SMTP的出生证一样,知道他是什么时候出生的,那我们来认真的了解一下这位好少年,看看他究竟优秀在哪?SMTP是一个用户用于发送电子邮件时使用的协议。该协议对应的端口是25,这是所有电子邮件系统都知道的标准,那标准是哪来的呢?当然是因为我们上面提到的RFC 821和5321。
SMTP协议会在你和小伙伴使用的电子邮件系统之间创建连接或管道。就像当你看到小姐姐时,你会说,嘿,美女,你好。然后,这个小姐姐会回头看你说,嘿,你好,帅哥。这个回头其实也就是我们说的ACK(确认)。这个ACK就打开了你们俩之间的沟通渠道,使你们可以进行对话。你可能会说小姐姐你眼睛真漂亮,小姐姐会笑一下然后说是不是想加微信?这种我们日常每天都进行的来来回回也发生在邮件系统中。你可能说中文,我和同事说英文,那邮件系统呢?使用的是SMTP协议作为其语言。 SMTP协议允许在邮件服务器之间发送一堆基于文本的命令。这些命令会建立连接并允许会话的确认也就是ACK。我听到你了,你还挺可爱的,这种对话是你向别人发送电子邮件的基本机制。
现在,我们举个例子,比如你要给你的金主爸爸(王老板)发送电子邮件。当你想向王老板发送电子邮件时,你的电子邮件客户端(比如我们熟悉的Microsoft Outlook)会将消息发送到电子邮件服务器。然后,此服务器与王老板使用的另一个邮件服务器建立连接。每当你发送电子邮件时,都会发生一系列特定的事件。首先,你的SMTP客户端或Outlook将联系你的SMTP服务器,以便它可以建立与王老板的SMTP服务器的连接。但是,为了建立此会话,我需要找到王老板的SMTP服务器所在的位置。如何到达那里呢?你想一下?是不是要使用DNS。具体来说,你的电子邮件服务器将向DNS询问王老板的域名的邮件交换记录。假设这个金主爸爸是京东的。那你就要去询问JD.COM的记录。然后,DNS服务器将使用该MX记录答复我们的邮件服务器,该记录将提供王老板的SMTP服务器的IP地址。该IP地址是王老板的SMTP服务器所在的Internet上的虚拟地址。
SMTP具体的工作流程
我们来分解一下SMTP对话的实际工作流程。首先,电子邮件服务器需要通过查询DNS来查找金主爸爸的SMTP服务器的MX记录。一旦获得,邮件服务器将通过端口25尝试建立与jd.com的连接。一旦建立了到jd服务器的连接,jd的服务器就会通过确认(ACK)响应你的邮件服务器。通常,此确认采用SMTP服务器的完全限定域名的形式(220 mail.jd.com)。然后,你的邮件服务器将发送一个ehlo命令。 金主爸爸的SMTP服务器将对此进行确认(ACK)并打个招呼。然后,从命令发送邮件,该命令提供了你的电子邮件地址(MAIL FROM [email protected])。接着,jd的服务器将对此进行确认,并指示可以继续进行对话。已经在监听了。然后,你的SMTP客户端将发送一个收件人命令(RCPT [email protected])。此时,金主爸爸的服务器以250 OK(250 Recipient OK)的响应ACK。现在,你的SMTP服务器希望了解邮件的内容,因此服务器发送了DATA命令。一旦发送了DATA命令,构成正文消息的每一行文本都会被发送到王老板那。为了向王老板的服务器发出已完成该消息的信号,我已经说了我需要说的所有内容,我按回车键换了一个新行,然后输入一个句号,然后再换回另一行。因此,新行,句号,新行。这个就是暗号了。然后,金主爸爸的SMTP服务器回复我的SMTP服务器(250 Message accepted for delivery),让你知道他已经知道了一切。他会传达你的信息。至此,完成了邮件的传递。你的SMTP服务器发送了Quit命令,从而结束了对话。或者,你可以将其视为挂断电话。我画一下图就是这样
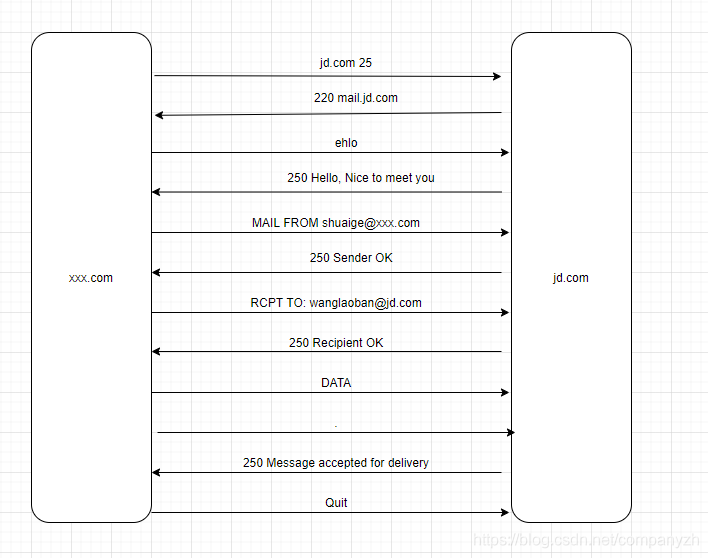
Microsoft Exchange
我们现在来看一个具体的例子呀。outook大家应该都不陌生。那我们就以Microsoft Exchange为例。Microsoft Exchange,简单地说,它是一种服务器端允许客户传递消息的产品。你可以使用Microsoft Exchange发送和接收电子邮件。实际上你可能已经是Exchange的忠实客户,每天都在使用Exchange,甚至可能没有意识到。
假如正坐在办公桌旁工作,并且收到Microsoft Outlook中一位同事的电子邮件,要求你提供有关你正在一起工作的项目的信息。使用Outlook,你可以回复邮件,在午餐期间,你可以继续使用手机与同事回复邮件(不要问我为什么你们不能当面谈,也许你同事是一个漂亮的小姐姐)。但是,整天你都无法获得所需的答案,于是你终于鼓足勇气,安排一次面对面的会议。你创建了一个会议请求,并将你的同事添加到该请求中,你找到了适合双方的时间,然后发送会议邀请。在几分钟之内,你会收到一封电子邮件通知,告知小姐姐已接受你的会议请求。这一切听起来熟悉吗(我们在美国的工作流程是这样的哦)?如果是这样,则你可能正在使用Microsoft Exchange的多个功能。
Microsoft Exchange Server是世界上最受欢迎和功能最强大的邮件服务器之一。普遍用于已经使用Active Directory(如果你做过windows运维的话,你会知道,如果不知道也没关系)架构的企业。你是否用过称为Outlook的Microsoft Office应用程序?Exchange就是支撑Microsoft Outlook这个强大功能软件的背后的那个男人。你可以将电子邮件,日历和联系人通过Microsoft Outlook发送到电脑上,智能手机上,也可以从Web浏览器访问这些项目(如果你做过相关的开发,你就会发现这是一个很复杂的东西)。所以,使用Microsoft Exchange的公司的员工可以从世界任何地方访问他们的电子邮件。无论他们在办公室还是在旅途中,他们都可以进行交流(比如说我可以回中国工作的时候,仍然访问我的邮件)你可以在受支持的Windows服务器版本上安装Exchange,该版本通常位于Active Directory服务器所在的公司数据中心中。
Active Directory
Active Directory是Exchange基础结构中的重要组成部分,你可以使用两个关键工具来管理Exchange环境,这两个工具是基于Web的Exchange Admin Center和使用PowerShell的Exchange Management。 Exchange采用简化的方法来实现高可用性,这意味着降低了实现高可用所需的复杂性。 Exchange与Active Directory紧密结合。没有Active Directory,Exchange甚至无法运行。Exchange使用Active Directory将帐户与邮箱相关联,就像你用来登录工作PC的帐户一样。它使用Active Directory站点来确定将邮件路由到其他Exchange服务器的最佳方法。 Exchange软件使用许多不同的协议来实现传递电子邮件的功能。诸如HTTP和HTTPS之类的协议用于Web服务。 LDAP用于身份验证。然后是几种不同的客户端连接协议,例如POP和IMAP和SMTP。作为Exchange的核心,数据库技术提供了中央存储,可以为用户发送和接收电子邮件进行存储。该数据库还可以在数据库中跟踪会议和其他与日历相关的任务。微软早在1996年就一直公开发行Exchange的第一个品牌版本。这说明Exchange是一款非常成熟且可靠的软件。如果你使用Exchange为用户提供邮件服务,那么只要你设置正确且配置正确,应该不会出现任何的环境问题。
基本上你不做运维的话。你不太会用到powershell,Active Directory等等。我也不知道我是幸运还是不幸运曾经使用过一段Powershell和Active Directory。这也算是一段经历吧。
25 你就是看不见我 - VPN
VPN也许对你很陌生,也可能你很熟悉,不知道你有没有翻过墙?不知道你有没有想要连接公司的网络?如果答案是Yes的话,那你已经对VPN有了第一印象了。
LAN 和 WAN
我如果和你说一个单词-网络,也许对于不同的人来说有不同的意义,就好像一百的人心中有一百个哈姆雷特。如果用户说网络故障了,通常意味着当前使用的应用程序无法正常工作,但是网络本身可能完全可以正常地工作。原因可能只是某些数据库或某些服务器处于脱机状态,导致用户现在无法使用其应用程序。
再举个例子,你也许会碰到过说这台打印机只能在本地网络上工作。这里的网络意义和上一个用户所说的上下文是不同。这里所说的网络其实是局域网也就是LAN。在这里的意思是如果你想使用这台打印机,那么你必须在此局域网上。局域网通常是指一组在Layer 2连接起来的设备。这意味着我们都已通过电线连接到交换机,因此任何通过电线连接到交换机的人都可以使用也在该层连接到网络的打印机。
我们还可以为此添加一个无线组件,以便无线网络或有线网络中的每个都位于同一层网络的设备,都可以使用局域网上的同一台打印机。
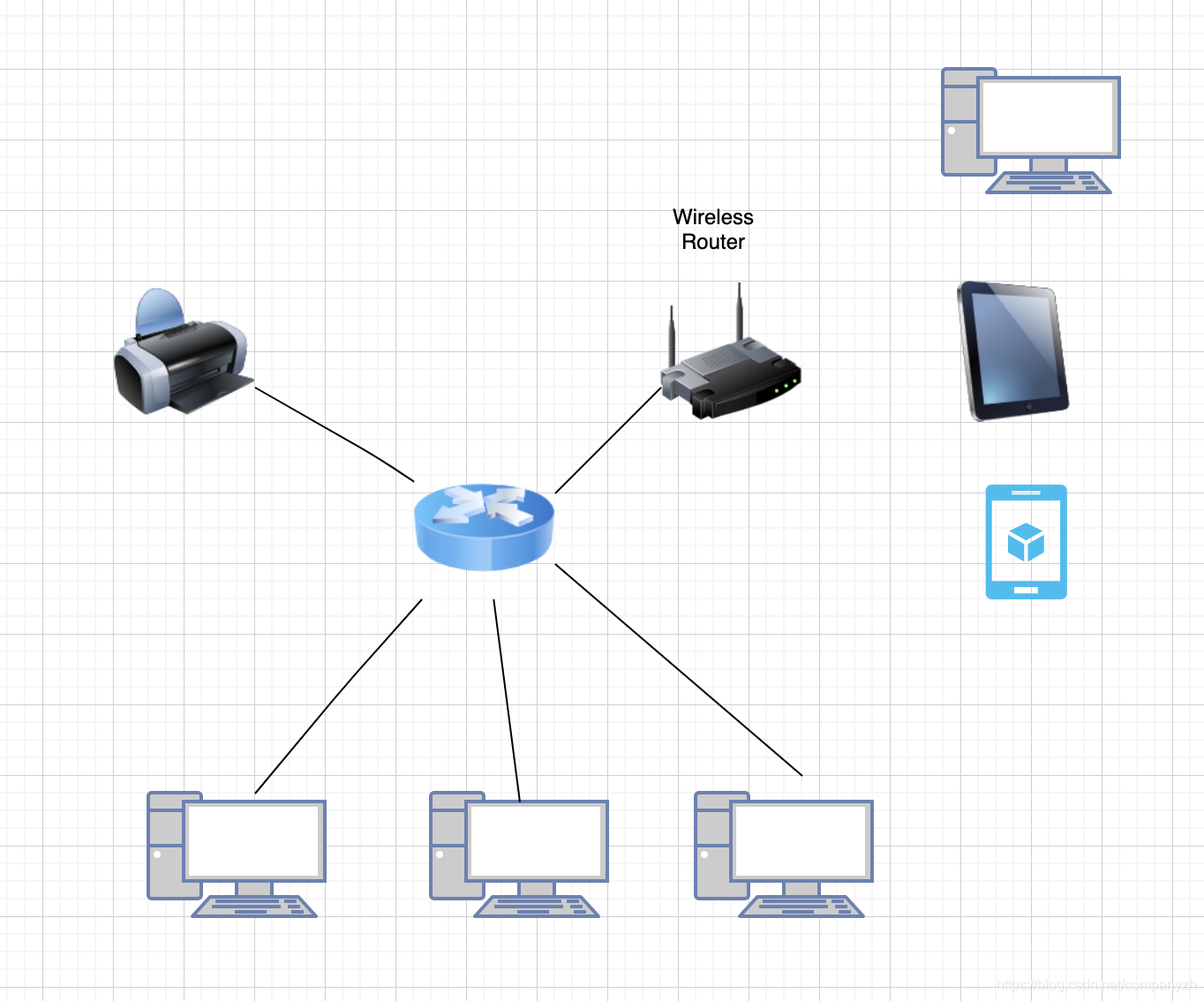
通常,大型公司由许多较小的局域网组成,并且它们全部包含在一个设施,或者都包含在多个设施中。当我们的公司进入某个设施时,很可能会使用某种第三层的设备(例如第三层交换机或路由器)将所有这些区域连接在一起,以便它们可以彼此通信。但是很有可能。如果你在一个足够大的公司,比如阿里巴巴。那么将有不只一个中心可供你连接和使用。也许在杭州有一个办公楼,上海有一个办公楼,数据中心可能在北京,但是不管在哪里,是不是都必须要让所有的员工仍然可以访问该设施。因此,我们要做的是必须在办公楼与数据中心之间建立某种类型的连接,该连接称为我们的广域网也就是WAN。
通常,这些广域网是点对点连接,也就是说连接只有两个端点。一端是办公楼,另一端是数据中心。他们不一定总是要点对点,但通常是这样。在大多数情况下,广域网将成为仅使用两个设备(每个设施中一个设备)的点对点连接。我们的办公楼和我们的数据中心中都存在的路由器,因此我们可以使用三层连接和两台路由器将建筑物连接在一起,也可以使用第二层交换机将两座建筑物连接在一起并在我们两座建筑物之间建立一层连接,这有什么区别?一个是路由连接,一个通常是使用vlan的连接。
广域网允许使用这两种类型来进行连接,路由器或交换机都可以选择。我们可以使用光纤,也可以使用铜缆连接,当然使用Internet本身也可以。实际上我们可以使用Internet作为连接设施的机制,我们也可以使用无线。也许我们可以在每个设施上建立无线连接或两个无线接入点。如果这些建筑物足够近,并且没有障碍物,那么我们实际上可以使用无线方式进行连接。
VPN
我们现在来想一下现在的情况,当病毒横行的时候,可能你去不了办公室办公,就好像我从2020年3月就开始在家工作了。当然平时正常的时候,如果懒了,你也可以在家工作。相信现在基本上每家都有Internet连接。我们可以做的是利用互联网连接,建立从你家里的计算机到网络在到你公司网络的VPN隧道。但是这样隔着万水千山,数据来回传送,会安全吗?
Remote Access VPN (远程VPN)
想法是,我们对隧道中的数据进行加密,这样的话,Internet上的其他人都无法解密并理解和收听正在发送的数据是什么?这就是Remote Access VPN也就是为远程访问VPN。远程访问VPN真正的好处是,不管你连的是哪个网络都没有关系。通常来说的因为某些国家,政府和某些组织实际上会阻止你创建VPN隧道。例如,很可能如果你位于银行网络内部,那么他们很可能不会让你建立VPN隧道,因为他们不希望你窃取信息并通过加密的通道发送信息。但是他们会授权给为该组织工作的用户具有通过VPN发送流量的能力(比如银行自己的员工,所以出事第一调查的就是内部人员,内鬼往往作案的比例很大很大)。
所以,我们可以从外向内构建VPN,无法从内而外进行。不考虑特殊和复杂的环境,我们可以构建VPN隧道,这种远程VPN,可以让用户安全的发送数据,这一点是几乎可以在地球上的任何地方都工作的。也许当你去美国旅游的时候,你负责的项目发生问题了,这个时候只有你能解决,你就必须要远程工程,对不对。这个时候,你需要连接到你在中国公司的网络,你使用的肯定还是美国的Internet,然后在这个Internet之上建立了你的VPN隧道。远程访问VPN只是VPN的一种。
Site to Site VPN (站点对站点VPN)
现在你旅游回来了,回到了北京的当地网络,也许你的公司收购了另一家公司,比如csdn收购了Gitchat。GitChat和csdn在一个完全不同的服务区域中,我们并没有一个很好的机制来建立到从csdn到Gitchat的WAN。我们可以做的就是在该位置定一个高速Internet连接也许是光纤,就像为家庭用户所做的一样(也许你家里就是光纤了,我家就是)。现在csdn的办公室和GitChat的办公室都有光纤的网络了,我们可以做的是在两个位置使用路由器或防火墙建立两端的VPN,这被称为站点对站点VPN。站点到站点VPN的目的是将一个机构的整个局域网连接到另一机构的局域网。这个概念就和上面所讲的有点不同,对吧?因为这里我们不仅有像笔记本电脑之类的计算机来建立VPN连接,我们还建立了某种类型的网络设备来建立VPN连接,而VPN另一端的设备可能都不知道自己连接到了这个VPN。无需使用VPN连接Gitchat就可以像访问常规WAN一样来访问CSDN公司内部的网络了。因此,此处的站点到站点VPN旨在占用整个局域网或多个局域网,并提供回到公司主网络的广域网连接。
VPN加密
我们前面提到了VPN是加密的,所以选择加密和安全协议是规划和部署VPN不能缺失的一部分。这个当然会因为产品的厂家不同和有所差异。在某些情况下,还取决于你选择的是client-to-site还是site-to-site VPN. 这里会涉及一些加密的内容,感觉听不懂或者不感兴趣的同学可以跳过。
对称加密 Symmetric
我们对称密码学开始聊起,在对称密码学中,相同的密钥用于加密和解密,所以叫做对称密码。我们可以在两个不同的VPN端点上以相同的方式手动配置同一密钥,当然你也可以使用非对称的公钥和私钥。在手动配置中,密码短语(passphrase)是经常用于配置的密码(passphrase是满足了一定规则约束的password, 安全性要高一些),当然你必须在VPN的两端以相同的方式进行配置。
一般而言,对称密钥的安全性不如使用非对称密钥。通常将非对称和对称密钥同时使用以提供安全的解决方案。在非对称密码学中,你可以发现解密和加密使用的是不同的密钥(虽然在数学上相关,万事万物都有关联,只是你能不能发现和破解而已)。这是通过公钥基础结构PKI(即数字安全证书的层次结构)完成的,每个证书都包含该证书唯一的数学上相关的公钥和私钥对。这意味着使用公钥进行加密,用私钥进行解密。顾名思义,公钥可以与任何人自由共享,但是私钥必须保密,并且只能由颁发证书的一方使用。在VPN的配置中,需要在每个VPN设备上配置一个PKI证书,尤其是站点到站点VPN的配置。根据解决方案的不同,客户端到站点VPN,你很可能不需要在客户端安装PKI证书。当我们确实使用这些PKI证书时,所有设备都必须信任证书颁发者,这一点非常重要。
IPsec或IP安全不是保护VPN隧道的唯一方法,但它是最常用的,例如L2TP或VPN的第2层隧道协议类型。 IKE代表Internet Key Exchange。其目的是在两个通信方之间建立安全联盟或SA。因此,我们需要在连接的两端都生成相同的对称密钥,而无需通过网络发送,通常使用Diffie-Hellman协议(当然还有其他方法可以完成)。
象我前面提到的,密码学或者安全性是一个特别大和专业的领域,甚至是一个比网络协议要大的多的话题,如果这里你不能理解的话,不要纠结,明白公钥和私钥就可以了。
VPN安全
确保VPN安全适用于VPN的计划,实施,以及客户端如何使用VPN阶段。在VPN客户端,我们应该考虑的配置是禁止保存VPN的Credential(证书)。现在已经21世纪了,移动设备基本上是人手必备。当我们讨论丢失,被偷或损坏的移动设备时,如果这个设备记住了你的VPN证书,则可以从移动设备上获得访问权。如果由恶意用户获得设备,则可以进入VPN并接触许多其他隐秘的内容。
当然还有离线的密码破解工具可以用在保存了VPN证书的设备上。所以取决于VPN客户端以及否保存了密码讲确定潜在问题的严重程度(也就是通常所说的潜在安全问题)。我们还需要考虑公司VPN的使用政策,以及有关如何使用VPN的任何文档。这通常是新员工入职的第一课,用来确保你是否知道在什么地方以及什么时候可以使用VPN。我们还应该考虑VPN甚至是Web浏览器的指纹识别或其他识别方式。例如,可以通过检查传输的IP地址来间接检测是否正在使用VPN。所以,当我们通过VPN时,传输内容会通过VPN隧道进行加密或保护,但随后会在VPN隧道的另一端被解密,因此这个内容或者流量可能来自该VPN设备。
另一个注意事项是登录VPN服务器或VPN设备。在企业中,我们通常会保留日志用来日后的审核。还有VPN的一些最佳配置做法包括修改VPN身份验证超时。我不是建议你去增加或减少超时时间,你应该根据特定的解决方案和平均网络速度来配置,因此你要确保身份验证超时不会太长,以便用户知道如果他们是不是要尝试从设备(例如密钥卡)中重新输入密码。
理想情况下,应在每一个IT解决方案中使用Multifactor(多身份验证),而不仅仅是VPN(比如AWS,就会因为没有Multifactor的设置,是有安全隐患的,还有Github等等,我相信阿里云,腾讯云等会有相应的设置)。Multifactor之所以在VPN中尤其重要,是因为VPN可能允许外部设备访问内部受保护的网络和信息,所以我们要最大程度地去保护它,使用多因素身份验证需要使用多个安全类别来识别你就是你。
除了用户名和密码这种传统的单因素身份验证,我们的VPN还要求使用密钥卡,该密钥卡具有与VPN同步的数字更改代码设备(比如有一个App叫做Authenticator)。下一个需要配置的应该是启用帐户锁定,以便在多次错误登录尝试之后,将该帐户锁定,并且这些特定值需要根据环境来确定,因为它需要与你公司的安全策略保持一致。对于任何类型的配置,无论是Windows,Linux主机,移动设备,网站,还是我们现在讨论的VPN,理论上都不应该使用默认设置。我们应该始终更改默认设置,以使其更难以受到侵害,减少潜在的危险。
互联网上的许多人都使用个人VPN匿名服务器App。比如,学校的孩子可能会在智能手机上使用VPN应用程序,这样即使学校的防火墙可能阻止了某类网站的连接,他们仍然可以连接到Facebook(美国孩子不好管呀)。通过使用个人VPN匿名服务器App,真正发生的是流量被隧道传输到其他地方的服务器,并且从那个位置开始在连接到其他地方。
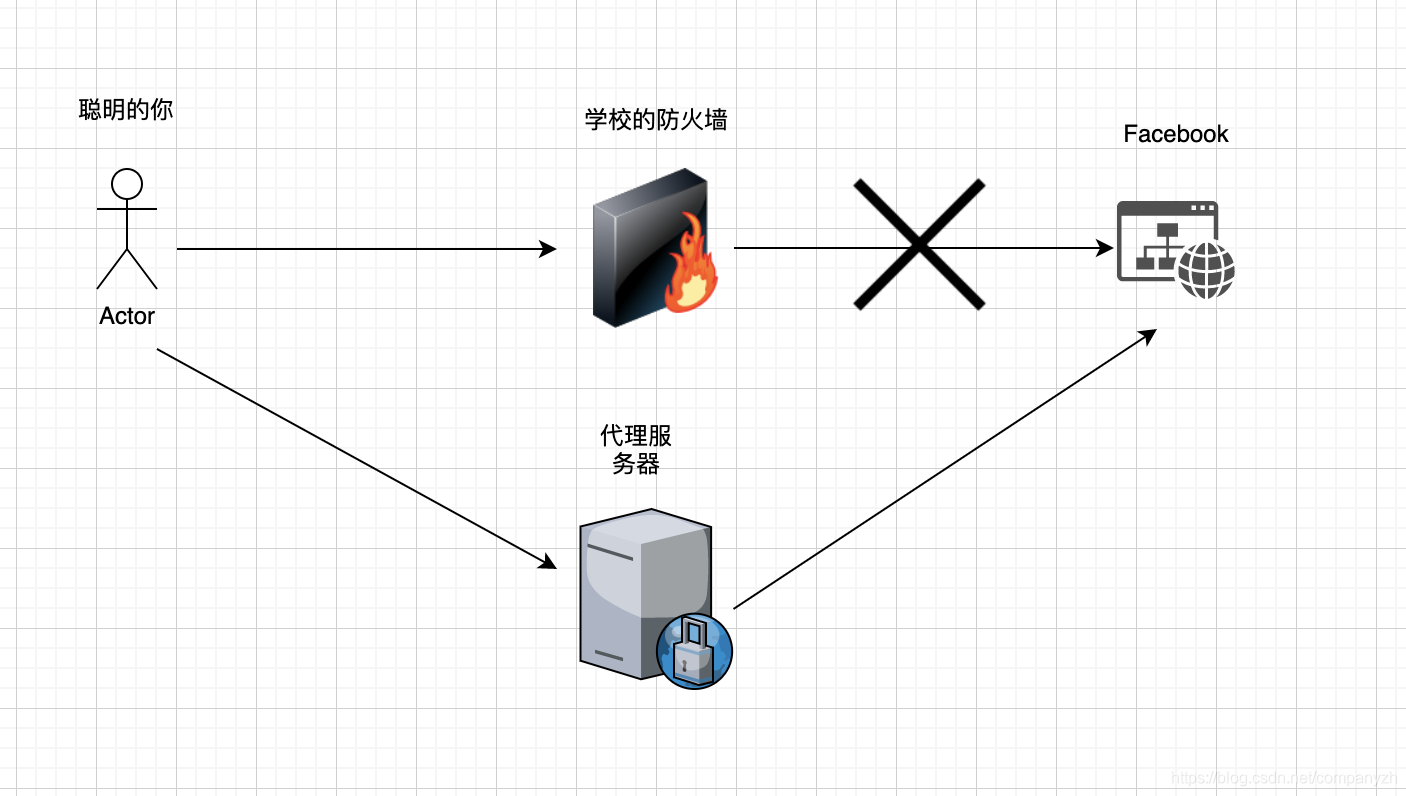
26 黑客的好帮手 - SSH
通信协议
我们今天来谈论一下SSH,Secure Shell和Telnet,这是两种广泛使用且非常有用的基于UNIX和Linux的远程通信协议。
首先来看一下基本的概念,通信协议是一组公认的规则,用于建立同步方法和通信会话的各方将使用它们来管理其交换。广泛采用的协议允许硬件制造商设计能够与其他网络设备和软件开发人员进行可靠通信的产品,以满足他们的软件可能面临的连接需求。开放系统互连模型OSI是网络连接的通用且有用的概念,它将整个过程分为七个不同的层,这是我们最开始就讲过的。例如,如果我在访问Internet某个站点时将JPEG图像加载到浏览器中,则该图像实际上是由浏览器加载,并且使用户(在应用层上)可理解,即第7层。在表示层(第6层)上,图像已转换为浏览器的可读格式,在该层进行了诸如加密和媒体文件处理之类的数据转换。通过HTTP协议,在第5层(会话层)上管理我的计算机与远程Web服务器进行通信的正在进行的连接本身。 SSH和Telnet也在第5层上运行。虽然会话本身由第5层维护,但实际上并没有执行任何操作。你可以将其视为没有人说任何东西的电话。因此,将JPEG文件获取到我的计算机时,将需要使用TCP协议在传输层的会话之上进行数据传输。第三层,即网络层,是由诸如路由器或IPv4和ICMP协议之类的设备组成的基础结构,可实现地址分配,网络节点之间的路由以及对移动网络流量的控制。当我在浏览器的导航栏中键入网站URL时,将请求实际路由到Web服务器主机的过程是在第3层上完成的。一旦知道了数据包的目的地,则数据链接层将负责数据帧和数据包的实际传输。处理接收确认。这些帧的流在通过以太网或PPP等媒体传输时,可以在它们的目的地重组为单个资源,例如我耐心等待的JPEG。最后,数据传输本身以某种电,光或无线电信号的形式通过物理层上的网络介质(如电缆或Wi-Fi)进行传输。然后,每个数据包将以某种方式通过我的客户端计算机上的各个层进行定向或转换,但顺序相反。正如我前面说过,OSI模型是一种工具,用于可视化和阐明参与网络通信的每个组件的作用。当然这个不是本节课的重点。我们还是来把焦点放在SSH和Telnet上。
OpenSSH
Secure Shell程序是一种协议,可让你在任何基于UNIX的服务器上打开远程终端会话,在该服务器上,你可以根据登录帐户可用的权限执行命令。与其他远程连接工具(包括Telnet)相比,SSH的主要优势在于,你在此会话期间所做的所有操作都将被加密,因此,可能在你与远程主机之间的任何时间观看的任何人都只会看到不可读的文本。使用相同的基本过程,你还可以使用SCP在节点之间安全地传输文件,并且在服务器和客户端计算机上适当地编辑了配置文件后,也可以在远程主机上安全地启动GUI应用程序。
SSH使用起来可以说非常的简单实用,SSH可以在Windows 10计算机上本地使用。 SSH的验证方式有以下三种
- RSA rhost authentication。如果远程主机包含名为任一主机的文件,则RSA rhost身份验证起作用。如果这些文件中的任何一个包含标识客户端计算机及其当前用户的条目,并且主机服务器已经具有客户端主机密钥的兼容条目,则将允许登录。如果这些文件都不存在,并且很大程度上是由于Rhost系统本身内部的结构缺陷,那么默认情况下通常会出现这种情况,则客户端上运行的SSH程序将向服务器标识其想要的本地加密密钥对利用也就是第二种方式。
- /etc/hosts.equiv
- /etc/ssh/shosts.equiv
- /home/username/.rhosts
- /home/username/.shosts
- Private/pubic keypair authentication - 你首先需要一对密钥。如果还没有,则可以生成一个密钥对。使用ssh-keygen程序在Linux客户端上用户主目录中的ssh目录(.ssh)- 目录名称前面的点告诉Linux,这是一个隐藏文件,只能使用带-a标志的ls才能看到。ssh目录可以存在于任何单独的用户目录层次结构中,系统的etc目录下还有一个SSH目录,其中包含密钥对和两个配置文件。ssh_config文件确定该计算机在默认情况下将如何充当其他远程计算机上的客户端,而sshd_config文件将其行为作为远程客户端访问的主机的主机进行控制。
- SSH user keys location - /home/username/.ssh
- SSH system keys location - /etc/ssh
- SSH configuration files /etc/ssh/ssh_config 和 /etc/ssh/sshd_config
- Password authentication。如果前两个身份验证选项都不起作用,则服务器将提示客户端输入密码。出于安全原因,最好避免依赖密码。这对于SSH协议版本1和更现代的SSH协议版本2都是很常见的。此外,版本2还支持RSA,DSA和OpenPGP公钥算法
Private/Publlic Key 详解
如果你接受ssh-keygen的默认值,它将创建两个文件分别称为id_rsa和id_rsa.pub。第一个文件是该对文件中的私有文件,应谨慎对待,并且永远不要暴露于不安全的网络中,例如将其作为电子邮件附件发送。通常,你将私钥保留在计算机上。系统将提示你创建一个密码短语,每次尝试基于密钥的远程登录时,本地计算机都希望你输入该密码短语。我将创建一个密码短语
我将公共密钥打印到屏幕上。就是长这个样子的。

我将内容(仅内容)复制到剪贴板。登录到我要为其设置基于密钥的登录的计算机。转到.ssh目录,打开文本编辑器的authorized_keys文件,然后将我们之前复制的公钥粘贴到新行上。现在,回到我们的客户端计算机中,我再次输入ssh 地址。这次无需输入密码即可直接进入远程计算机。除了使我不必每次登录时都记住和输入密码外,它的一个显着优点是,我们可以避免通过尚未得到保护的连接来传输密码本身。
我相信你应该会有疑问,那这整个密钥交换实际上是如何工作的呢?

当你的客户端计算机发送其打开新会话的请求时,服务器的SSH程序将发送一个随机数字,该随机数字已使用客户端的公共密钥进行了加密。如果客户端可以使用自己的私钥解密该号码,则服务器将允许你启动会话。
SSH Debugging Tool
如果你希望看到SSH过程的每个步骤,你可以继续的看下去。主要目的还是可以在出现问题时进行调试,请尝试在命令中添加详细的-v命令。
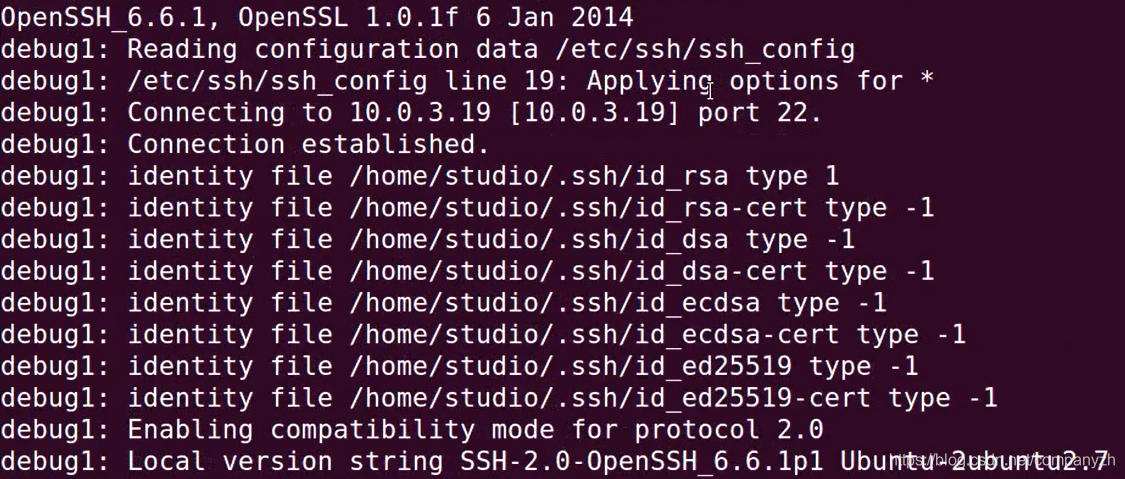
上图只是一部分的详情,不是全部信息。第二行我们可以看到SSH如何读取系统范围的ssh_config文件以应用其配置,然后与远程主机建立连接。
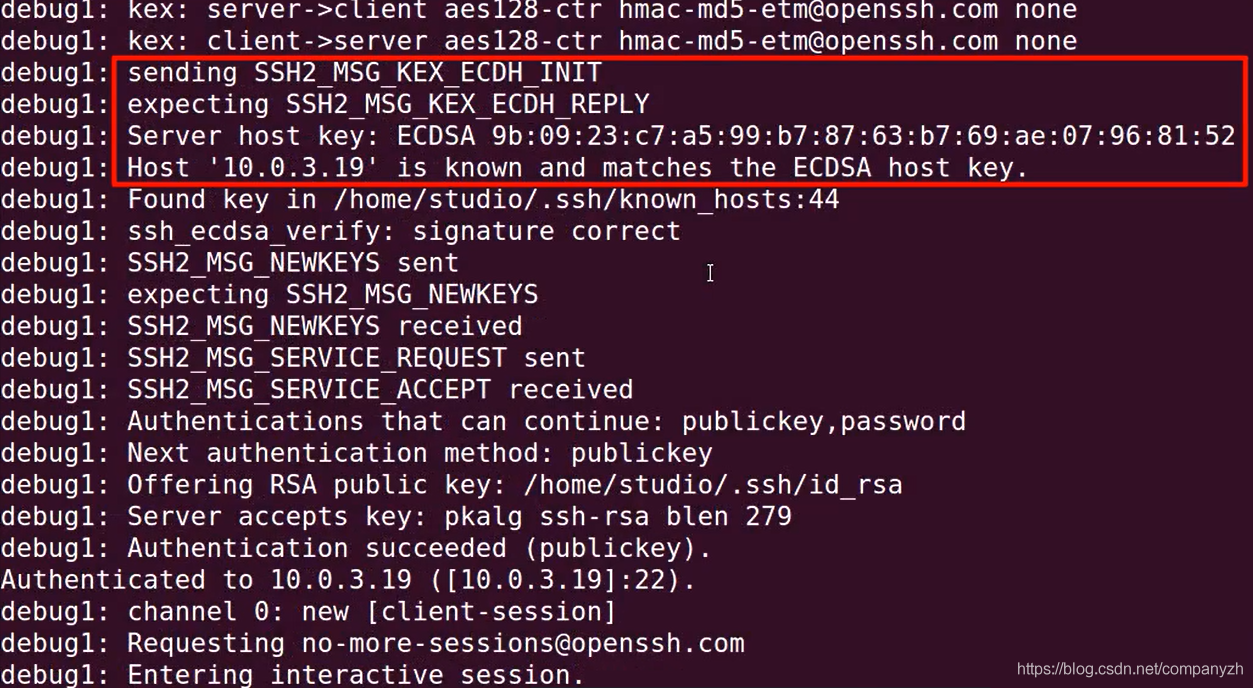
接着,SSH会在客户端的主目录中清点可用密钥对,并且由于没有其他指示,因此在本地和远程计算机上均启用SSH协议2。然后,SSH会接收服务器主机密钥,并对照与客户端的known_hosts文件中的主机IP地址相关的任何密钥检查它。
接下来,由于我们已经将客户的公共RSA密钥添加到主机中,因此我们被告知我们的RSA密钥已被接受并且会话已启动。最后,建立了会话环境设置,“欢迎我们参加新的会“。你也可以使用Wireshark协议分析器工具从网络上的任何位置查看相同的过程。在Linux上,你可以按名称从存储库中简单地提取Wireshark,但是对于任何操作系统而言,它都是易于下载的。通常,由于大多数与Internet连接的计算机都会发送和接收大量网络流量,因此Wireshark显示的流量是一种非常有用的方法,可以帮助你了解所看到的内容。我们的专栏就不讲wireshark了。
基本调试
我们来探讨一些常见的SSH意外以及修复它们的方法。
- 首先,客户端和服务器上是否都正确安装了SSH?

如果从客户端计算机运行SSH返回“拒绝连接”错误,则可能值得检查服务器上的SSHD状态。以我的经验,当你使用一种或多种虚拟机时,这是一个特别常见的问题。只需几个命令就可以立即配置和启动容器或群集节点,因此很容易因疏忽而错过了您需要的基本工具(例如SSH服务器)的安装。
- 出现“无主机路由”错误可能表明服务器本身甚至没有运行。

这通常是一个相对简单的问题。”没有主机路由”消息也可能表示你的网络连接有问题。所有明显的连接故障排除步骤都可以试一下,包括对远程服务器执行ping操作;如果失败,则对你知道的服务器进行ping操作,例如8.8.8.8。这是Google的DNS服务器。当然你可以试着去ping百度的。你还应该检查自己的网络硬件,包括电缆连接,交换机和路由器,当然,也包括为远程服务器提供服务的硬件。如果所有检查都成功了,但仍然无法连接,请确保没有任何服务器或客户端防火墙规则阻止流量。记住默认的SSH端口是22,请尝试对本地网络接口和远程主机地址之间的端口22流量运行tcpdump。在这里,-n告诉tcpdump以其原始格式显示IP地址,以便我们可以在输出中更轻松地识别它们,-i指向我的本地网络接口。你可以在服务器上运行netstat-rn,以确保U根和G(使用网关)标志都已启动。如果有什么阻止你,则需要查看当前的防火墙设置。
27 你可以得到我的心,却得不到我的人 - 物理安全设备
从这一章开始,我们要开始讲解和介绍网络安全。我们先来看一下物理安全设备,可能这个是最被大家所忽视的一部分。因为基本不会有哪一门课会讲解这个。让我们来一起开始吧。
视频监控
提到视频监控,我相信大家都不会陌生,当然有好的有坏的,比如某些你上的网站(你懂得),我就不说了,还有我们马路上的监控,商场里的监控等等。如今,摄像头已经变得非常便宜。其实我们大多数人都会随身携带一个摄像头(你的手机),这在15或20年前是完全闻所未闻的。另外,你也在网上可以购买连接网络或者无线网路的摄像头,而这在过去10到20年中是没有的。当然这也促进了很多产业的发展。这意味着企业可以更有效地监控企业发生的事情(保护安全,以及预防危险等等)。另外,现在也已经建有非常健壮和有效的数据网络,需要大量的存储空间,这使我们可以保存很多视频。
此外,我们也完全可以以相对较低的价格购买适合自己房屋的摄像头(价钱还是会决定一切)。比如在我的车道上有一个摄像头,用来监视会不会有人来试图打开我的车门,将零钱或者其他物品从车上拿走,所以我在那儿装了一个小摄像头,以便发生意外的时候,知道是谁以及什么时候发生的。当然这些都是小事情,你也很可能会在公司的极为敏感的领域IT部门使用摄像头,例如在数据中心等地方,以便知道谁在数据中心中以及他们正在使用什么设备。使公司可以确定在其中从事工作的人是合法的管理员,还是什么可疑的人在用设备做些对公司不利的事情(不知道你听没听过,数据是未来的核心竞争力,当然我们这里不是讨论数据)。你还可以使用视频记录来查看谁在何时进行了操作。对于数据中心来说,这是一个性价比非常合适的选择。你当然还可以安装运动检测器,并且运动检测器可以帮助处理各种其他的事情。比如,如果有人在数据中心的某个区域,或者他们可能在某个机柜中打开,它可以发出警报。我们可以将这些运动探测器放置在我们想知道某个人何时在某个区域活动的区域。比如我前面说的车道上的相机也可以是由动作启动的,也就是说监控并非一直在记录。如果没有任何动作发生,它只会闲置在那里。一旦有人经过摄像头或在摄像头附近行走,那便是摄像头开始记录的时间,这也使得我们可以节省一些空间(虽然硬盘已经很便宜了),并使监视和回放这些视频文件更容易一些。
资产追踪
在大多数企业中,你会发现资产跟踪可能会从会计部门开始。你可以使用某种类型的资产跟踪标签,通常就是一个非常简单的标签。上面要贴上你公司的名称,比如CSDN。它经常有条形码和与之相关的数字,公司会将这些标签贴在公司的资产上比如笔记本电脑。在美国还有税务的问题,这里就不讲了。比如刚才讲的标签贴在笔记本上,公司能够扫描该标签(比如什么时候设备寄给你,什么时候你还回去)。一般会将标签贴到有价值的东西上,比如笔记本电脑,PC,平板电脑或其他具有实际实际价值的设备上。你不会找到附在钢笔和铅笔上的资产标签,因为它们的价值非常有限,不值得追踪这些东西。但是任何具有实际价值的设备都将获得这样的标签。此外,当我们尝试对设备进行故障排除时,你也可以使用这些资产跟踪标签来帮助跟踪设备的位置。比如现在你在家工作,如果电脑出现任何问题,你可以使用标签致电公司的support部门。也许该标签还与公司的特定地理区域相关联。最后,当我们谈论公司资产时,公司不希望用户在不需要设备的情况下对其进行篡改。因此,有时在出厂时,你会看到一小段胶带被安装在设备上以进行篡改检测。比如电脑上会说:”如果这个胶带被打开了,保修将失效“。或者,有时也可以在设备上加锁。比如你家里的煤气表或电表上会看到小锁,它只是一个篡改证据锁,通常嵌入某种塑料的金属丝,很难拆开再放回去。这样它就可以用来检测系统是否遭到篡改。这种篡改检测是技术人员确定是否有人已经在尝试破坏设备的方法。
设施使用
接下来,让我们讨论一下设施访问和使用,我们来讨论一下如何授予需要访问某些房间的个人访问权限,这些房间中通常会装有许多昂贵和重要的设备,例如我们的数据中心。因此,我们要做的是将某种锁放在该门上,然后分发与之相对应的锁。(不知道你公司有没有呀,就是有一个电子锁,然后给你一张卡,你可以扫那个卡去开门)。其实将物理钥匙分发可能会出现问题。有的公司会使用同一把钥匙或者门卡,这个卡可以打开公司的任何一扇门。你能想象一下,如果这个卡或者钥匙丢了,公司是不是要去换了所有的锁(门卡的话,现在通过程序可以解除其权限)。因此,现在取而代之的是,通过设施访问,我们经常会使用某种类型的智能卡,也许是你的ID徽章,其中内置了一些电子设备,可让您通过某种类型的垫板对其进行扫描,如果你的门板打开了,徽章被确认可以进入该设施,所以我们有这些卡可以给我们访问。这也带来了一些安全问题,因为它上面可能贴有你帅气照片和名字,其实这个还是会有安全隐患,比如说你卡丢了,你一般不会第一时间发现,等你发现了在通知IT部门,在去换卡,这期间会有很多的可能性,比如有人可以捡到或者偷了你的卡,然后冒充你来进入(玩过HITMAN的人基本都知道吧)。随着科技的进步,我们也在渐渐的解决这个问题,这就是为什么我们可能要引入某种类型的生物特征识别扫描的方法,例如指纹读取器和眼睛扫描,面部扫描或手掌扫描,诸如此类的东西将有助于增强对安全设施的访问权限。但是,如果你和我一样是标准的电影脑残粉,则可以通过生物识别技术做一些令人作呕的事情,以解决这一问题。例如用某人的手指以用作指纹验证或以某种方式获得某人的眼球以用于视网膜扫描。有许多公司将提供技术来帮助抵御这些无用的生物识别技术的破解(我确实很喜欢阿里巴巴,技术确实领先,还记得脱口秀大会上,颜怡颜悦说她们双胞胎只解开过一次人脸识别)。当然,现在的技术发展的真是日新月异,比如我现在的车,有一个电子小钥匙。我只需将钥匙放在口袋里,然后走上车就可以启动汽车,而不必像以前那样将钥匙真正的插入点火装置中。
总结一下,我们研究和探讨了一些具有IT物理安全性的东西。我们谈了一些有关视频监控的内容。我们讨论了资产跟踪以及如何使用一些标签来帮助我们创建组织中所有资产的清单。最后,我们讨论了设施访问以及如何使用徽章,生物特征识别,智能卡等等,或者只是普通的老式物理锁来保护我们的设施免遭未经授权的访问。
28 你怎么证明你就是你 - 身份验证和访问控制
AAA
我们先从AAA开始(你一定很迷惑,什么是AAA)英文就是(authentication, authorization, and accounting)- 身份验证,授权和审计。我们先来看一下身份验证部分。
- 身份验证就是你的用户名和密码。你输入用户名和密码以后,以此来获得进入的权限。没有此处的第二个组件,用户名和密码显得有一点毫无意义那就是 - 授权
- 授权就是你的特权和访问权限。换句话说,也就是在你登入的系统中,你可以访问哪些软件,你可以访问哪些文件共享,你可以访问哪些计算机和服务器?因此,你的用户名和密码与授权信息是相关联的,从而告诉你可以访问的内容。
- 从审计的角度来看,这里的最后一个组件很重要,你试想一下,如果出现问题,我们需要对问题进行故障排除,比如员工有没有按照预期的方式行事,我们会去将审查谁在何时何地做了什么;这就是这里的审计部分。
所以我们有了身份验证,那就是我们的用户名和密码;授权,该用户有权访问什么;最后是审计,该用户做了什么,他们什么时候做的?因此,AAA身份验证就是这样。它是用户名,访问权限以及它们所做的记录。有两个组织支持在现代网络中使用的AAA服务器。思科是其中之一。它称为(Terminal Access Controller Accesses-Control System Plus)- “终端访问控制器访问控制系统Plus”或简称为TACACS。
身份验证
我们在这里来对身份验证进行一下深度研究。有本地身份验证,可以在其中对工作站本身进行身份验证。在家用设备中,如果你在家中有一台计算机或笔记本电脑,你最有可能通过无线网络将其连接到Internet,但是你可能没有要连接到服务器。此处的本地身份验证只是用户名和密码,使你可以直接在本地计算机上访问资源。一般会被分为两类-管理员和普通用户。与管理员相比,通常普通用户只是具有查看的权限,而管理员具有在工作站上配置的权限,尤其是对配置文件(这个很好理解,不需要解释呀)。
本地的身份验证只适用于用于本地工作站本身(比如你电脑的登录,输入的用户名和密码只是针对你的笔记本)。域名(Domain)身份验证意味着我们将登录一台要加入某种Domain的计算机。通常是使用Active Directory,这意味着我们将用户名和密码发送到domain控制器。然后,域控制器会将我们的设备添加到该domain中。当我们将设备连接到域控制器时,我们将使用称为Kerberos的协议来做(该Kerberos协议是开源的),由MIT及其包括IETF的联盟开发。 Kerberos所做的是对通信进行某种加密,以便当我们向服务器发送用户名和密码时,对通信进行加密,这就是这里的组成部分之一。另一个组件是确保发送用户名和密码的计算机是他自己,而不是在该网上其他试图假冒该设备的其他设备。因为这里可以进行某些类型的中间人攻击,即侦听设备和服务器的通信,然后稍后将通信重播回服务器,以欺骗服务器。Kerberos是服务器和客户端验证其身份的一种方式。除此之外,它还会加密该通信,以允许该用户名和密码成功到达服务器,对其进行验证,以查看是否允许该设备加入domain。
当你需要使用域身份验证时,或者是你早上准备开始工作了,打开你的电脑,输入用户名和密码来登录。这将与域控制器进行核对,以验证你是谁,并允许你登录并访问设备上的应用程序。现在,假设你在会计部门工作,并且需要使用一些会计软件比如QuickBook,并且这个软件的依赖位于我们数据中心中的服务器。这里的问题是,在大型公司,你每天都会使用很多不同的程序。你可能有一个内部网站和电邮。你可能会使用特定的专业软件,例如刚才提到的Quickbook,你可能还会使用某些绘图软件等等。可能需要使用许多很多软件(大公司就是有钱,全是买license)。这些软件中的大多数都将具有某种身份验证系统,要确保只有你才能使用该软件,该软件会阻止那些很熟练的程序员或其他工种,但是不是会计的人。这就是术业有专攻,你不是会计,不要动我的软件。因此,我们一般会使用一种叫做LDAP的东西。现在,LDAP已内置到Microsoft Server系统(特别是Active Directory)中,它允许我们执行的操作是允许我们将用户名和密码发送到我们的比如会计软件。然后,这个软件服务器会说“嘿,Active Directory”,该用户是否有权使用这个软件?如果是的话,说明此用户已被授权,然后该用户就可以登录到这个会计软件。
以上的例子其实很接近于所谓的单点登录(现在单点登录很火呀)。单点登录是一个很重要的概念,因为这意味着我只需要知道一个用户名和密码。这就和你的个人生活有一点不同,比如在我的个人生活中,我需要我的Gmail帐户密码,我的netflix的帐户密码,我的Facebook帐户密码,我的HBO账户,我的银行账户等等。对于所有不同的系统,我都需要所有不同的用户名和密码(你可以一个密码走天下,但是会不安全),并且没有一种很好的方法将它们统一在一起。 Facebook和Google对其单点登录产品进行了一些尝试,但是效果不是那么好。可是当我们在企业中使用时,效果就不一样了。用户只需要知道一个用户名和密码,就会感到非常满意。此外,它还提供了无与伦比的安全性,因为你不再被迫去创建许多密码,并且还需要记住许多不同的用户名和密码的组合。
你想一下这里是不是有一个小问题,那就是假设用户名和密码遭到泄露,是不是意味着拥有该用户名和密码的任何人都可以将设备加入网络中的domain,这样会不会危险。因此,我们可以采取的预防措施之一是向网络上的设备颁发证书。在设备联机时可以通过将证书的一部分发送到域控制器来验证它是否属于这个domain(我喜欢用英文单词在这里,中文的翻译总感觉有一点点变扭)。域控制器可能说,是的,此设备在我们的网络上有效,是自己人,放进来把。这比仅使用用户名和密码来使设备加入Active Directory域要好一些,因为现在Active Directory域控制器必须专门为我们要加入domain的设备颁发证书。因此,我们使用证书和一些凭据在此处登录。这将防止有人携带自己的设备并将其加入domain。这就好比什么呢?比如说天地会的密码是”天王盖地虎,宝塔镇河妖“,是不是每一个知道这个口号的人都是自己人呢?不一定吧。你只要偷听到了就会知道,但是你有一个证书,上面陪着你的照片,这样是不是就不好蒙混过关了(可能有同学会说这样还是有漏洞,不要抬扛呀,任何软件和方案都有安全问题,只要你钻研,都能攻克,只是简单和难得区别)。我们通常会为无线设备使用基于证书的身份验证。这也确实非常有效。
日志和审核
在AAA中,最后一个就是审核,日志是属于审核的一部分。我们需要记录所有的traffic,这使我们可以在将来审核这部分。美国有一个法律那就是关于美国健康法的一部分是,医疗记录系统的用户不得查看不在其直接护理下的任何患者的健康信息。比如你在医院工作,发现蔡x坤是你的病人,你有接触病历软件的权限,你可能想了解阿坤怎么了。可能是出于好奇。可能希望将该信息出售给某家机构来引起轰动。所以,如果让你来设计这个审核来防止这种情况发生,你怎么做呢?设计目的是使我们能够准确的记录谁在何时何地做了什么;然后出现问题的时候,可以审核然后说,那个人这样做是对的吗?
多因素身份验证
我前面应该有提到过这个,我们现在来细谈一下多因素身份验证。现在是我们有史以来第一次能够真正实现多因素身份验证的年代。尽管仍然存在很多挑战,但比以前要好很多很多。多因素身份验证,这个想法是收集有关你的东西,与你有关的东西。因此,我们在这里需要做的一件事情是,你知道的事情,你拥有的一些东西,你是谁,你在哪,你在做什么。让我们看一下其中的例子。所以你知道的事情在这里可以是你的用户名。自定义ID一般会是你的电邮地址,因为用户名通常是你的用户名,而电邮地址一般都是公开的。所以,公司不希望你的用户名成为唯一的标准,这就是为什么我们还需要添加密码。因此,你拥有或者说知道用户名和密码,这就是我们对用户名和密码的单因素身份验证。这是我们知道的东西。我们可以通过添加我们拥有的东西来增强它。我们使用了一些我们知道的东西,例如用户名密码,我们还可以添加一些我们有的东西,比如钥匙卡,钥匙扣,某种类型的数字生成器,甚至可以是我们的智能手机。因此,我们在这里所要做的就是输入用户名和密码,然后可能还要刷智能卡。在银行工作的同学可能会知道,员工会得到一些小的安全身份证,这是一个随机生成数字的小设备。因此,每隔30秒左右会弹出一个新号码,然后你将使用该号码以及用户名和密码来在系统中进行身份验证。因为生成的数字有些随机,很难预测。我们也可以使用智能手机来做同样的事情。还记得我前面提到的一个App(Authenticator)。当我们要登录到系统时,我们可以请求我们的代码登录。然后,我们登录到系统中,可以输入我们的用户名,密码,然后还有就是这个App里的一个数字。这里的想法是你的用户名和密码就是你所知道的。如果有人出于某种原因得到了这些密码,也许你写下了你的用户名和密码,然后又有人从你那里偷了密码,则可以使用第三种身份验证方式。
因此,窃取你信息的人将无法登录,除非他们有此第三因素。我们可以在这里使用的另一种东西就是你自己。这可能很简单,例如指纹,脸部扫描,视网膜扫描,手掌扫描。通常,这将是某种生物特征识别,而你很难复制给其他人。因此,也许你会再次输入用户名,密码和指纹。智能手机使用指纹读取器。有时,指纹读取器仅用作身份验证的一种形式。这有点危险,因为如果有人可以访问我的指纹并能够复制它,那么他们实际上可以在我的手机上进行身份验证。但是手机上还有其他应用程序需要更多,并且还需要用户名,密码和指纹才能进入。这里的另一个因素是你所在的地方。我马上想到的一个例子就是这项技术,我知道苹果称之为HomeKit。你可以做的就是在你要为自己做某事的地方使用它,比如你在自己的家中,你可以使用智能手机打开锁。这里是不需要用户名和密码的。从字面上看,它将只是在你所处的某个地方,你所拥有的某个事物以及你是谁。可以你你在家附近,拥有你的智能手机,并将指纹放在智能手机上。然后,这三件事加在一起就可以解锁你的房门。因此,在某个地方,您可以将自己拥有的东西和自己所有的东西结合起来使用,例如做一些事情,例如打开房屋的门,或者在回家后打开室内的灯。
29 我要怎么藏好我的考研资料 - 网络攻击(一)
漏洞和漏洞利用
我们今天来开始看一下漏洞,我之前就有提到过,其实漏洞是到处都存在的。我现在以我的房子为例,从安全角度来看,我的房屋中也存在一些漏洞。谁家都有窗户对不对。就是那种玻璃窗,其中一些在房子前面,这些玻璃很容易损坏。每天都会有成百上千的人在我家前面走过,但是没有人利用该“漏洞“并为其创造漏洞利用程序。 那什么叫做漏洞利用(Exploits)?漏洞利用就是有个人走过来说:这房子很容易进入呀,然后拿起一块巨石,扔进我的窗户。这个时候,这个石头已经成为了一种攻击,对不对?石头利用了我的窗户是玻璃的的这种漏洞。因为我的窗户很脆弱。它是在内部和外部之间建立了屏障,但它也很脆弱,可以通过利用石头和坚硬的物体来加以破坏。在计算机上,这个道理是类似的。因此,每当你打开计算机并将其连接到网络时,Microsoft Windows这样的操作系统都会去尝试连接到其他Microsoft设备。另外,我们还可能在我们的工作站上运行其他软件应用程序,所以你会打开某些端口。
我们来看一个例子。来了解我们的工作站可能发生的某种类型的漏洞。我们会使用netstat来做演示。(netstat会显示你电脑上正在侦听的所有端口)。
netstat
我们来看一下netstat这个指令呀。Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。 Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况 (这是百度百科搬过来的) 常见参数
1 | -a (all)这个大家应该都知道吧,一般-a都是显示所有。 |
我在这里使用的是 netstat -ano, 出来的结果就是下图这样。
可能你咋一看会觉得这么多信息,是不是有一点不知所措,没惊慌呀。我们来一起看一下这个结果,先看一下TCP部分。还记得TCP的工作原理吗,前面已经分析的很详细了。这里就不多说了。我们来看一下第一行。第一个协议就没什么说的,指的就是TCP,就好像netstat上面的选项可以是只显示tcp。第二个是Local Address(本地地址)- 0.0.0.0:135。除了极少数例外,0.0.0.0指的是所有地址。这里指的是在此工作站上的任何本地地址,都在端口135上侦听。如果进入此工作站的数据包的源IP地址是网络接口适配器可以接受的任何地址,并且目标端口号是135,则此设备将允许进行该连接。它将接受SYN消息并以SYN-ACK消息进行回复。再看一下第三列也就是Foreign Address(0.0.0.0:0)它将针对在任何端口上运行的任何IP地址执行此操作。0.0.0.0是任何IP地址,此处0:0的端口号表示来自远程设备的任何端口号。所以,这里指的是我的工作站正在侦听端口135上的TCP SYN消息,并且这里的状态为LISTENING,我们只是在等待这里发生的连接。关联的进程ID就是最后一列的数字也就是进程ID1120。如果你打开windows的任务管理器,你可以找ID1120,你会看到这是一个windows的程序即-svchost.exe。这是Windows服务的主机进程。如果你感兴趣的话,你可以查一下所有Local Address是0.0.0.0:xxx的,你会发现,这里都是Windows进程。
当然我们也正在监听UDP连接,UDP没有三向握手,但是UDP在这里仍然有一些实用程序,而Windows具有监听各种进程的功能。我们也可以在此列表中创建不是基于Windows的进程,比如你可以做一个小实验,去网上下载一个TFTP服务器Tftpd64。这是一台小的TFT服务器,它可以免费下载,下载之后,你可以直接打开这个tftpd64.exe。然后你再次执行netstat -ano,在UDP部分你可以发现有一个新的连接在监听0.0.0.0:69,而69是TFTP使用的端口号。如果现在转到任务管理器中查看对应的PID,我可以关闭TFTP服务器。这当然不是最优雅的方法,但是,如果你遇到的是此处打开的某种类型的端口的问题,我可以直接执行“结束”任务,而该操作将关闭我的TFTP服务器。然后,当你再次发出netstat命令时,你会发现不再监听UDP端口69。那么,这与漏洞有什么关系呢?
漏洞
因为我的计算机正在侦听所有这些不同的端口号,每个端口号都有一些与之相关的软件服务,无论是Windows进程还是你(该计算机的所有者或管理员)运行的进程都像我刚刚举例的TFTP服务器。因此,这里所有侦听流量的网络过程背后,都有与之相关的软件。这意味着攻击者会将流量发送到这些设备,例如刚刚举例的端口135。攻击者可以做的是,将修改消息包头和消息数据部分中的少量信息。黑客可以修改一些小信息,以查看计算机将做出什么样的举动和反应。这就是黑客寻找软件中漏洞的过程,他们将这些奇怪的消息发送到计算机中,并试图引起某种有趣的响应。黑客在这里发送的是非标准消息,以查看计算机收到消息后会发生什么。最终可以做的是,如果黑客发送了足够多的消息,可以将某些消息发送到这些端口号中,并且它会以某种方式进行响应,这就表明该端口中存在漏洞。在此工作站上运行这些开放端口的软件。攻击者随后可以使用从端口135扫描中获得的信息。例如,黑客可以使用该信息重新编写一些新软件来利用端口漏洞135。
这些开放端口就像我最初介绍的那个例子里我家的窗户一样。窗口在内部和外部之间建立了一个障碍,你可以使用正确的语言打开窗口,使用正确的信息可以打开该窗口。但是,攻击者(黑客)在这里试图做的是试图找到一个弱点(比如找到我的窗户上有没有已经破碎的地方),以便可以创建(找到)合适的石头来破坏窗户。因此,当我们使用它时,我们总是可以看到打开的端口号和运行它的软件。运行该软件的软件通常是我们发现该漏洞的地方,攻击者可以用来创建漏洞利用它。因此,当Windows更新定期发布时,使用它们来修补后端的所有软件是非常重要的,因为这就像猫和老鼠一样。编写没有漏洞的软件几乎是不可能的,如果你将该软件放置足够长的时间不变的情况下,攻击者总会发现该漏洞并对其进行利用。这就是为什么我说这是一场猫捉老鼠的游戏,因为每次发现漏洞时,windows都会对其进行修补,这意味着攻击者现在无法使用该漏洞进行攻击。所以始终保持软件更新以防止这些攻击非常重要。因此,请确保对系统进行修补,以防止他人利用这些漏洞利用这些攻击来攻击你的系统。
钓鱼攻击
让我们看一下如何通过人作为攻击的媒介。这里存在的一种利用网络钓鱼的方法是网络钓鱼攻击,网络钓鱼攻击是指攻击者将大量电子邮件发送给各个电子邮件地址。也许他们从暗网或者其他的源头来获得这些电子邮件地址,黑客在这里做的是构建一条消息,然后将其发送给你。他们会向你发送此消息,并且通常情况下,这些信息会使你有些沮丧,这样你就不必关注需要注意的事情了(心里学的知识哦)。比如以下这个例子,说你的密码就要过期了,然后需要你来更新。单击此链接来更新你的信息。一般这个电子邮件看起来会相对合法,你会发现这个电子邮件会和正规的学校邮箱很接近。但是会是一个看上去非常接近的邮箱。当你点击那个链接的时候,你也会看到一个非常相似的网站,然后要求你输入用户名,密码。可能会说你无法登录,请重试。但是现在攻击者已经有了你的用户名和密码。
当然这个照片是我从网上下载的,一般来说这种攻击会发生在你的购物账户,比如我的东家Amazon,或者是京东等等。我经常收到的邮件是Netflix,然后要求你输入用户名和密码还有信用卡。这就是我们常说的钓鱼攻击。
30 我要怎么藏好我的考研资料 - 网络攻击(二)
DOS 攻击
我们这里来讲一下DOS(拒绝服务)攻击。DoS攻击是很久以前开始的,可以追溯到90年代中期,即Windows 95出来之后,就出现了DOS攻击,这是利用了Windows 95设备上的一个漏洞。这个漏洞就是你可以发送一条专门的ping消息,该消息中的有效负载包含“专门的“一个消息,这将导致Windows崩溃并给出著名的死亡蓝屏。这就是一种拒绝服务攻击(DOS Attack)。当然数十年前就已对此进行了修补,但这是最早在家用设备中流行的DOS攻击之一。另一种攻击类型是分布式拒绝服务攻击(Distributed DOS Attack),也可以简称为DDOS。分布式拒绝服务攻击有多种类型。其中之一,我们要做的是向正在攻击的设备发送ping消息,但是ping消息的目标IP地址和源IP地址都是该设备,当我们这样做时,我们将其称为反射性DDoS攻击,这意味着每当我向该设备发送一个ping消息时,该设备会回复该消息并将其立即发送回源IP也就是该设备自己。因此,对于我发送的每条消息,实际上都意味着会向该设备发送两条消息。仅使用一个数据包,我就可以将多个数据包发送给该设备。最终,这可能使受攻击的设备不堪重负,这被称为反射式拒绝服务攻击或反射式DDoS攻击。
另一种攻击可以是放大攻击(Amplification Attack),这种攻击现在在Internet上越来越流行。在2016年的时候,一家名为Dyn的公司遭受了攻击,他们提供DNS服务。这种攻击的方式是利用了DNS的漏洞,其实也不能算是一个漏洞,只是利用了DNS的工作方式。我可以在DNS服务器中执行的操作是,可以向DNS服务器发送一条消息,请求发送整个DNS数据库。然后,我可以告诉DNS服务器将该数据库发送到另一个IP地址,这样做是只需要我发送一个信息,就会将其放大为数百兆或千兆字节的数据,并且将其传输到另一台设备。如果我一直重复这个操作,发送给不同的DNS服务器。或者说我使用数百或数千个机器像不同的DNS服务器发送,则会收到这种强烈的DDoS放大攻击。这台设备会受到TB级数据的轰炸,以至于无法继续工作。
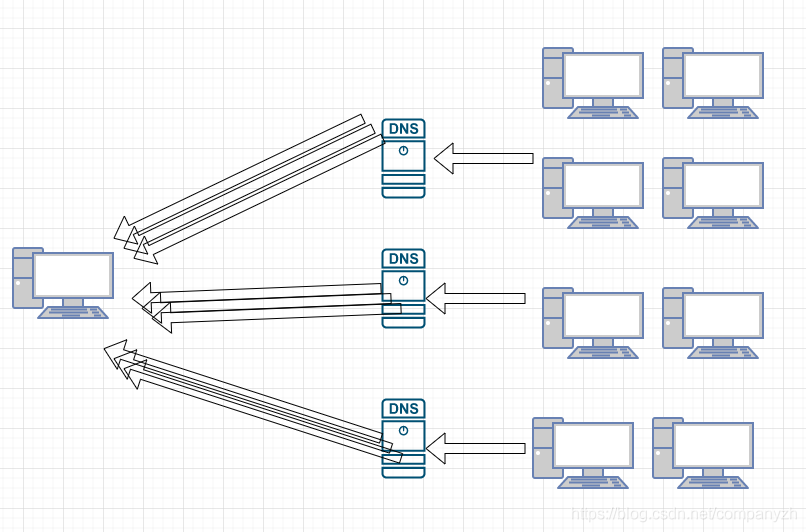
而这正是2016年Dyn DNS所发生的情况。几乎所有物联网设备,智能灯泡,智能插座,在家中可能拥有的任何智能物联网设备上都安装了恶意软件。攻击者能够激活该恶意软件并发起放大DDoS攻击,从而使Dyn DNS瘫痪。最困难的部分是,尽管有一些新技术可以帮助检测和缓解这种情况,但这实际上是这些系统运行方式的一部分,所以阻止此类攻击确实非常困难。因为如果你想办法停止接受攻击,那么你实际上就停止了使互联网正常工作的系统。所以Dyn DNS能够恢复服务的唯一原因是停止攻击。DDoS攻击最近越来越频繁地发生。我所读到的最新一项实际上创下了记录,这是一种DDoS攻击,它每秒产生超过1.7TB的数据来攻击服务器,尽管能够通过一些较新的技术来减轻这种攻击。但是,每秒1. 7TB的数据进入服务器,服务器对此无能为力,只能关闭服务。因此,DDoS攻击是真实的东西,它们是真正的威胁,而且通常它们好像就是正常的在Internet上工作一样来利用协议。这就是最可怕的。
中间人攻击(Man-in-the-middle attack)
下一个要介绍的攻击是中间人攻击。这种方法的工作方式是,我们拥有一个攻击者,就是底部的笔记本电脑,这个笔记本电脑将要做的是利用ARP表。现在,ARP表就是RPC用于确定特定IP地址的第2层MAC地址是什么。当我们从工作站(也就是最左边的电脑)进行通信时,需要使用ARP作为默认网关的MAC地址。假设这里默认网关的MAC地址为X,所以我们使用的ARP默认网关的MAC地址应该是X,但是攻击者将使用ARP答复消息来泛洪网络,该消息说默认网关不是X,而是A,这是攻击者工作站的MAC地址。这样,现在要发生的情况是,尝试访问Internet的工作站将首先将其消息发送到攻击者的工作站A,然后攻击者的工作站会将消息转发到默认网关X。传播到互联网,然后再回来。那么位于中间的那个人,即我们的攻击者,将看到在我们左侧的工作站与Internet之间发生的整个对话,然后再返回。这是中间人攻击,是为了利用ARP消息而设计的。
密码攻击
密码攻击通常有两种形式。要么进行某种网络钓鱼骗局以获取密码(我们之前讲过的),或者将执行类似暴力破解密码的操作。一般来说当出现带有用户名和密码的登录提示时,通过某种机制知道某人的电子邮件地址或他们公司的用户名(这个现在其实很简单,还有比如骚扰电话,这些信息很容易被坏人得到)。只是不知道相对应的密码。这里可以使用的是所谓的Rainbow(彩虹)表(这些表是可免费下载的,给你个链接,感兴趣的可以看一下 https://project-rainbowcrack.com/table.htm ),其中仅包含潜在密码的列表。暴力密码攻击所能做的就是,发送密码不断的尝试,每秒进行3、4、5、10、100个密码尝试登录。当你尝试输入错误密码三遍后,某些系统会锁住。这是防止暴力密码攻击的非常有效的机制。有的系统则没有内置该功能(好像现在基本都会了)。有人可以一直尝试输入密码,直到输入正确的密码(记得早年的小电影网站就是这么破解的)。通常,这些密码在某种类型的数据库中,甚至你可以下载获得的已知和使用过的密码表,并将其放入数据库中。再多唠叨两句-很多时候,密码具有相通性,你想一下,你的邮箱,信用卡等等网站,可能用的是同一个密码,或者说差别不大的密码对不对,还有就是早年的密码要求没有那么繁琐,很多人用的就是123456,我记得我上高中的时候,使用123456就破解过不下10个QQ号(暴露我的年龄啦)。所以自己对自己的东西多上点心。
Virus/Malware 病毒和恶意软件
其他一些网络攻击类型还有病毒和恶意软件攻击。这是真的很常见的攻击。电脑很容易感染病毒,也很容易获得恶意软件。有很多的IT专业人员在全部的职业生涯中的工作从计算机中清除病毒和恶意软件。比如早年的熊猫烧香,那真是名震一时呀(我为啥老暴露年龄)。
Logic Bomb 逻辑炸弹
我们可以获得的恶意软件类型之一是逻辑炸弹。逻辑炸弹是一种可以安装到计算机上的病毒,它可能在特定时间段内或直到有人向其发出信号才会激活,开始破坏,停止破坏。现在,这些通常是僵尸网络的一部分,僵尸网络是一个非常大的网络连接,所有连接都安装了恶意软件。我们将病毒安装在我们的工作站也就是计算机上,通常是偶然的。里面有某种类型的逻辑炸弹-病毒会在收到信号或一定时间后被激活,这就是如何进行攻击的方法,就像我之前举的那个Dyn DNS被攻击的例子。这些DNS服务器接收到如此多的流量,它对此无能为力。其来源是装有恶意软件的物联网小型设备,并且向所有这些物联网设备发送了一条消息,以打开该逻辑炸弹,然后一起鞭炮齐鸣-开始攻击Dyn DNS并搞垮了他们的系统。
Ransomware 勒索软件
另一种是勒索软件。可能是你主机感染了病毒,该病毒通常以病毒形式出现在你意外点击的电子邮件附件中,或者你访问的网站上安装了一些恶意软件(例如某些你懂得网站,不要总看)。通常,勒索软件会加密你整个硬盘驱动器或加密整个存储区域,如果你要取回数据,你必须支付一定的勒索费用。现在都是要求比特币(查不到收件人的信息,知道为什么火了吧)的价格向某人支付才能获得用于解锁加密文件的密码,除非你拥有密码,否则没有其他方法可以访问加密数据。因此,勒索软件是通过加密你的数据来勒索你窃取金钱的一种方法。
DNS中毒
DNS中毒是另一种方式。简单来说,就是比如csdn吧,当你询问地址的时候,假如csdn的IP是1.2.3.4。这个是正确的,但是因为DNS中毒,所以会被强制DNS更新其记录到5.6.7.8也就是一个恶意站点。所以,你可以使DNS中毒将流量发送到不是合法服务器的另一台服务器。好的,这就是DNS中毒。还有一个就是这里的另一个是VLAN跳变。 VLAN跳变是可能接近20年前的一种方式,你可以在其中将专用消息发送到访问端口,并通过中继链路将其跳转到另一个VLAN。对于现代来说,这是一种陈旧的,已经基本无效的攻击,现在基本无法实现,但当时却是网络中的一个漏洞。
31 如何保护我的考研资料 - 网络攻击防范
Internet Edge
现在,Internet边缘已成为我们内部专用设备和Internet之间的网络中的一个位置。我们的内部专用设备通常假定内部网络中传递的数据是安全的。如果我们的其中一台设备上装有病毒或恶意软件,那可能会改变。但是在大多数情况下,我们假设内部网络中的流量与Internet上的流量相比是安全的。数据包仅需满足在互联网上传递的最低要求,这使得攻击者可以将有效载荷放置在几乎任何他们想要的数据包上,这使攻击者经常可以利用我们内部设备中的漏洞。因此,我们要防止发生的事情就是像在防火墙中那样做。防火墙是我们防御来自互联网的攻击的第一道防线。通常,防火墙所做的大部分是创建单向流量,这意味着流量可以从网络内部的设备流向Internet,然后又流回Internet,但是流量不能从Internet通过防火墙流向我们的内部设备。此外,我们的防火墙可以具有访问控制列表,并且我们可以设置VLAN来创建DMZ(是一种外围网络,可保护组织的内部局域网LAN免受不受信任的流量)。因此,也许我们创建了一个访问控制列表,说允许Internet用户访问连接到防火墙的绿色服务器,该服务器位于防火墙的DMZ中,从而允许Internet和内部网络上的用户访问该服务器。
我们还可以安装入侵检测设备或IDS入侵检测系统。通常,这些入侵检测系统是防火墙的一部分。入侵检测设备要做的就是监视通过它的所有比特流,
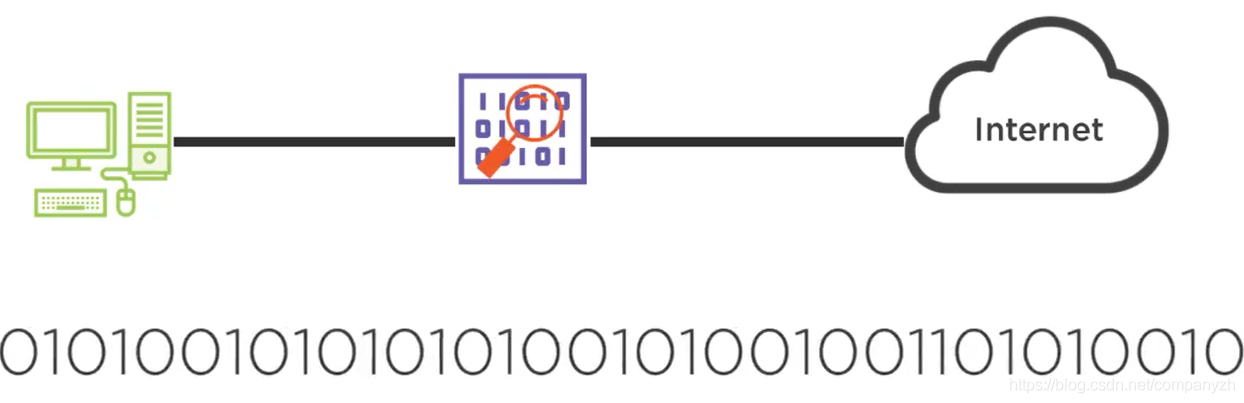
并将其与一组称为签名的已知恶意流量进行比较。这些签名存储在数据库中。当签名与流经IDS的流量匹配相同的模式时,你将获得一个匹配,然后IDS发出警报并说嘿,这里有危险哦。
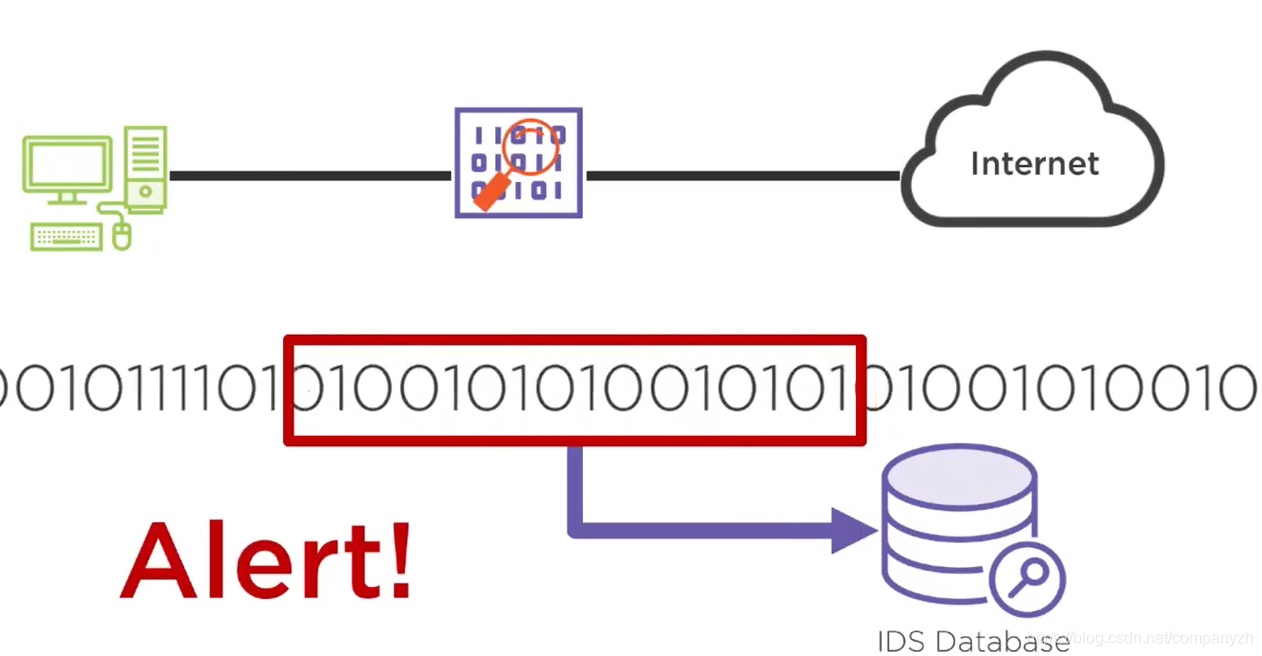
你需要检测正在发出恶意流量的设备。此IDS中存在数据库上的那些签名不断变化,并且不断添加新的签名。因此,你需要一种方法来管理该数据库上的那些签名。通常,这种工作方式是,当你购买入侵检测系统时,会附带一个订阅服务,你必须为此支付额外的费用。你可以允许自动更新数据库的签名,以便你在网络中始终拥有最新的已知恶意流量签名集。
URL过滤器是可以帮助我们防止网络攻击的另一个功能。内部要浏览的每一个网页都要检查,并确保你没有访问那些已知为不良网站的网站。这种网站也是很多而且不断的在更新,你可以购买订阅服务的数据库,它们会向你发送定期更新的已知不良网站,这些不良网站上装有恶意软件或病毒。然后,我们可以使用该URL过滤器来确保我们的内部用户不会意外访问包含恶意流量的网站。
设备加固
设备加固,我们可以通过更改密码,设置和使用安全协议来加固设备。我们可能还想关闭IP端口号之类的东西。我们可能用于VPN之类的IP端口号在IP数据包中有一个特殊的端口号,我们可以将其关闭。此外,在我们的设备,路由器和交换机中,我们还可以关闭那些我们不使用的端口,因为如果我们有一台交换机关闭了所有当前未使用的端口,那么当有人尝试插入其中一个端口并连接设备时,至少这个访问是不被允许的。其他大部分的方法都是针对路由器和交换机的,在这里就不多做介绍了。
用户和数据
接下来我们讨论用户和数据。用户通常是对我们网络的主要威胁。我们可以拥有不称职,会犯错误并可能导致问题的用户,我们也可能拥有知识渊博的用户,或者拥有的满满恶意的用户(记住一句话,Customer is evil)。因此,我们可以采取一些措施来防止这种情况的发生,其中之一就是角色分离。如果你是你名客服,则只会授予你操作客服软件的权限。并且你将无法访问DHCP服务器,Active Directory服务器或发钱软件。如果你要进行会计工作,那么你将被授权特别的权限来访问会计软件,并且可能无法访问客服软件。因此,这种角色分离对于确保我们的网络安全至关重要。
相信你听过很多国外的电商被攻击的故事。用户名和密码也很容易受到攻击。由于HVAC系统具有易于受到攻击的管理访问权限和用户特权,并且攻击者进入并从商店中窃取了数百万个用户数据(包括信用卡信息),这仅仅是因为他们在实施HVAC软件时没有适当的角色分离。但是在角色分离中,我们确实需要管理员和特权用户。会计中将有一些用户需要对会计软件的特权访问,以便他们可以对软件进行修改,而普通会计可能不需要。此外,我们还需要整个数据网络的管理员和特权用户,他们可以进入并能够更改路由器和交换机上的内容。因此,这些都是重要的角色,但是我们必须确保分配的角色适合特定员工的任务。因此,用户将拥有与管理员和其他特权不同的特权。
接下来,我们可以讨论文件完整性监视,而文件完整性监视可以做什么,我们通过一个小算法运行它,返回一个值,然后我们可以稍后比较该值以查看文件是否被修改。我们可以使用某些软件做同样的事情,通过定期检查以确保可以从文件中计算出这些哈希值,来验证网络中的数据,服务器中以及存储区域网络中的数据是否保持一致。
渗透测试
我们可以进行的渗透测试聘请经验丰富的工程师,而该经验丰富的工程师将使用一系列实用工具对你的数据网络进行实际攻击。攻击虽然是已知的攻击,但是你将知道何时发生,并且进行攻击的熟练工程师也知道,他们无权获取任何数据,除非这是测试的一部分。
渗透测试背后的想法是查看网络中需要修补的漏洞,以使攻击者无法访问系统。渗透测试的另一个扩展是整个安全的审核。如果渗透测试通常是试图从Internet攻击网络的Internet外部用户,则安全审核将变得更加全面。从外部看,外部攻击者可以从你的网络中获得什么访问权限,还可以看到网络内部可能存在哪些漏洞可以被攻击者利用。全面的安全审核通常在组织中很少见,因为它们最终可能会导致成本高昂并且需要更多人员来实施这些技术。但是,随着网络攻击变得越来越普遍和主流,我们看到安全审核实际上正变得越来越普遍,因为组织不想冒丢失数据或网络正常运行时间的风险,因为存在潜在的网络攻击风险。Netflix实际上有一个组叫做chaos Engineering。这个组就是专门进行各种破坏来测试软件的健壮性。
32 Linux网络安全 - 安全实战
我们来学习如何利用一些特别智能的工具,这些工具可以为你提供有关网络运行状况的稳定,快速,直观的更新,提供深入的历史数据表示,当发现可疑的行为时会及时警告,并持续进行涉及你所关心的网络节点的漏洞评估。如果你要启动一些面向互联网的应用程序,那么你确实应该考虑将某些甚至全部这些功能集成到你的基础架构中。
ntop
像Unix中的top指令一样,能够实时显示系统中各个进程的资源占用状况,ntop使你可以密切注意网络上的情况。当以混杂模式(默认设置)运行时,ntop将监视和报告所有流量,无论它是否针对你的特定主机。在此Ubuntu上安装ntop很容易。但是,由于系统将提示你输入要监视的网络接口,因此应首先要确认指定的名称(使用ifconfig)。使用以下指令安装
1 | sudo apt install ntop |
就像我们提到的那样,安装过程需要输入你要监视的网络接口。
安装完成后,ntop应该已启动并正在运行。你可以通过systemctl和ps来确认这一点。
1 | sudo systemctl status ntop |
如果你不希望ntop在系统启动时自动启动,则可以在etc/default/ntop中将ENABLED的行的值编辑为0而不是1。
默认情况下,ntop包含一个内置的Web服务器,可通过端口3000访问该服务器。你可以从任何与服务器连接的浏览器中打开该站点。考虑到ntop的轻巧,你最好使用某种低占用空间的VM来运行它。然后,假设你已启用某种桥接或端口转发,则应该能够从网络内的任何计算机登录。还没有网桥,或者不确定如何启用端口转发,可以使用以下的指令。这是你可以使用的快速简单的IP表规则。
1 | iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 3000 - j DNAT --to 10.0.3.230:3000 |
这样做是通过主机的eth0接口接收任何流量,该接口指定端口3000。并将其重定向到本地VM的IP地址中的端口3000。无论如何,完成此操作后,我可以移至浏览器并输入主机服务器的IP地址。
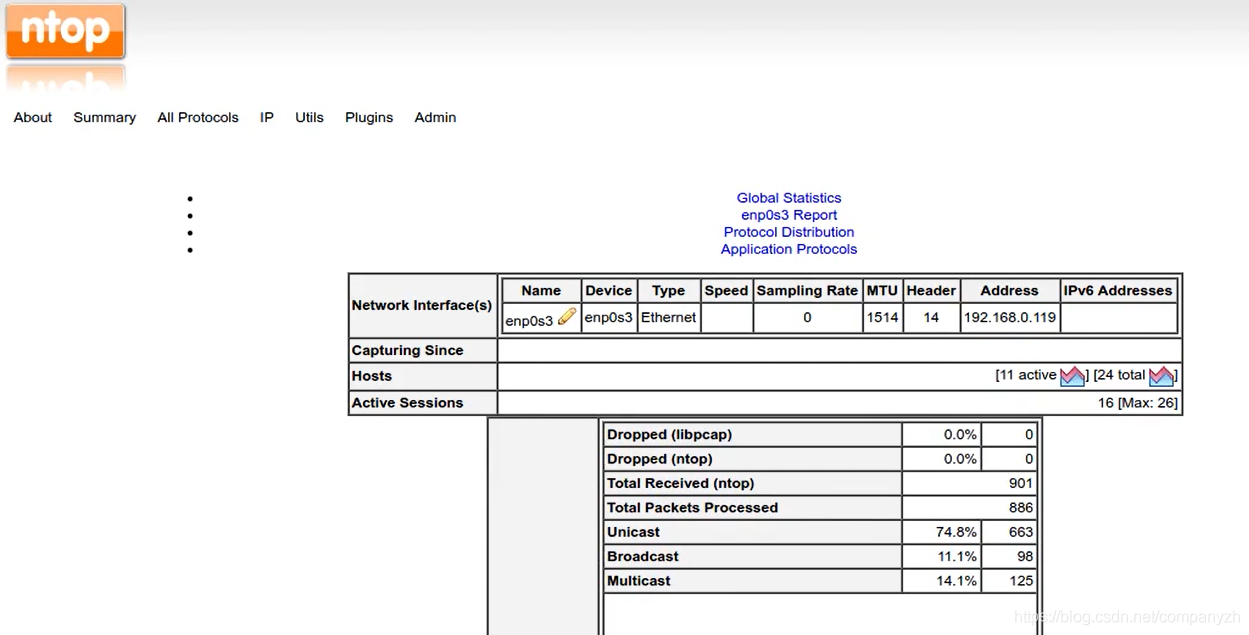
我们应该做的第一件事是单击“管理员”,“配置”和“启动首选项”来使用用户名以及安装过程中创建的密码登录
摘要菜单提供了受监控流量的概述。
按接口和协议等不同指标进行排列。主机将显示连接的主机及其网络配置文件。

网络负载为你显示了图形化的统计信息,说明了历史时间段内经历的负载水平。此功能对于快速发现突然的和无法解释的活动峰值特别有用。所有协议和流量都以数字形式表示主机的网络流量,网络吞吐量为我们提供负载率。
你可以激活或停用sflow插件,从而使ntop可以管理sflow格式的数据,该数据可以由Wireshark等其他软件使用。
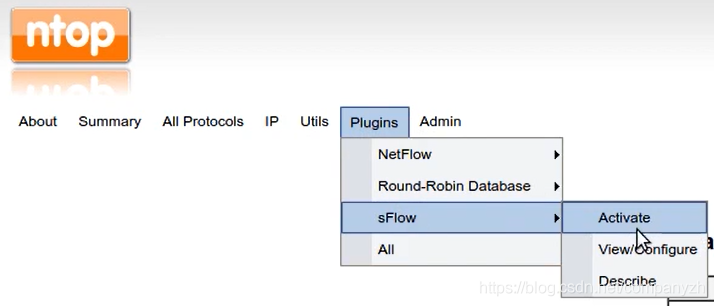
其他页面允许你类似地深入数据,以更好地理解和可视化网络上实际发生的事情。你应该花一些时间来了解所有选项。我就不一一的介绍了。只有当你实际花费时间定期查看输出时,ntop统计信息才有用。一种可行的方法是养成使ntop在浏览器的选项卡中运行,然后单击以偶尔查看一下的习惯。你应该一眼就能发现奇怪的信息。另一种方法是在办公室某处繁忙的地方的墙上悬挂一个屏幕,这样来来回回的人就都能看到。
cacti - Network Graphing
ntop非常擅长处理实时数据,但是,如果你正在寻找网络历史状态的深入,图形化的详细视图,那么cacti可能是值得一看究竟的东西。与ntop一样,cacti被构建为RRDtool日志记录服务。

实际上,你甚至可以通过可用的插件将ntop数据添加到cacti的显示器中。由于cacti提供了特别丰富的功能,包括各种自定义选项,因此完全配置它以满足你的特定需求可能很复杂。选择cacti意味着你的未来将有一个学习曲线(Learning Curve)。我将帮助你克服这种困难的想法,并建立一个简单的基于存储库的实例。
首先,还是需要先安装。
1 | sudo apt intall cacti |
在安装过程中,系统将提示我输入MySQL密码,并选择一个Web服务器。我将使用Apache。

还会询问我是否要使用通用数据库来为Cacti配置数据库。我选择的是Yes。
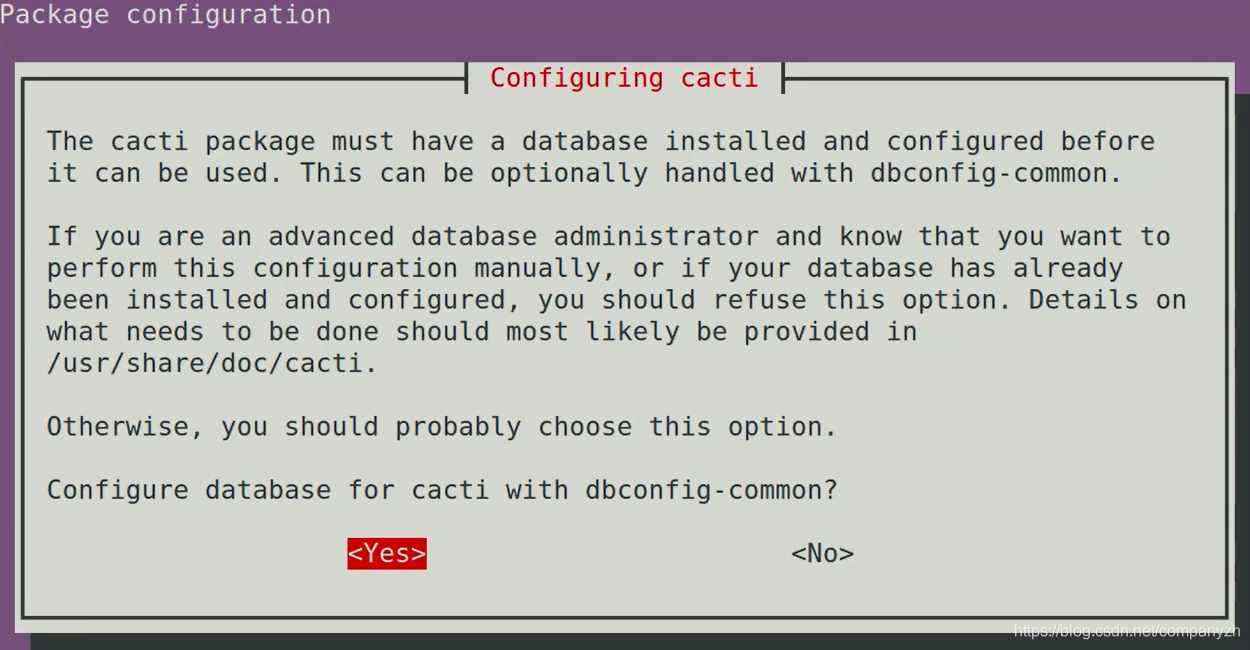
基本配置详细信息(例如密码和数据库信息)可以在etc/cacti/debian.php中找到。 如果你需要进行任何更改,或者只是想提醒自己原来的选择,这里可以是你要找的地方。但是,所有真正的cacti乐趣都发生在你的浏览器中。首先,将浏览器指向Cacti服务器的主机名或IP地址,然后添加/ cacti。首次访问此地址时,单击``新建安装’’,将显示Cacti认为你需要的默认配置值,并确认所有必需资源都可访问。
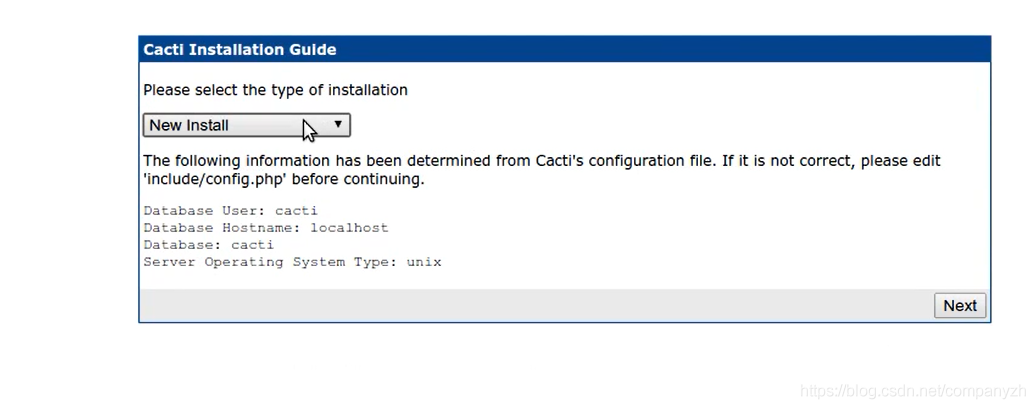
准备好实际开始工作后,将提示你输入Cacti用户名和密码。
当然,你尚未选择用户名和密码。但是我可以告诉默默的告诉你,默认的用户名和密码均为admin(一般人我告诉他/她)。第一次登录后,你会被强制要求更新密码。登录后,你会发现cacti界面主要分为两个选项卡。控制台是你管理设备和配置的地方,图形是你查看Cacti网络分析的图形化输出的位置。
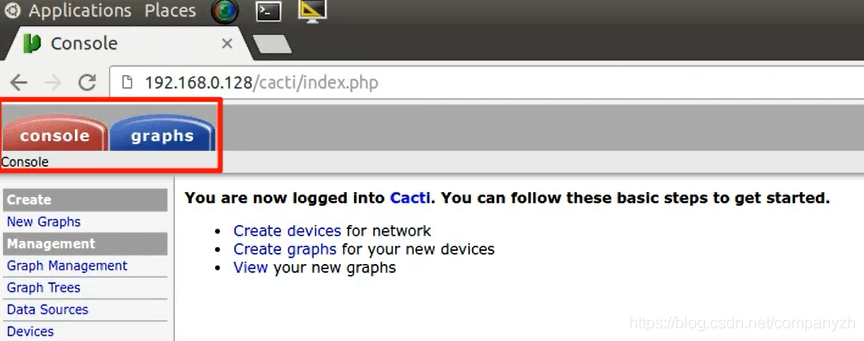
我们可以单击左侧面板上的“设备”,即可查看在安装过程中创建的本地主机设备。除了管理基本的设备状态和ID详细信息以及连接设置(如Downed Device Detection协议选择)外,我将单击Localhost链接以了解我们可以在这里可以控制的各种事情。
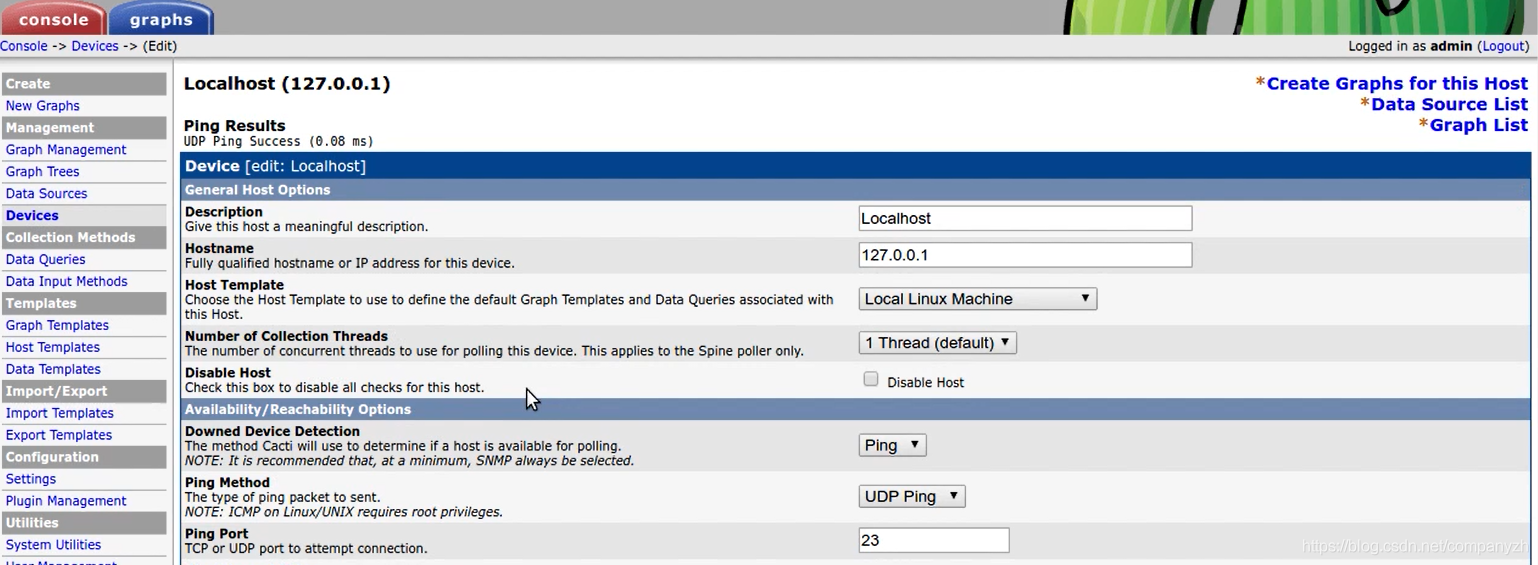
你还可以在左边的控制栏上点击和查看控制数据源,图形和查看系统日志。回到图形窗口,我们可以按任何历史时间段过滤图形内容,从而使可视化网络所经历的现实活动变得更加简单。并且通过添加插件(例如ntop插件),还可以大大增加可跟踪的数据范围。
感兴趣的你可以自己安装来玩耍一下。
Snort 入侵防护
与基于明确规则允许或拒绝流量的防火墙不同,基于网络的入侵检测系统(如Snort)将评估数据包并在出现可疑的时候向管理员发出警报,Snort实际上可以在三种模式下运行。
- 嗅探器,它只读取看到的所有数据包,然后将它们打印在屏幕上。
- 设置为“日志”时,它将把数据包转移到预设的日志目录。在完全网络入侵检测模式下,它会根据规则集分析流量内容,然后在发现匹配项时提醒管理员。
- 在IDS模式下,Snort可以很好地发现恶意缓冲区溢出或隐匿端口扫描的早期症状。为了确保您保持最新状态,
要想获取Snort的最新版本,你需要自己去构建。这需要大量的文件系统管理经验。尽管Snort站点具有出色的文档。当然因为我们只是讲解,并不会用在production上,我将使用简便的方式安装
1 | sudo apt install snort |
同样的,你需要在安装之前确认接口信息,因为系统会提示你选择Snort将在其所使用的子网范围内使用的主接口。
此配置信息将保存在etc/snort/snort.conf。你应该在snort中寻找ipvar HOME_NET。HOME_NET值必须至少包含Snort将监听的子网。
使用any可以,但是你最好将活动限制为仅一个特定网络。

上图中的rule也很重要,因为你可以使用包含,添加你自己的规则,测试Snort警报的规则。完成后,我们应该测试配置文件,以确保没有错误。您可以验证Snort。使用-T进行测试,使用-i选择接口测试,然后使用-c 告诉Snort配置是哪个,这是我们目前正在测试的配置。
1 | snort -T -i enp0s3 -c /etc/snort/snort.conf |
希望你会在输出的末尾看到成功消息,如下所示。

现在让我们来启动它。我们将告诉Snort使用-A console参数将其输出打印到屏幕上。 -q表示安静运行,而没有常规状态报告。 u指定一个用户,在这种情况下为Snort。 g指定它的组,再次是Snort。 c指向我们的conf配置文件。-i告诉Snort使用哪个网络接口。
1 | snort -A console -q -u snort -g snort -c /etc/snort/snort.conf -i enp0s3 |
你可以打开另一个terminal来进行ping操作,你会发现有很多的流量在流动。我们在屏幕上看到的所有内容也都保存到/ var/log/snort目录中的单个文件中。当然,所有这些都会产生大量的数据,而这些数据将很快变得几乎无法读取。解决该问题的一种方法是安装Barnyard2将进入的数据假脱机到MySQL数据库中,然后可以使用最合适的方式查看和解释该数据库。这超出了本课程的范围,我就不细讲了。
33 结语
大家好,我是Chris。我其实很早就有想要讲这个专题的准备,但是一直在“Come on”,“放弃吧,时间不够”来回的挣扎。你们知道,我是有一份全职的工作,而且还兼职在一家培训机构做讲师。再加上写文章和专栏。所以这个难度也是可想而知的。
这个专栏也是从筹备到上线到完结大概100天吧。很多事情就是这样,做的时候觉得很难,现在回头看,感觉一切的挣扎都是值得的。当然如果可以得到你的一个肯定,我肯定会更加的开心。
我原本的计划可能只有20篇,后来再和编辑不断的交流以及我偶尔爆发的洪荒之力下,硬是写出了32篇。这哪里能看出我是当年语文最差的学生。其实网络真的是一个很大的领域,毫不夸张的说,它绝不比我们所认知的编程要少,即使我写320篇,那也只是凤毛麟角。但是我们要认准自己的学习目的以及我们的初衷是什么。
说实话,写这个专栏,可能收获最多的反而是我自己,首先给了我自己一个总结的机会,让我重新的复习了那些我曾经了然于胸但是很久不用的东西了。当然,我也希望你的收获可以和我一样大,读完之后,可以拍着胸脯说,我已经对网络入门了,面试的时候,面试官已经面不倒你网络知识的内容了,那我就很欣慰了。
当然作为我的第一个专栏,我相信肯定会有这样,那样的问题,希望各位可以包容,当然更希望你可以给我指正出来,再我接下来的专栏中,我可以吸取教训来改正。当然如果你喜欢我的风格,我也是愿意听到的。
希望你也可以和我一样,可以经常的突破自我,咬紧牙关去客服你生活和技术上的困难,我还是那个到了油腻之年,却依然相信自己是帅气的程序员的Chris。