20 容器安全(2):在容器中,我不以root用户来运行程序可以吗?
你好,我是程远。
在上一讲里,我们学习了 Linux capabilities 的概念,也知道了对于非 privileged 的容器,容器中 root 用户的 capabilities 是有限制的,因此容器中的 root 用户无法像宿主机上的 root 用户一样,拿到完全掌控系统的特权。
那么是不是让非 privileged 的容器以 root 用户来运行程序,这样就能保证安全了呢?这一讲,我们就来聊一聊容器中的 root 用户与安全相关的问题。
问题再现
说到容器中的用户(user),你可能会想到,在 Linux Namespace 中有一项隔离技术,也就是 User Namespace。
不过在容器云平台 Kubernetes 上目前还不支持 User Namespace,所以我们先来看看在没有 User Namespace 的情况下,容器中用 root 用户运行,会发生什么情况。
首先,我们可以用下面的命令启动一个容器,在这里,我们把宿主机上 /etc 目录以 volume 的形式挂载到了容器中的 /mnt 目录下面。
1 | # docker run -d --name root_example -v /etc:/mnt centos sleep 3600 |
然后,我们可以看一下容器中的进程”sleep 3600”,它在容器中和宿主机上的用户都是 root,也就是说,容器中用户的 uid/gid 和宿主机上的完全一样。
1 | # docker exec -it root_example bash -c "ps -ef | grep sleep" |
虽然容器里 root 用户的 capabilities 被限制了一些,但是在容器中,对于被挂载上来的 /etc 目录下的文件,比如说 shadow 文件,以这个 root 用户的权限还是可以做修改的。
1 | # docker exec -it root_example bash |
接着我们看看后面这段命令输出,可以确认在宿主机上文件被修改了。
1 | # tail -n 3 /etc/shadow |
这个例子说明容器中的 root 用户也有权限修改宿主机上的关键文件。
当然在云平台上,比如说在 Kubernetes 里,我们是可以限制容器去挂载宿主机的目录的。
不过,由于容器和宿主机是共享 Linux 内核的,一旦软件有漏洞,那么容器中以 root 用户运行的进程就有机会去修改宿主机上的文件了。比如 2019 年发现的一个 RunC 的漏洞 CVE-2019-5736, 这导致容器中 root 用户有机会修改宿主机上的 RunC 程序,并且容器中的 root 用户还会得到宿主机上的运行权限。
问题分析
对于前面的问题,接下来我们就来讨论一下解决办法,在讨论问题的过程中,也会涉及一些新的概念,主要有三个。
方法一:Run as non-root user(给容器指定一个普通用户)
我们如果不想让容器以 root 用户运行,最直接的办法就是给容器指定一个普通用户 uid。这个方法很简单,比如可以在 docker 启动容器的时候加上”-u”参数,在参数中指定 uid/gid。
具体的操作代码如下:
1 | # docker run -ti --name root_example -u 6667:6667 -v /etc:/mnt centos bash |
还有另外一个办法,就是我们在创建容器镜像的时候,用 Dockerfile 为容器镜像里建立一个用户。
为了方便你理解,我还是举例说明。就像下面例子中的 nonroot,它是一个用户名,我们用 USER 关键字来指定这个 nonroot 用户,这样操作以后,容器里缺省的进程都会以这个用户启动。
这样在运行 Docker 命令的时候就不用加”-u”参数来指定用户了。
1 | # cat Dockerfile |
好,在容器中使用普通用户运行之后,我们再看看,现在能否修改被挂载上来的 /etc 目录下的文件? 显然,现在不可以修改了。
1 | [[email protected] /]$ echo "hello" >> /mnt/shadow |
那么是不是只要给容器中指定了一个普通用户,这个问题就圆满解决了呢?其实在云平台上,这么做还是会带来别的问题,我们一起来看看。
由于用户 uid 是整个节点中共享的,那么在容器中定义的 uid,也就是宿主机上的 uid,这样就很容易引起 uid 的冲突。
比如说,多个客户在建立自己的容器镜像的时候都选择了同一个 uid 6667。那么当多个客户的容器在同一个节点上运行的时候,其实就都使用了宿主机上 uid 6667。
我们都知道,在一台 Linux 系统上,每个用户下的资源是有限制的,比如打开文件数目(open files)、最大进程数目(max user processes)等等。一旦有很多个容器共享一个 uid,这些容器就很可能很快消耗掉这个 uid 下的资源,这样很容易导致这些容器都不能再正常工作。
要解决这个问题,必须要有一个云平台级别的 uid 管理和分配,但选择这个方法也要付出代价。因为这样做是可以解决问题,但是用户在定义自己容器中的 uid 的时候,他们就需要有额外的操作,而且平台也需要新开发对 uid 平台级别的管理模块,完成这些事情需要的工作量也不少。
方法二:User Namespace(用户隔离技术的支持)
那么在没有使用 User Namespace 的情况,对于容器平台上的用户管理还是存在问题。你可能会想到,我们是不是应该去尝试一下 User Namespace?
好的,我们就一起来看看使用 User Namespace 对解决用户管理问题有没有帮助。首先,我们简单了解一下User Namespace的概念。
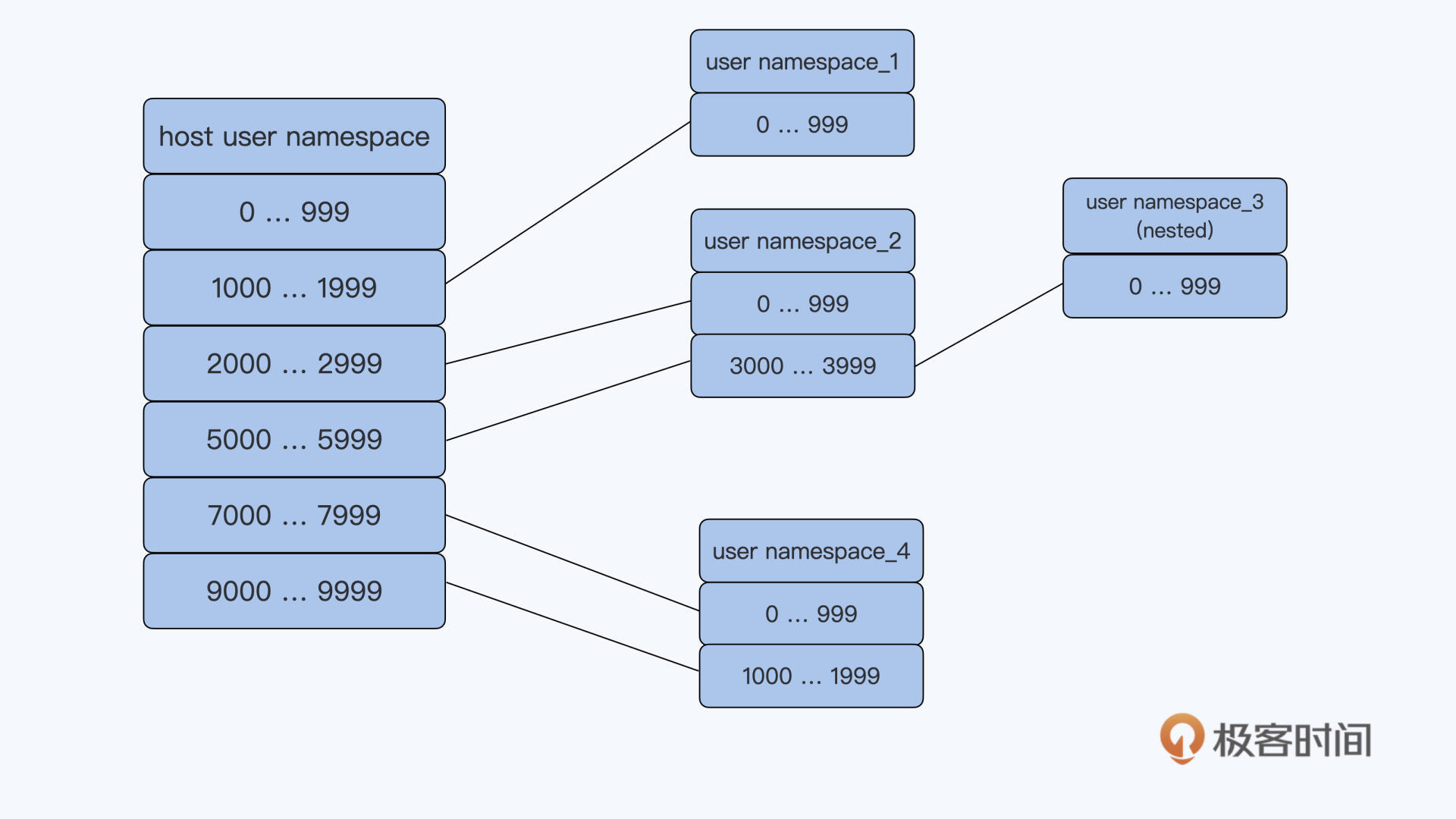
User Namespace 隔离了一台 Linux 节点上的 User ID(uid)和 Group ID(gid),它给 Namespace 中的 uid/gid 的值与宿主机上的 uid/gid 值建立了一个映射关系。经过 User Namespace 的隔离,我们在 Namespace 中看到的进程的 uid/gid,就和宿主机 Namespace 中看到的 uid 和 gid 不一样了。
你可以看下面的这张示意图,应该就能很快知道 User Namespace 大概是什么意思了。比如 namespace_1 里的 uid 值是 0 到 999,但其实它在宿主机上对应的 uid 值是 1000 到 1999。
还有一点你要注意的是,User Namespace 是可以嵌套的,比如下面图里的 namespace_2 里可以再建立一个 namespace_3,这个嵌套的特性是其他 Namespace 没有的。
我们可以启动一个带 User Namespace 的容器来感受一下。这次启动容器,我们用一下podman这个工具,而不是 Docker。
跟 Docker 相比,podman 不再有守护进程 dockerd,而是直接通过 fork/execve 的方式来启动一个新的容器。这种方式启动容器更加简单,也更容易维护。
Podman 的命令参数兼容了绝大部分的 docker 命令行参数,用过 Docker 的同学也很容易上手 podman。你感兴趣的话,可以跟着这个手册在你自己的 Linux 系统上装一下 podman。
那接下来,我们就用下面的命令来启动一个容器:
1 | # podman run -ti -v /etc:/mnt --uidmap 0:2000:1000 centos bash |
我们可以看到,其他参数和前面的 Docker 命令是一样的。
这里我们在命令里增加一个参数,”–uidmap 0:2000:1000”,这个是标准的 User Namespace 中 uid 的映射格式:”ns_uid:host_uid:amount”。
那这个例子里的”0:2000:1000”是什么意思呢?我给你解释一下。
第一个 0 是指在新的 Namespace 里 uid 从 0 开始,中间的那个 2000 指的是 Host Namespace 里被映射的 uid 从 2000 开始,最后一个 1000 是指总共需要连续映射 1000 个 uid。
所以,我们可以得出,这个容器里的 uid 0 是被映射到宿主机上的 uid 2000 的。这一点我们可以验证一下。
首先,我们先在容器中以用户 uid 0 运行一下 sleep 这个命令:
1 | # id |
然后就是第二步,到宿主机上查看一下这个进程的 uid。这里我们可以看到,进程 uid 的确是 2000 了。
1 | # ps -ef |grep sleep |
第三步,我们可以再回到容器中,仍然以容器中的 root 对被挂载上来的 /etc 目录下的文件做操作,这时可以看到操作是不被允许的。
1 | # echo "hello" >> /mnt/shadow |
好了,通过这些操作以及和前面 User Namespace 的概念的解释,我们可以总结出容器使用 User Namespace 有两个好处。
第一,它把容器中 root 用户(uid 0)映射成宿主机上的普通用户。
作为容器中的 root,它还是可以有一些 Linux capabilities,那么在容器中还是可以执行一些特权的操作。而在宿主机上 uid 是普通用户,那么即使这个用户逃逸出容器 Namespace,它的执行权限还是有限的。
第二,对于用户在容器中自己定义普通用户 uid 的情况,我们只要为每个容器在节点上分配一个 uid 范围,就不会出现在宿主机上 uid 冲突的问题了。
因为在这个时候,我们只要在节点上分配容器的 uid 范围就可以了,所以从实现上说,相比在整个平台层面给容器分配 uid,使用 User Namespace 这个办法要方便得多。
这里我额外补充一下,前面我们说了 Kubernetes 目前还不支持 User Namespace,如果你想了解相关工作的进展,可以看一下社区的这个PR。
方法三:rootless container(以非 root 用户启动和管理容器)
前面我们已经讨论了,在容器中以非 root 用户运行进程可以降低容器的安全风险。除了在容器中使用非 root 用户,社区还有一个 rootless container 的概念。
这里 rootless container 中的”rootless”不仅仅指容器中以非 root 用户来运行进程,还指以非 root 用户来创建容器,管理容器。也就是说,启动容器的时候,Docker 或者 podman 是以非 root 用户来执行的。
这样一来,就能进一步提升容器中的安全性,我们不用再担心因为 containerd 或者 RunC 里的代码漏洞,导致容器获得宿主机上的权限。
我们可以参考 redhat blog 里的这篇文档, 在宿主机上用 redhat 这个用户通过 podman 来启动一个容器。在这个容器中也使用了 User Namespace,并且把容器中的 uid 0 映射为宿主机上的 redhat 用户了。
1 | $ id |
目前 Docker 和 podman 都支持了 rootless container,Kubernetes 对rootless container 支持的工作也在进行中。
重点小结
我们今天讨论的内容是 root 用户与容器安全的问题。
尽管容器中 root 用户的 Linux capabilities 已经减少了很多,但是在没有 User Namespace 的情况下,容器中 root 用户和宿主机上的 root 用户的 uid 是完全相同的,一旦有软件的漏洞,容器中的 root 用户就可以操控整个宿主机。
为了减少安全风险,业界都是建议在容器中以非 root 用户来运行进程。不过在没有 User Namespace 的情况下,在容器中使用非 root 用户,对于容器云平台来说,对 uid 的管理会比较麻烦。
所以,我们还是要分析一下 User Namespace,它带来的好处有两个。一个是把容器中 root 用户(uid 0)映射成宿主机上的普通用户,另外一个好处是在云平台里对于容器 uid 的分配要容易些。
除了在容器中以非 root 用户来运行进程外,Docker 和 podman 都支持了 rootless container,也就是说它们都可以以非 root 用户来启动和管理容器,这样就进一步降低了容器的安全风险。
思考题
我在这一讲里提到了 rootless container,不过对于 rootless container 的支持,还存在着不少的难点,比如容器网络的配置、Cgroup 的配置,你可以去查阅一些资料,看看 podman 是怎么解决这些问题的。
欢迎你在留言区提出你的思考和疑问。如果这一讲对你有帮助,也欢迎转发给你的同事、朋友,一起交流学习。
加餐06 BCC:入门eBPF的前端工具
你好,我是程远。
今天是我们专题加餐的最后一讲,明天就是春节了,我想给还在学习的你点个赞。这里我先给你拜个早年,祝愿你牛年工作顺利,健康如意!
上一讲,我们学习了 eBPF 的基本概念,以及 eBPF 编程的一个基本模型。在理解了这些概念之后,从理论上来说,你就能自己写出 eBPF 的程序,对 Linux 系统上的一些问题做跟踪和调试了。
不过,从上一讲的例子里估计你也发现了,eBPF 的程序从编译到运行还是有些复杂。
为了方便我们用 eBPF 的程序跟踪和调试系统,社区有很多 eBPF 的前端工具。在这些前端工具中,BCC 提供了最完整的工具集,以及用于 eBPF 工具开发的 Python/Lua/C++ 的接口。那么今天我们就一起来看看,怎么使用 BCC 这个 eBPF 的前端工具。
如何使用 BCC 工具
BCC(BPF Compiler Collection)这个社区项目开始于 2015 年,差不多在内核中支持了 eBPF 的特性之后,BCC 这个项目就开始了。
BCC 的目标就是提供一个工具链,用于编写、编译还有内核加载 eBPF 程序,同时 BCC 也提供了大量的 eBPF 的工具程序,这些程序能够帮我们做 Linux 的性能分析和跟踪调试。
这里我们可以先尝试用几个 BCC 的工具,通过实际操作来了解一下 BCC。
大部分 Linux 发行版本都有 BCC 的软件包,你可以直接安装。比如我们可以在 Ubuntu 20.04 上试试,用下面的命令安装 BCC:
1 | # apt install bpfcc-tools |
ls -l /sbin/*-bpfcc | more
-rwxr-xr-x 1 root root 34536 Feb 7 2020 /sbin/argdist-bpfcc -rwxr-xr-x 1 root root 2397 Feb 7 2020 /sbin/bashreadline-bpfcc -rwxr-xr-x 1 root root 6231 Feb 7 2020 /sbin/biolatency-bpfcc -rwxr-xr-x 1 root root 5524 Feb 7 2020 /sbin/biosnoop-bpfcc -rwxr-xr-x 1 root root 6439 Feb 7 2020 /sbin/biotop-bpfcc -rwxr-xr-x 1 root root 1152 Feb 7 2020 /sbin/bitesize-bpfcc -rwxr-xr-x 1 root root 2453 Feb 7 2020 /sbin/bpflist-bpfcc -rwxr-xr-x 1 root root 6339 Feb 7 2020 /sbin/btrfsdist-bpfcc -rwxr-xr-x 1 root root 9973 Feb 7 2020 /sbin/btrfsslower-bpfcc -rwxr-xr-x 1 root root 4717 Feb 7 2020 /sbin/cachestat-bpfcc -rwxr-xr-x 1 root root 7302 Feb 7 2020 /sbin/cachetop-bpfcc -rwxr-xr-x 1 root root 6859 Feb 7 2020 /sbin/capable-bpfcc -rwxr-xr-x 1 root root 53 Feb 7 2020 /sbin/cobjnew-bpfcc -rwxr-xr-x 1 root root 5209 Feb 7 2020 /sbin/cpudist-bpfcc -rwxr-xr-x 1 root root 14597 Feb 7 2020 /sbin/cpuunclaimed-bpfcc -rwxr-xr-x 1 root root 8504 Feb 7 2020 /sbin/criticalstat-bpfcc -rwxr-xr-x 1 root root 7095 Feb 7 2020 /sbin/dbslower-bpfcc -rwxr-xr-x 1 root root 3780 Feb 7 2020 /sbin/dbstat-bpfcc -rwxr-xr-x 1 root root 3938 Feb 7 2020 /sbin/dcsnoop-bpfcc -rwxr-xr-x 1 root root 3920 Feb 7 2020 /sbin/dcstat-bpfcc -rwxr-xr-x 1 root root 19930 Feb 7 2020 /sbin/deadlock-bpfcc -rwxr-xr-x 1 root root 7051 Dec 10 2019 /sbin/deadlock.c-bpfcc -rwxr-xr-x 1 root root 6830 Feb 7 2020 /sbin/drsnoop-bpfcc -rwxr-xr-x 1 root root 7658 Feb 7 2020 /sbin/execsnoop-bpfcc -rwxr-xr-x 1 root root 10351 Feb 7 2020 /sbin/exitsnoop-bpfcc -rwxr-xr-x 1 root root 6482 Feb 7 2020 /sbin/ext4dist-bpfcc …
1 |
|
opensnoop-bpfcc
PID COMM FD ERR PATH 2522843 touch 3 0 /etc/ld.so.cache 2522843 touch 3 0 /lib/x86_64-linux-gnu/libc.so.6 2522843 touch 3 0 /usr/lib/locale/locale-archive 2522843 touch 3 0 /usr/share/locale/locale.alias 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_IDENTIFICATION 2522843 touch 3 0 /usr/lib/x86_64-linux-gnu/gconv/gconv-modules.cache 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MEASUREMENT 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_TELEPHONE 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_ADDRESS 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_NAME 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_PAPER 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MESSAGES 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MESSAGES/SYS_LC_MESSAGES 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MONETARY 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_COLLATE 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_TIME 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_NUMERIC 2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_CTYPE 2522843 touch 3 0 test-open
1 |
|
softirqs-bpfcc -d
Tracing soft irq event time… Hit Ctrl-C to end. ^C
softirq = block usecs : count distribution 0 -> 1 : 2 |******************** | 2 -> 3 : 3 |****************************** | 4 -> 7 : 2 |******************** | 8 -> 15 : 4 |****************************************|
softirq = rcu usecs : count distribution 0 -> 1 : 189 |***********************************| 2 -> 3 : 52 |*********** | 4 -> 7 : 21 | | 8 -> 15 : 5 | | 16 -> 31 : 1 | |
softirq = net_rx usecs : count distribution 0 -> 1 : 1 |******************** | 2 -> 3 : 0 | | 4 -> 7 : 2 || 8 -> 15 : 0 | | 16 -> 31 : 2 ||
softirq = timer usecs : count distribution 0 -> 1 : 16 |************* | 2 -> 3 : 49 |****************| 4 -> 7 : 43 |*********************************** | 8 -> 15 : 5 | | 16 -> 31 : 13 | | 32 -> 63 : 13 | |
softirq = sched usecs : count distribution 0 -> 1 : 18 |****** | 2 -> 3 : 107 |*********************************| 4 -> 7 : 20 | | 8 -> 15 : 1 | | 16 -> 31 : 1 | |
1 |
|
define BPF program
bpf_text = “”” #include <uapi/linux/ptrace.h> #include <uapi/linux/limits.h> #include <linux/sched.h>
…
BPF_HASH(infotmp, u64, struct val_t); //BPF_MAP_TYPE_HASH BPF_PERF_OUTPUT(events); // BPF_MAP_TYPE_PERF_EVENT_ARRAY
int trace_entry(struct pt_regs *ctx, int dfd, const char __user *filename, int flags) { … }
int trace_return(struct pt_regs *ctx) { … } “””
1 |
|
…
initialize BPF
b = BPF(text=bpf_text) b.attach_kprobe(event=”do_sys_open”, fn_name=”trace_entry”) b.attach_kretprobe(event=”do_sys_open”, fn_name=”trace_return”) …
loop with callback to print_event
b[“events”].open_perf_buffer(print_event, page_cnt=64) start_time = datetime.now() while not args.duration or datetime.now() - start_time < args.duration: try: b.perf_buffer_poll() except KeyboardInterrupt: exit() …
1 |
|
1 | def __init__(self, src_file=b"", hdr_file=b"", text=None, debug=0, |
… self.module = lib.bpf_module_create_c_from_string(text, self.debug,cflags_array, len(cflags_array), allow_rlimit, device) …
1 |
|
git remote -v
origin https://github.com/iovisor/bcc.git (fetch) origin https://github.com/iovisor/bcc.git (push)
cd libbpf-tools/
make V=1
mkdir -p .output mkdir -p .output/libbpf make -C /root/bcc/src/cc/libbpf/src BUILD_STATIC_ONLY=1
OBJDIR=/root/bcc/libbpf-tools/.output//libbpf DESTDIR=/root/bcc/libbpf-tools/.output/
INCLUDEDIR= LIBDIR= UAPIDIR=
Install …
ar rcs /root/bcc/libbpf-tools/.output//libbpf/libbpf.a …
…
clang -g -O2 -target bpf -D__TARGET_ARCH_x86
-I.output -c opensnoop.bpf.c -o .output/opensnoop.bpf.o &&
llvm-strip -g .output/opensnoop.bpf.o bin/bpftool gen skeleton .output/opensnoop.bpf.o > .output/opensnoop.skel.h cc -g -O2 -Wall -I.output -c opensnoop.c -o .output/opensnoop.o cc -g -O2 -Wall .output/opensnoop.o /root/bcc/libbpf-tools/.output/libbpf.a .output/trace_helpers.o .output/syscall_helpers.o .output/errno_helpers.o -lelf -lz -o opensnoop
…
1 |
|
cat opensnoop.bpf.c | head
// SPDX-License-Identifier: GPL-2.0 // Copyright (c) 2019 Facebook // Copyright (c) 2020 Netflix #include “vmlinux.h” #include <bpf/bpf_helpers.h> #include “opensnoop.h”
#define TASK_RUNNING 0
const volatile __u64 min_us = 0;
1 |
|
bin/bpftool gen skeleton .output/opensnoop.bpf.o > .output/opensnoop.skel.h
1 |
|
uname -r
5.10.4
ls -lh opensnoop
-rwxr-x— 1 root root 235K Jan 30 23:08 opensnoop
./opensnoop
PID COMM FD ERR PATH 2637411 opensnoop 24 0 /etc/localtime 1 systemd 28 0 /proc/746/cgroup
1 |
|
加餐04 理解ftrace(2):怎么理解ftrace背后的技术tracepoint和kprobe?
你好,我是程远。
前面两讲,我们分别学习了 perf 和 ftrace 这两个最重要 Linux tracing 工具。在学习过程中,我们把重点放在了这两个工具最基本的功能点上。
不过你学习完这些之后,我们内核调试版图的知识点还没有全部点亮。
如果你再去查看一些 perf、ftrace 或者其他 Linux tracing 相关资料,你可能会常常看到两个单词,“tracepoint”和“kprobe”。你有没有好奇过,这两个名词到底是什么意思,它们和 perf、ftrace 这些工具又是什么关系呢?
这一讲,我们就来学习这两个在 Linux tracing 系统中非常重要的概念,它们就是 tracepoint 和 kprobe。
tracepoint 和 kprobe 的应用举例
如果你深入地去看一些 perf 或者 ftrace 的功能,这时候你会发现它们都有跟 tracepoint、kprobe 相关的命令。我们先来看几个例子,通过这几个例子,你可以大概先了解一下 tracepoint 和 kprobe 的应用,这样我们后面做详细的原理介绍时,你也会更容易理解。
首先看看 tracepoint,tracepoint 其实就是在 Linux 内核的一些关键函数中埋下的 hook 点,这样在 tracing 的时候,我们就可以在这些固定的点上挂载调试的函数,然后查看内核的信息。
我们通过下面的这个 perf list 命令,就可以看到所有的 tracepoints:
1 | # perf list | grep Tracepoint |
至于 ftrace,你在 tracefs 文件系统中,也会看到一样的 tracepoints:
1 | # find /sys/kernel/debug/tracing/events -type d | sort |
为了让你更好理解,我们就拿“do_sys_open”这个 tracepoint 做例子。在内核函数 do_sys_open() 中,有一个 trace_do_sys_open() 调用,其实它这就是一个 tracepoint:
1 | long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode) |
接下来,我们可以通过 perf 命令,利用 tracepoint 来查看一些内核函数发生的频率,比如在节点上,统计 10 秒钟内调用 do_sys_open 成功的次数,也就是打开文件的次数。
1 | # # perf stat -a -e fs:do_sys_open -- sleep 10 |
同时,如果我们把 tracefs 中 do_sys_open 的 tracepoint 打开,那么在 ftrace 的 trace 输出里,就可以看到具体 do_sys_open 每次调用成功时,打开的文件名、文件属性、对应的进程等信息。
1 | # pwd |
请注意,Tracepoint 是在内核中固定的 hook 点,并不是在所有的函数中都有 tracepoint。
比如在上面的例子里,我们看到 do_sys_open() 调用到了 do_filp_open(),但是 do_filp_open() 函数里是没有 tracepoint 的。那如果想看到 do_filp_open() 函数被调用的频率,或者 do_filp_open() 在被调用时传入参数的情况,我们又该怎么办呢?
这时候,我们就需要用到 kprobe 了。kprobe 可以动态地在所有的内核函数(除了 inline 函数)上挂载 probe 函数。我们还是结合例子做理解,先看看 perf 和 ftraces 是怎么利用 kprobe 来做调试的。
比如对于 do_filp_open() 函数,我们可以通过perf probe添加一下,然后用perf stat 看看在 10 秒钟的时间里,这个函数被调用到的次数。
1 | # perf probe --add do_filp_open |
我们也可以通过 ftrace 的 tracefs 给 do_filp_open() 添加一个 kprobe event,这样就能查看 do_filp_open() 每次被调用的时候,前面两个参数的值了。
这里我要给你说明一下,在写入 kprobe_event 的时候,对于参数的定义我们用到了“%di”和“%si”。这是 x86 处理器里的寄存器,根据 x86 的Application Binary Interface 的文档,在函数被调用的时候,%di 存放了第一个参数,%si 存放的是第二个参数。
1 | # echo 'p:kprobes/myprobe do_filp_open dfd=+0(%di):u32 pathname=+0(+0(%si)):string' > /sys/kernel/debug/tracing/kprobe_event |
完成上面的写入之后,我们再 enable 这个新建的 kprobe event。这样在 trace 中,我们就可以看到每次 do_filp_open()被调用时前两个参数的值了。
1 | # echo 1 > /sys/kernel/debug/tracing/events/kprobes/myprobe/enable |
好了,我们通过 perf 和 ftrace 的几个例子,简单了解了 tracepoint 和 kprobe 是怎么用的。那下面我们再来看看它们的实现原理。
Tracepoint
刚才,我们已经看到了内核函数 do_sys_open() 里调用了 trace_do_sys_open() 这个 treacepoint,那这个 tracepoint 是怎么实现的呢?我们还要再仔细研究一下。
如果你在内核代码中,直接搜索“trace_do_sys_open”字符串的话,并不能找到这个函数的直接定义。这是因为在 Linux 中,每一个 tracepoint 的相关数据结构和函数,主要是通过”DEFINE_TRACE”和”DECLARE_TRACE”这两个宏来定义的。
完整的“DEFINE_TRACE”和“DECLARE_TRACE”宏里,给每个 tracepoint 都定义了一组函数。在这里,我会选择最主要的几个函数,把定义一个 tracepoint 的过程给你解释一下。
首先,我们来看“trace_##name”这个函数(提示一下,这里的“##”是 C 语言的预编译宏,表示把两个字符串连接起来)。
对于每个命名为“name”的 tracepoint,这个宏都会帮助它定一个函数。这个函数的格式是这样的,以“trace_”开头,再加上 tracepoint 的名字。
我们举个例子吧。比如说,对于“do_sys_open”这个 tracepoint,它生成的函数名就是 trace_do_sys_open。而这个函数会被内核函数 do_sys_open() 调用,从而实现了一个内核的 tracepoint。
1 | static inline void trace_##name(proto) \ |
在这个 tracepoint 函数里,主要的功能是这样实现的,通过 __DO_TRACE 来调用所有注册在这个 tracepoint 上的 probe 函数。
1 | #define __DO_TRACE(tp, proto, args, cond, rcuidle) \ |
而 probe 函数的注册,它可以通过宏定义的“register_trace_##name”函数完成。
1 | static inline int \ |
我们可以自己写一个简单kernel module来注册一个 probe 函数,把它注册到已有的 treacepoint 上。这样,这个 probe 函数在每次 tracepoint 点被调用到的时候就会被执行。你可以动手试一下。
好了,说到这里,tracepoint 的实现方式我们就讲完了。简单来说就是在内核代码中需要被 trace 的地方显式地加上 hook 点,然后再把自己的 probe 函数注册上去,那么在代码执行的时候,就可以执行 probe 函数。
Kprobe
我们已经知道了,tracepoint 为内核 trace 提供了 hook 点,但是这些 hook 点需要在内核源代码中预先写好。如果在 debug 的过程中,我们需要查看的内核函数中没有 hook 点,就需要像前面 perf/ftrace 的例子中那样,要通过 Linux kprobe 机制来加载 probe 函数。
那我们要怎么来理解 kprobe 的实现机制呢?
你可以先从内核 samples 代码里,看一下
kprobe_example.c代码。这段代码里实现了一个 kernel module,可以在内核中任意一个函数名 / 符号对应的代码地址上注册三个 probe 函数,分别是“pre_handler”、 “post_handler”和“fault_handler”。
1 | #define MAX_SYMBOL_LEN 64 |
当这个内核函数被执行的时候,已经注册的 probe 函数也会被执行 (handler_fault 只有在发生异常的时候才会被调用到)。
比如,我们加载的这个 kernel module 不带参数,那么缺省的情况就是这样的:在“_do_fork”内核函数的入口点注册了这三个 probe 函数。
当 _do_fork() 函数被调用到的时候,换句话说,也就是创建新的进程时,我们通过 dmesg 就可以看到 probe 函数的输出了。
1 | [8446287.087641] <_do_fork> pre_handler: p->addr = 0x00000000d301008e, ip = ffffffffb1e8c9d1, flags = 0x246 |
kprobe 的基本工作原理其实也很简单。当 kprobe 函数注册的时候,其实就是把目标地址上内核代码的指令码,替换成了“cc”,也就是 int3 指令。这样一来,当内核代码执行到这条指令的时候,就会触发一个异常而进入到 Linux int3 异常处理函数 do_int3() 里。
在 do_int3() 这个函数里,如果发现有对应的 kprobe 注册了 probe,就会依次执行注册的 pre_handler(),原来的指令,最后是 post_handler()。
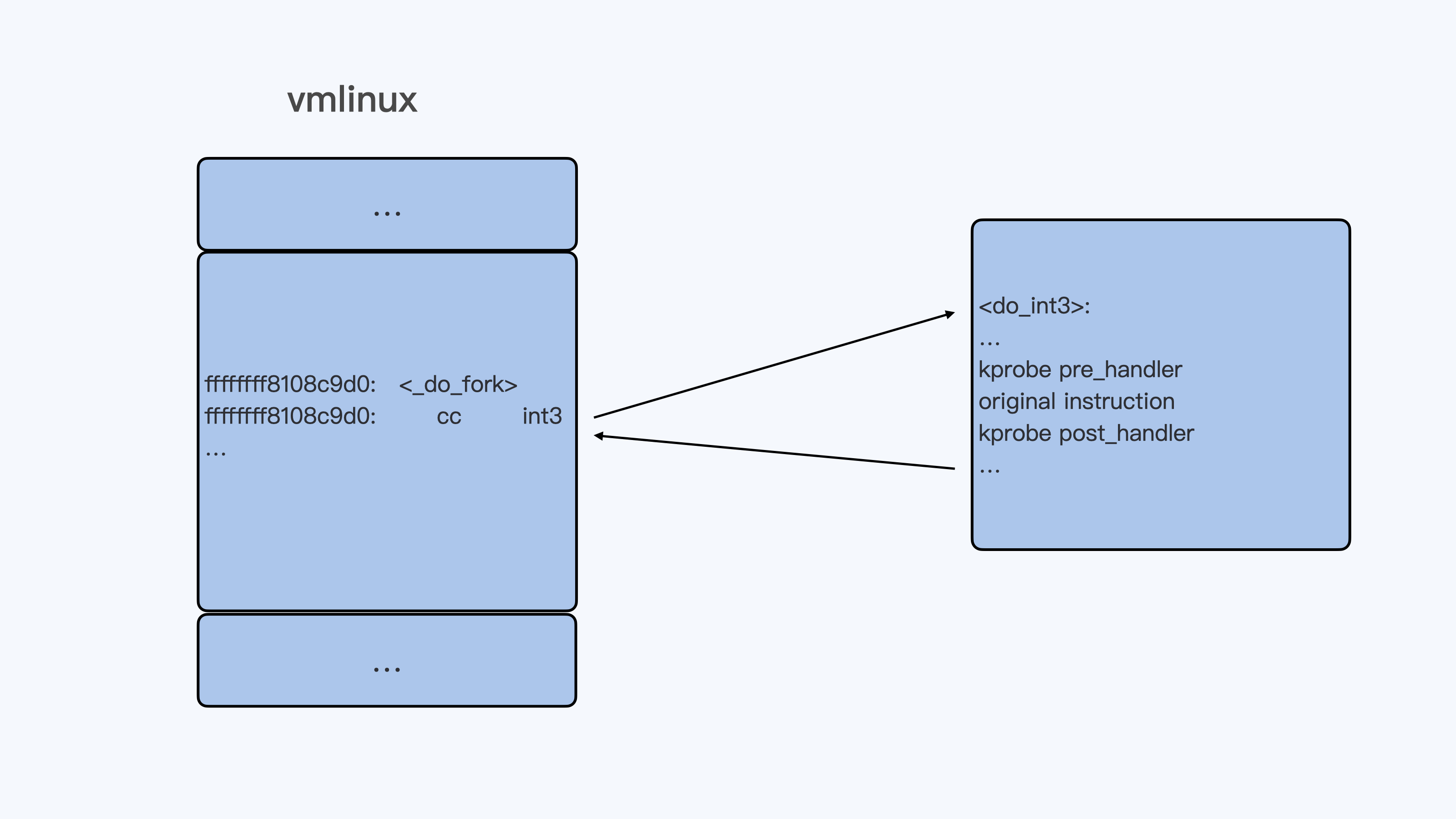
理论上 kprobe 其实只要知道内核代码中任意一条指令的地址,就可以为这个地址注册 probe 函数,kprobe 结构中的“addr”成员就可以接受内核中的指令地址。
1 | static int __init kprobe_init(void) |
还要说明的是,如果内核可以使用我们上一讲 ftrace 对函数的 trace 方式,也就是函数头上预留了“callq <**fentry**>”的 5 个字节(在启动的时候被替换成了 nop)。Kprobe 对于函数头指令的 trace 方式,也会用“ftrace_caller”指令替换的方式,而不再使用 int3 指令替换。
不论是哪种替换方式,kprobe 的基本实现原理都是一样的,那就是把目标指令替换,替换的指令可以使程序跑到一个特定的 handler 里,去执行 probe 的函数。
重点小结
这一讲我们主要学习了 tracepoint 和 kprobe,这两个概念在 Linux tracing 系统中非常重要。
为什么说它们重要呢?因为从 Linux tracing 系统看,我的理解是可以大致分成大致这样三层。
第一层是最基础的提供数据的机制,这里就包含了 tracepoints、kprobes,还有一些别的 events,比如 perf 使用的 HW/SW events。
第二层是进行数据收集的工具,这里包含了 ftrace、perf,还有 ebpf。
第三层是用户层工具。虽然有了第二层,用户也可以得到数据。不过,对于大多数用户来说,第二层使用的友好程度还不够,所以又有了这一层。
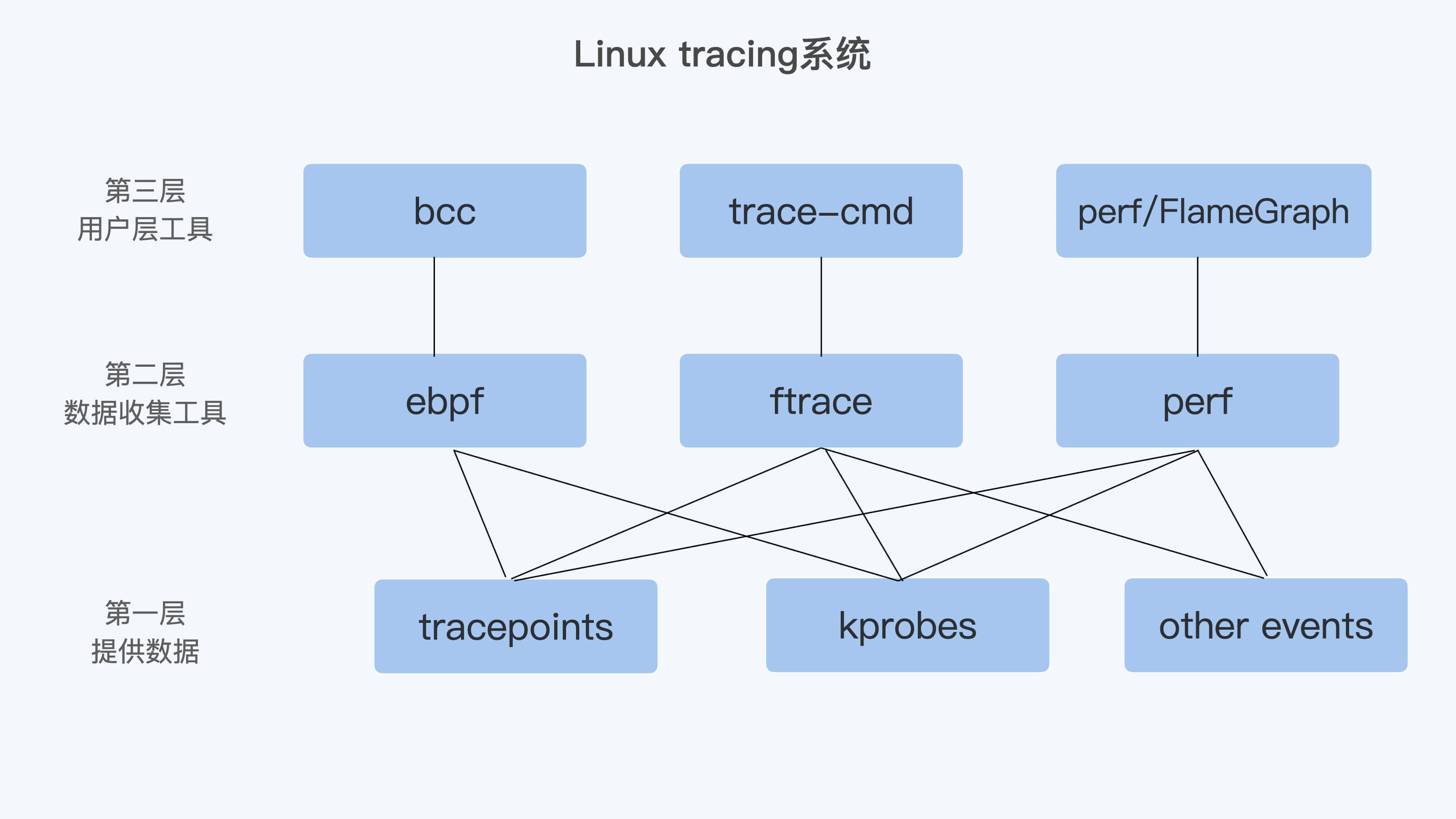
很显然,如果要对 Linux 内核调试,很难绕过 tracepoint 和 kprobe。如果不刨根问底的话,前面我们讲的 perf、trace 工具对你来说还是黑盒。因为你只是知道了这些工具怎么用,但是并不知道它们依赖的底层技术。
在后面介绍 ebpf 的时候,我们还会继续学习 ebpf 是如何使用 tracepoint 和 kprobe 来做 Linux tracing 的,希望你可以把相关知识串联起来。
思考题
想想看,当我们用 kprobe 为一个内核函数注册了 probe 之后,怎样能看到对应内核函数的第一条指令被替换了呢?
欢迎你在留言区记录你的思考或者疑问。如果这一讲对你有帮助,也欢迎你转发给同事、朋友,跟他们一起交流、进步。
加餐02 理解perf:怎么用perf聚焦热点函数?
你好,我是程远。今天我要和你聊一聊容器中如何使用 perf。
上一讲中,我们分析了一个生产环境里的一个真实例子,由于节点中的大量的 IPVS 规则导致了容器在往外发送网络包的时候,时不时会有很高的延时。在调试分析这个网络延时问题的过程中,我们会使用多种 Linux 内核的调试工具,利用这些工具,我们就能很清晰地找到这个问题的根本原因。
在后面的课程里,我们会挨个来讲解这些工具,其中 perf 工具的使用相对来说要简单些,所以这一讲我们先来看 perf 这个工具。
问题回顾
在具体介绍 perf 之前,我们先来回顾一下,上一讲中,我们是在什么情况下开始使用 perf 工具的,使用了 perf 工具之后给我们带来了哪些信息。
在调试网路延时的时候,我们使用了 ebpf 的工具之后,发现了节点上一个 CPU,也就是 CPU32 的 Softirq CPU Usage(在运行 top 时,%Cpu 那行中的 si 数值就是 Softirq CPU Usage)时不时地会增高一下。
在发现 CPU Usage 异常增高的时候,我们肯定想知道是什么程序引起了 CPU Usage 的异常增高,这时候我们就可以用到 perf 了。
具体怎么操作呢?我们可以通过抓取数据、数据读取和异常聚焦三个步骤来实现。
第一步,抓取数据。当时我们运行了下面这条 perf 命令,这里的参数 -C 32 是指定只抓取 CPU32 的执行指令;-g 是指 call-graph enable,也就是记录函数调用关系; sleep 10 主要是为了让 perf 抓取 10 秒钟的数据。
1 | # perf record -C 32 -g -- sleep 10 |
执行完 perf record 之后,我们可以用 perf report 命令进行第二步,也就是读取数据。为了更加直观地看到 CPU32 上的函数调用情况,我给你生成了一个火焰图(火焰图的生产方法,我们在后面介绍)。
通过这个火焰图,我们发现了在 Softirq 里 TIMER softirq (run_timer_softirq)的占比很高,并且 timer 主要处理的都是 estimation_timer() 这个函数,也就是看火焰图 X 轴占比比较大的函数。这就是第三步异常聚焦,也就是说我们通过 perf 在 CPU Usage 异常的 CPU32 上,找到了具体是哪一个内核函数使用占比较高。这样在后面的调试分析中,我们就可以聚焦到这个内核函数 estimation_timer() 上了。
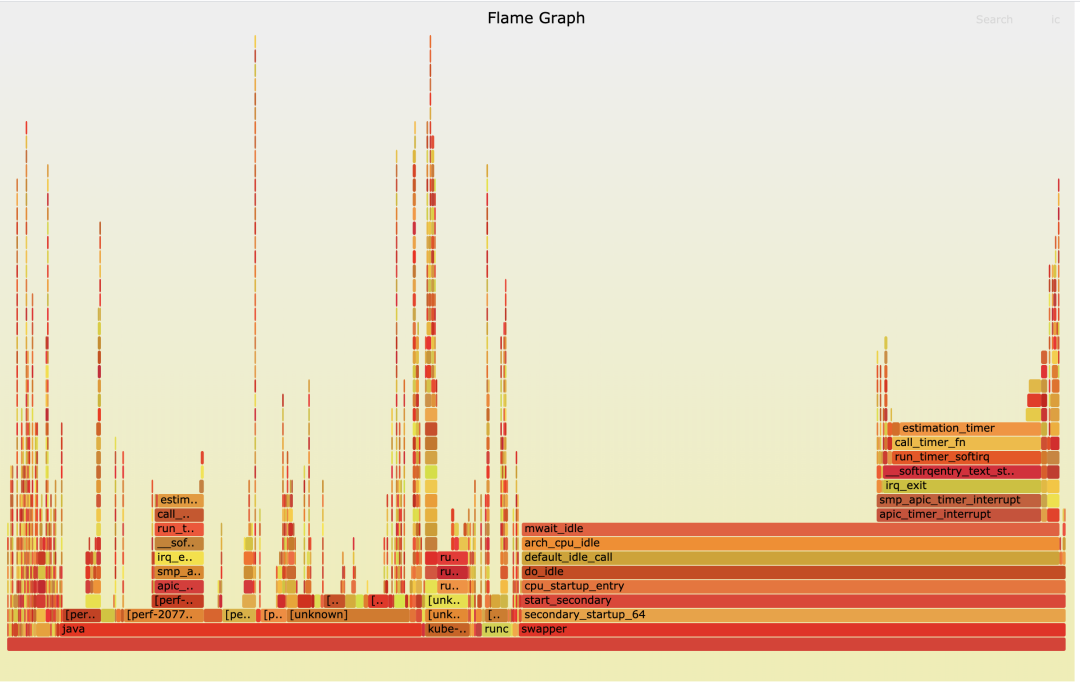
好了,通过回顾我们在网络延时例子中是如何使用 perf 的,我们知道了这一点,perf 可以在 CPU Usage 增高的节点上找到具体的引起 CPU 增高的函数,然后我们就可以有针对性地聚焦到那个函数做分析。
既然 perf 工具这么有用,想要更好地使用这个工具,我们就要好好认识一下它,那我们就一起看看 perf 的基本概念和常用的使用方法。
如何理解 Perf 的概念和工作机制?
Perf 这个工具最早是 Linux 内核著名开发者 Ingo Molnar 开发的,它的源代码在内核源码tools 目录下,在每个 Linux 发行版里都有这个工具,比如 CentOS 里我们可以运行 yum install perf 来安装,在 Ubuntu 里我们可以运行 apt install linux-tools-common 来安装。
Event
第一次上手使用 perf 的时候,我们可以先运行一下 perf list 这个命令,然后就会看到 perf 列出了大量的 event,比如下面这个例子就列出了常用的 event。
1 | # perf list |
从这里我们可以了解到 event 都有哪些类型, perf list 列出的每个 event 后面都有一个”[]“,里面写了这个 event 属于什么类型,比如”Hardware event”、”Software event”等。完整的 event 类型,我们在内核代码枚举结构 perf_type_id 里可以看到。
接下来我们就说三个主要的 event,它们分别是 Hardware event、Software event 还有 Tracepoints event。
Hardware event
Hardware event 来自处理器中的一个 PMU(Performance Monitoring Unit),这些 event 数目不多,都是底层处理器相关的行为,perf 中会命名几个通用的事件,比如 cpu-cycles,执行完成的 instructions,Cache 相关的 cache-misses。
不同的处理器有自己不同的 PMU 事件,对于 Intel x86 处理器,PMU 的使用和编程都可以在“Intel 64 and IA-32 Architectures Developer’s Manual: Vol. 3B”(Intel 架构的开发者手册)里查到。
我们运行一下 perf stat ,就可以看到在这段时间里这些 Hardware event 发生的数目。
1 | # perf stat |
Software event
Software event 是定义在 Linux 内核代码中的几个特定的事件,比较典型的有进程上下文切换(内核态到用户态的转换)事件 context-switches、发生缺页中断的事件 page-faults 等。
为了让你更容易理解,这里我举个例子。就拿 page-faults 这个 perf 事件来说,我们可以看到,在内核代码处理缺页中断的函数里,就是调用了 perf_sw_event() 来注册了这个 page-faults。
1 | /* |
Tracepoints event
你可以在 perf list 中看到大量的 Tracepoints event,这是因为内核中很多关键函数里都有 Tracepoints。它的实现方式和 Software event 类似,都是在内核函数中注册了 event。
不过,这些 tracepoints 不仅是用在 perf 中,它已经是 Linux 内核 tracing 的标准接口了,ftrace,ebpf 等工具都会用到它,后面我们还会再详细介绍 tracepoint。
好了,讲到这里,你要重点掌握的内容是,event 是 perf 工作的基础,主要有两种:有使用硬件的 PMU 里的 event,也有在内核代码中注册的 event。
那么在这些 event 都准备好了之后,perf 又是怎么去使用这些 event 呢?前面我也提到过,有计数和采样两种方式,下面我们分别来看看。
计数(count)
计数的这种工作方式比较好理解,就是统计某个 event 在一段时间里发生了多少次。
那具体我们怎么进行计数的呢?perf stat 这个命令就是来查看 event 的数目的,前面我们已经运行过 perf stat 来查看所有的 Hardware events。
这里我们可以加上”-e”参数,指定某一个 event 来看它的计数,比如 page-faults,这里我们看到在当前 CPU 上,这个 event 在 1 秒钟内发生了 49 次:
1 | # perf stat -e page-faults -- sleep 1 |
采样(sample)
说完了计数,我们再来看看采样。在开头回顾网路延时问题的时候,我提到通过 perf record -C 32 -g -- sleep 10 这个命令,来找到 CPU32 上 CPU 开销最大的 Softirq 相关函数。这里使用的 perf record 命令就是通过采样来得到热点函数的,我们来分析一下它是怎么做的。
perf record 在不加 -e 指定 event 的时候,它缺省的 event 就是 Hardware event cycles。我们先用 perf stat来查看 1 秒钟 cycles 事件的数量,在下面的例子里这个数量是 1878165 次。
我们可以想一下,如果每次 cycles event 发生的时候,我们都记录当时的 IP(就是处理器当时要执行的指令地址)、IP 所属的进程等信息的话,这样系统的开销就太大了。所以 perf 就使用了对 event 采样的方式来记录 IP、进程等信息。
1 | # perf stat -e cycles -- sleep 1 |
Perf 对 event 的采样有两种模式:
第一种是按照 event 的数目(period),比如每发生 10000 次 cycles event 就记录一次 IP、进程等信息, perf record 中的 -c 参数可以指定每发生多少次,就做一次记录。
比如在下面的例子里,我们指定了每 10000 cycles event 做一次采样之后,在 1 秒里总共就做了 191 次采样,比我们之前看到 1 秒钟 1878165 次 cycles 的次数要少多了。
1 | # perf record -e cycles -c 10000 -- sleep 1 |
第二种是定义一个频率(frequency), perf record 中的 -F 参数就是指定频率的,比如 perf record -e cycles -F 99 -- sleep 1 ,就是指采样每秒钟做 99 次。
在 perf record 运行结束后,会在磁盘的当前目录留下 perf.data 这个文件,里面记录了所有采样得到的信息。然后我们再运行 perf report 命令,查看函数或者指令在这些采样里的分布比例,后面我们会用一个例子说明。
好,说到这里,我们已经把 perf 的基本概念和使用机制都讲完了。接下来,我们看看在容器中怎么使用 perf?
容器中怎样使用 perf?
如果你的 container image 是基于 Ubuntu 或者 CentOS 等 Linux 发行版的,你可以尝试用它们的 package repo 安装 perf 的包。不过,这么做可能会有个问题,我们在前面介绍 perf 的时候提过,perf 是和 Linux kernel 一起发布的,也就是说 perf 版本最好是和 Linux kernel 使用相同的版本。
如果容器中 perf 包是独立安装的,那么容器中安装的 perf 版本可能会和宿主机上的内核版本不一致,这样有可能导致 perf 无法正常工作。
所以,我们在容器中需要跑 perf 的时候,最好从相应的 Linux kernel 版本的源代码里去编译,并且采用静态库(-static)的链接方式。然后,我们把编译出来的 perf 直接 copy 到容器中就可以使用了。
如何在 Linux kernel 源代码里编译静态链接的 perf,你可以参考后面的代码:
1 | # cd $(KERNEL_SRC_ROOT)/tools/perf |
我这里给了一个带静态链接 perf(kernel 5.4)的 container image例子,你可以运行 make image 来生成这个 image。
在容器中运行 perf,还要注意一个权限的问题,有两点注意事项需要你留意。
第一点,Perf 通过系统调用 perf_event_open() 来完成对 perf event 的计数或者采样。不过 Docker 使用 seccomp(seccomp 是一种技术,它通过控制系统调用的方式来保障 Linux 安全)会默认禁止 perf_event_open()。
所以想要让 Docker 启动的容器可以运行 perf,我们要怎么处理呢?
其实这个也不难,在用 Docker 启动容器的时候,我们需要在 seccomp 的 profile 里,允许 perf_event_open() 这个系统调用在容器中使用。在我们的例子中,启动 container 的命令里,已经加了这个参数允许了,参数是”–security-opt seccomp=unconfined”。
第二点,需要允许容器在没有 SYS_ADMIN 这个 capability(Linux capability 我们在第 19 讲说过)的情况下,也可以让 perf 访问这些 event。那么现在我们需要做的就是,在宿主机上设置出 echo -1 > /proc/sys/kernel/perf_event_paranoid,这样普通的容器里也能执行 perf 了。
完成了权限设置之后,在容器中运行 perf,就和在 VM/BM 上运行没有什么区别了。
最后,我们再来说一下我们在定位 CPU Uage 异常时最常用的方法,常规的步骤一般是这样的:
首先,调用 perf record 采样几秒钟,一般需要加 -g 参数,也就是 call-graph,还需要抓取函数的调用关系。在多核的机器上,还要记得加上 -a 参数,保证获取所有 CPU Core 上的函数运行情况。至于采样数据的多少,在讲解 perf 概念的时候说过,我们可以用 -c 或者 -F 参数来控制。
接着,我们需要运行 perf report 读取数据。不过很多时候,为了更加直观地看到各个函数的占比,我们会用 perf script 命令把 perf record 生成的 perf.data 转化成分析脚本,然后用 FlameGraph 工具来读取这个脚本,生成火焰图。
下面这组命令,就是刚才说过的使用 perf 的常规步骤:
1 | # perf record -a -g -- sleep 60 |
重点总结
我们这一讲学习了如何使用 perf,这里我来给你总结一下重点。
首先,我们在线上网络延时异常的那个实际例子中使用了 perf。我们发现可以用 perf 工具,通过抓取数据、数据读取和异常聚焦这三个步骤的操作,在 CPU Usage 增高的节点上找到具体引起 CPU 增高的函数。
之后我带你更深入地学习了 perf 是什么,它的工作方式是怎样的?这里我把 perf 的重点再给你强调一遍:
Perf 的实现基础是 event,有两大类,一类是基于硬件 PMU 的,一类是内核中的软件注册。而 Perf 在使用时的工作方式也是两大类,计数和采样。
先看一下计数,它执行的命令是 perf stat,用来查看每种 event 发生的次数;
采样执行的命令是perf record,它可以使用 period 方式,就是每 N 个 event 发生后记录一次 event 发生时的 IP/ 进程信息,或者用 frequency 方式,每秒钟以固定次数来记录信息。记录的信息会存在当前目录的 perf.data 文件中。
如果我们要在容器中使用 perf,要注意这两点:
容器中的 perf 版本要和宿主机内核版本匹配,可以直接从源代码编译出静态链接的 perf。
我们需要解决两个权限的问题,一个是 seccomp 对系统调用的限制,还有一个是内核对容器中没有 SYC_ADMIN capability 的限制。
在我们日常分析系统性能异常的时候,使用 perf 最常用的方式是perf record获取采样数据,然后用 FlameGraph 工具来生成火焰图。
思考题
你可以在自己的一台 Linux 机器上运行一些带负载的程序,然后使用 perf 并且生成火焰图,看看开销最大的函数是哪一个。
欢迎在留言区分享你的疑惑和见解。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
加餐福利 课后思考题答案合集
你好,我是程远,好久不见。
距离我们的专栏更新结束,已经过去了不少时间。我仍然会在工作之余,到这门课的留言区转一转,回答同学的问题。大部分的疑问,我都通过留言做了回复。
除了紧跟更新的第一批同学,也很开心有更多新朋友加入到这个专栏的学习中。那课程的思考题呢,为了给你留足思考和研究的时间,我选择用加餐的方式,给你提供参考答案。
这里我想和你说明的是,我这里给你提供的参考答案,都是我能够直接给你特定答案的问题。至于操作类的题目,有的我引用了同学回复的答案。
另外一类操作题,是为了帮你巩固课程内容知识的,相信你可以从课程正文里找到答案。我还是建议你自己动手实战,这样你的收获会更大。
必学部分思考题
第 2 讲
Q:对于这一讲的最开始,有这样一个 C 语言的 init 进程,它没有注册任何信号的 handler。如果我们从 Host Namespace 向它发送 SIGTERM,会发生什么情况呢?
A:即使在宿主机上向容器 1 号进程发送 SIGTERM,在 1 号进程没有注册 handler 的情况下,这个进程也不能被杀死。
这个问题的原因是这样的:开始要看内核里的那段代码,“ !(force && sig_kernel_only(sig))”,
虽然由不同的 namespace 发送信号, 虽然 force 是 1 了,但是 sig_kernel_only(sig) 对于 SIGTERM 来说还是 0,这里是个 &&, 那么 !(1 && 0) = 1。
1 | #define sig_kernel_only(sig) siginmask(sig, SIG_KERNEL_ONLY_MASK) |
第 3 讲
Q:如果容器的 init 进程创建了子进程 B,B 又创建了自己的子进程 C。如果 C 运行完之后,退出成了僵尸进程,B 进程还在运行,而容器的 init 进程还在不断地调用 waitpid(),那 C 这个僵尸进程可以被回收吗?
A:这道题可以参考下面两位同学的回答。
Geek2014 用户的回答:
这时 C 是不会被回收的,只有等到 B 也被杀死,C 这个僵尸进程也会变成孤儿进程,被 init 进程收养,进而被 init 的 wait 机制清理掉。
莫名同学的回答:
C 应该不会被回收,waitpid 仅等待直接 children 的状态变化。
为什么先进入僵尸状态而不是直接消失?觉得是留给父进程一次机会,查看子进程的 PID、终止状态(退出码、终止原因,比如是信号终止还是正常退出等)、资源使用信息。如果子进程直接消失,那么父进程没有机会掌握子进程的具体终止情况。
一般情况下,程序逻辑可能会依据子进程的终止情况做出进一步处理:比如 Nginx Master 进程获知 Worker 进程异常退出,则重新拉起来一个 Worker 进程。
第 4 讲
Q:请你回顾一下基本概念中最后的这段代码,你可以想一想,在不做编译运行的情况下,它的输出是什么?
1 | #include <stdio.h> |
A:可以参考用户 geek 2014 同学的答案。输出结果如下:
Ignore SIGTERM
Catch SIGTERM
received SIGTERM
Default SIGTERM
第 5 讲
Q:我们还是按照文档中定义的控制组目录层次结构图,然后按序执行这几个脚本:
create_groups.sh
update_group1.sh
update_group4.sh
update_group3.sh
那么,在一个 4 个 CPU 的节点上,group1/group3/group4 里的进程,分别会被分配到多少 CPU 呢?
A:分配比例是: 2 : 0.5 : 1.5
可以参考 geek 2014 的答案:
group1 的 shares 为 1024,quota 3.5,尝试使用 4,
group2 的 shares 默认为 1024,quota 设置为 -1,不受限制,也即是,如果 CPU 上只有 group2 的话,那么 group2 可以使用完所有的 CPU(实际上根据 group3 和 group4,group2 最多也就能用到 1.5+3.5 core)
故而,group1 和 group2 各分配到 2。把 group2 分到的 2CPU,看作总量,再次分析 group3 和 group4。group3 和 group3 尝试使用的总量超过 2,所以按照 shares 比例分配,group3 使用 1/(1+3) * 2 = 0.5,group4 使用 3/(1+3) * 2 = 1.5
第 6 讲
Q:写一个小程序,在容器中执行,它可以显示当前容器中所有进程总的 CPU 使用率。
A:上邪忘川的回答可以作为一个参考。
1 | #!/bin/bash |
第 8 讲
Q:在我们的例子脚本基础上,你可以修改一下,在容器刚一启动,就在容器对应的 Memory Cgroup 中禁止 OOM,看看接下来会发生什么?
A:通过“memory.oom_control”禁止 OOM 后,在容器中的进程不会发生 OOM,但是也无法申请出超过“memory.limit_in_bytes”内存。
1 | # cat start_container.sh |
第 10 讲
Q:在一个有 Swap 分区的节点上用 Docker 启动一个容器,对它的 Memory Cgroup 控制组设置一个内存上限 N,并且将 memory.swappiness 设置为 0。这时,如果在容器中启动一个不断读写文件的程序,同时这个程序再申请 1/2N 的内存,请你判断一下,Swap 分区中会有数据写入吗?
A:Memory Cgroup 参数 memory.swappiness 起到局部控制的作用,因为已经设置了 memory.swappiness 参数,全局参数 swappiness 参数失效,那么容器里就不能使用 swap 了。
第 11 讲
Q:在这一讲 OverlayFS 的例子的基础上,建立 2 个 lowerdir 的目录,并且在目录中建立相同文件名的文件,然后一起做一个 overlay mount,看看会发生什么?
A:这里引用上邪忘川同学的实验结果。
实验过程如下,结果是 lower1 目录中的文件覆盖了 lower2 中同名的文件, 第一个挂载的目录优先级比较高
1 | [[[email protected] ~]# cat overlay.sh |
第 12 讲
Q:在正文知识详解的部分,我们使用”xfs_quota”给目录打了 project ID 并且限制了文件写入的数据量。那么在做完限制之后,我们是否能用 xfs_quota 命令,查询到被限制目录的 project ID 和限制的数据量呢?
A:xfs_quota 不能直接得到一个目录的 quota 大小的限制,只可以看到 project ID 上的 quota 限制,不过我们可以用这段程序来获得目录对应的 project ID。
1 | # xfs_quota -x -c 'report -h /' |
第 13 讲
Q:这是一道操作题,通过这个操作你可以再理解一下 blkio Cgroup 与 Buffered I/O 的关系。
在 Cgroup V1 的环境里,我们在 blkio Cgroup V1 的例子基础上,把 fio 中“-direct=1”参数去除之后,再运行 fio,同时运行 iostat 查看实际写入磁盘的速率,确认 Cgroup V1 blkio 无法对 Buffered I/O 限速。
A: 这是通过 iostat 看到磁盘的写入速率,是可以突破 cgroup V1 blkio 中的限制值的。
第 17 讲
Q:在这节课的最后,我提到“由于 ipvlan/macvlan 网络接口直接挂载在物理网络接口上,对于需要使用 iptables 规则的容器,比如 Kubernetes 里使用 service 的容器,就不能工作了”,请你思考一下这个判断背后的具体原因。
A:ipvlan/macvlan 工作在网络 2 层,而 iptables 工作在网络 3 层。所以用 ipvlan/macvlan 为容器提供网络接口,那么基于 iptables 的 service 服务就不工作了。
第 18 讲
Q:在这一讲中,我们提到了 Linux 内核中的 tcp_force_fast_retransmit() 函数,那么你可以想想看,这个函数中的 tp->recording 和内核参数 /proc/sys/net/ipv4/tcp_reordering 是什么关系?它们对数据包的重传会带来什么影响?
1 | static bool tcp_force_fast_retransmit(struct sock *sk) |
A: 在 TCP 链接建立的时候,tp->reordering 默认值是从 /proc/sys/net/ipv4/tcp_reordering(默认值为 3)获取的。之后根据网络的乱序情况,进行动态调整,最大可以增长到 /proc/sys/net/ipv4/tcp_max_reordering (默认值为 300) 的大小。
第 20 讲
Q:我在这一讲里提到了 rootless container,不过对于 rootless container 的支持,还存在着不少的难点,比如容器网络的配置、Cgroup 的配置,你可以去查阅一些资料,看看 podman 是怎么解决这些问题的。
A:可以阅读一下这篇文档。
专题加餐
专题 03
Q:我们讲 ftrace 实现机制时,说过内核中的“inline 函数”不能被 ftrace 到,你知道这是为什么吗?那么内核中的“static 函数”可以被 ftrace 追踪到吗?
A:inline 函数在编译的时候被展开了,所以不能被 ftrace 到。而 static 函数需要看情况,如果加了编译优化参数“-finline-functions-called-once”,对于只被调用到一次的 static 函数也会当成 inline 函数处理,那么也不能被 ftrace 追踪到了。
专题 04
Q:想想看,当我们用 kprobe 为一个内核函数注册了 probe 之后,怎样能看到对应内核函数的第一条指令被替换了呢?
A:首先可以参考莫名同学的答案:
关于思考题,想到一个比较笨拙的方法:gdb+qemu 调试内核。先进入虚拟机在某个内核函数上注册一个 kprobe,然后 gdb 远程调试内核,查看该内核函数的汇编指令(disass)是否被替换。应该有更简单的方法,这方面了解不深。
另外,我们用 gdb 远程调试内核看也可以。还可以通过 /proc/kallsyms 找到函数的地址,然后写个 kernel module 把从这个地址开始后面的几个字节 dump 出来,比较一下 probe 函数注册前后的值。
加餐05 eBPF:怎么更加深入地查看内核中的函数?
你好,我是程远。
今天这一讲,我们聊一聊 eBPF。在我们专题加餐第一讲的分析案例时就说过,当我们碰到网络延时问题,在毫无头绪的情况下,就是依靠了我们自己写的一个 eBPF 工具,找到了问题的突破口。
由此可见,eBPF 在内核问题追踪上的重要性是不言而喻的。那什么是 eBPF,它的工作原理是怎么样,它的编程模型又是怎样的呢?
在这一讲里,我们就来一起看看这几个问题。
eBPF 的概念
eBPF,它的全称是“Extended Berkeley Packet Filter”。从名字看,你可能会觉奇怪,似乎它就是一个用来做网络数据包过滤的模块。
其实这么想也没有错,eBPF 的概念最早源自于 BSD 操作系统中的 BPF(Berkeley Packet Filter),1992 伯克利实验室的一篇论文 “The BSD Packet Filter: A New Architecture for User-level Packet Capture”。这篇论文描述了,BPF 是如何更加高效灵活地从操作系统内核中抓取网络数据包的。
我们很熟悉的 tcpdump 工具,它就是利用了 BPF 的技术来抓取 Unix 操作系统节点上的网络包。Linux 系统中也沿用了 BPF 的技术。
那 BPF 是怎样从内核中抓取数据包的呢?我借用 BPF 论文中的图例来解释一下:
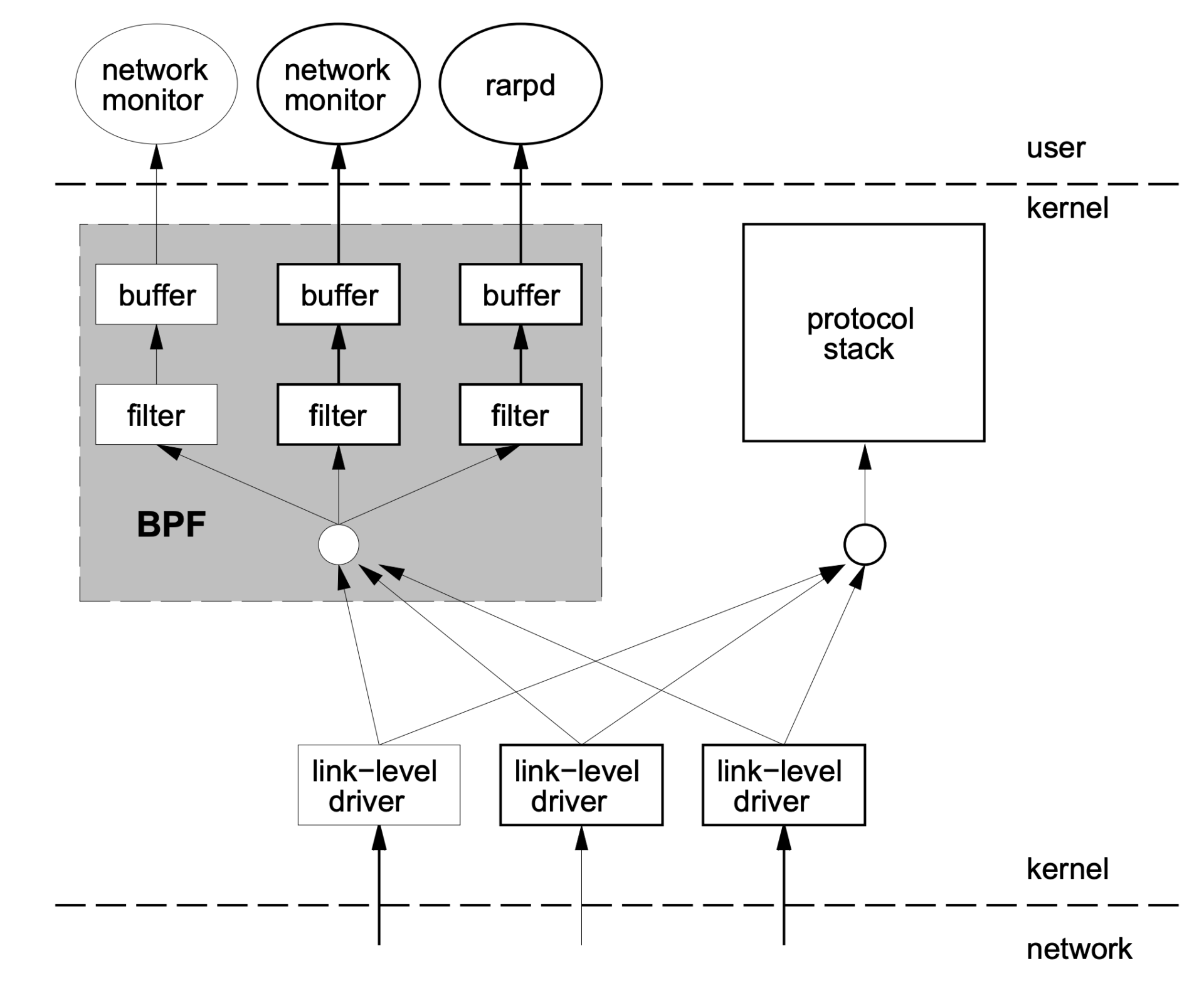
结合这张图,我们一起看看 BPF 实现有哪些特点。
第一,内核中实现了一个虚拟机,用户态程序通过系统调用,把数据包过滤代码载入到个内核态虚拟机中运行,这样就实现了内核态对数据包的过滤。这一块对应图中灰色的大方块,也就是 BPF 的核心。
第二,BPF 模块和网络协议栈代码是相互独立的,BPF 只是通过简单的几个 hook 点,就能从协议栈中抓到数据包。内核网络协议代码变化不影响 BPF 的工作,图中右边的“protocol stack”方块就是指内核网络协议栈。
第三,内核中的 BPF filter 模块使用 buffer 与用户态程序进行通讯,把 filter 的结果返回给用户态程序(例如图中的 network monitor),这样就不会产生内核态与用户态的上下文切换(context switch)。
在 BPF 实现的基础上,Linux 在 2014 年内核 3.18 的版本上实现了 eBPF,全名是 Extended BPF,也就是 BPF 的扩展。这个扩展主要做了下面这些改进。
首先,对虚拟机做了增强,扩展了寄存器和指令集的定义,提高了虚拟机的性能,并且可以处理更加复杂的程序。
其次,增加了 eBPF maps,这是一种存储类型,可以保存状态信息,从一个 BPF 事件的处理函数传递给另一个,或者保存一些统计信息,从内核态传递给用户态程序。
最后,eBPF 可以处理更多的内核事件,不再只局限在网络事件上。你可以这样来理解,eBPF 的程序可以在更多内核代码 hook 点上注册了,比如 tracepoints、kprobes 等。
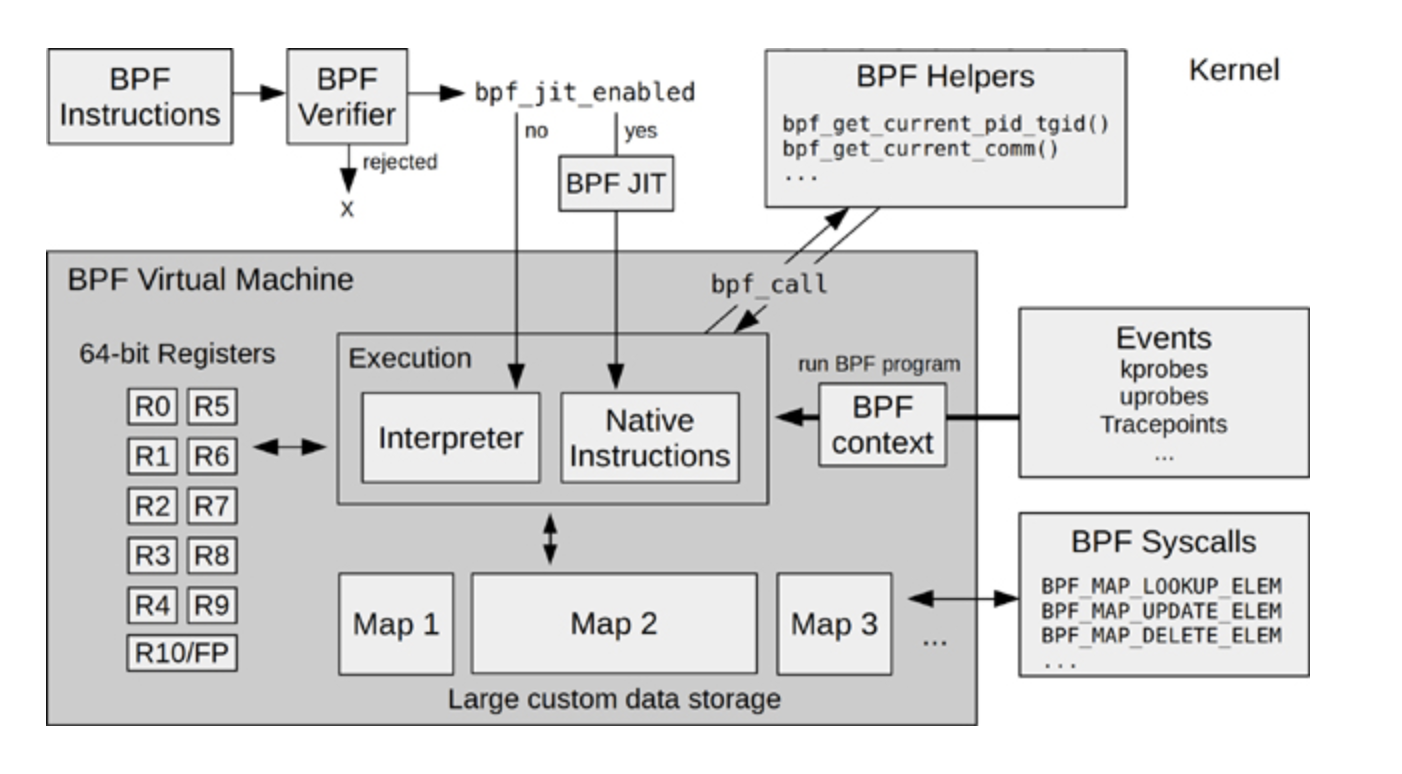
在 Brendan Gregg 写的书《BPF Performance Tools》里有一张 eBPF 的架构图,这张图对 eBPF 内核部分的模块和工作流的描述还是挺完整的,我也推荐你阅读这本书。图书的网上预览部分也可以看到这张图,我把它放在这里,你可以先看一下。
这里我想提醒你,我们在后面介绍例子程序的时候,你可以回头再来看看这张图,那时你会更深刻地理解这张图里的模块。
当 BPF 增强为 eBPF 之后, 它的应用范围自然也变广了。从单纯的网络包抓取,扩展到了下面的几个领域:
网络领域,内核态网络包的快速处理和转发,你可以看一下XDP(eXpress Data Path)。
安全领域,通过LSM(Linux Security Module)的 hook 点,eBPF 可以对 Linux 内核做安全监控和访问控制,你可以参考KRSI(Kernel Runtime Security Instrumentation)的文档。
内核追踪 / 调试,eBPF 能通过 tracepoints、kprobes、 perf-events 等 hook 点来追踪和调试内核,这也是我们在调试生产环境中,解决容器相关问题时使用的方法。
eBPF 的编程模型
前面说了很多 eBPF 概念方面的内容,如果你是刚接触 eBPF,也许还不能完全理解。所以接下来,我们看一下 eBPF 编程模型,然后通过一个编程例子,再帮助你理解 eBPF。
eBPF 程序其实也是遵循了一个固定的模式,Daniel Thompson 的“Kernel analysis using eBPF”里的一张图解读得非常好,它很清楚地说明了 eBPF 的程序怎么编译、加载和运行的。
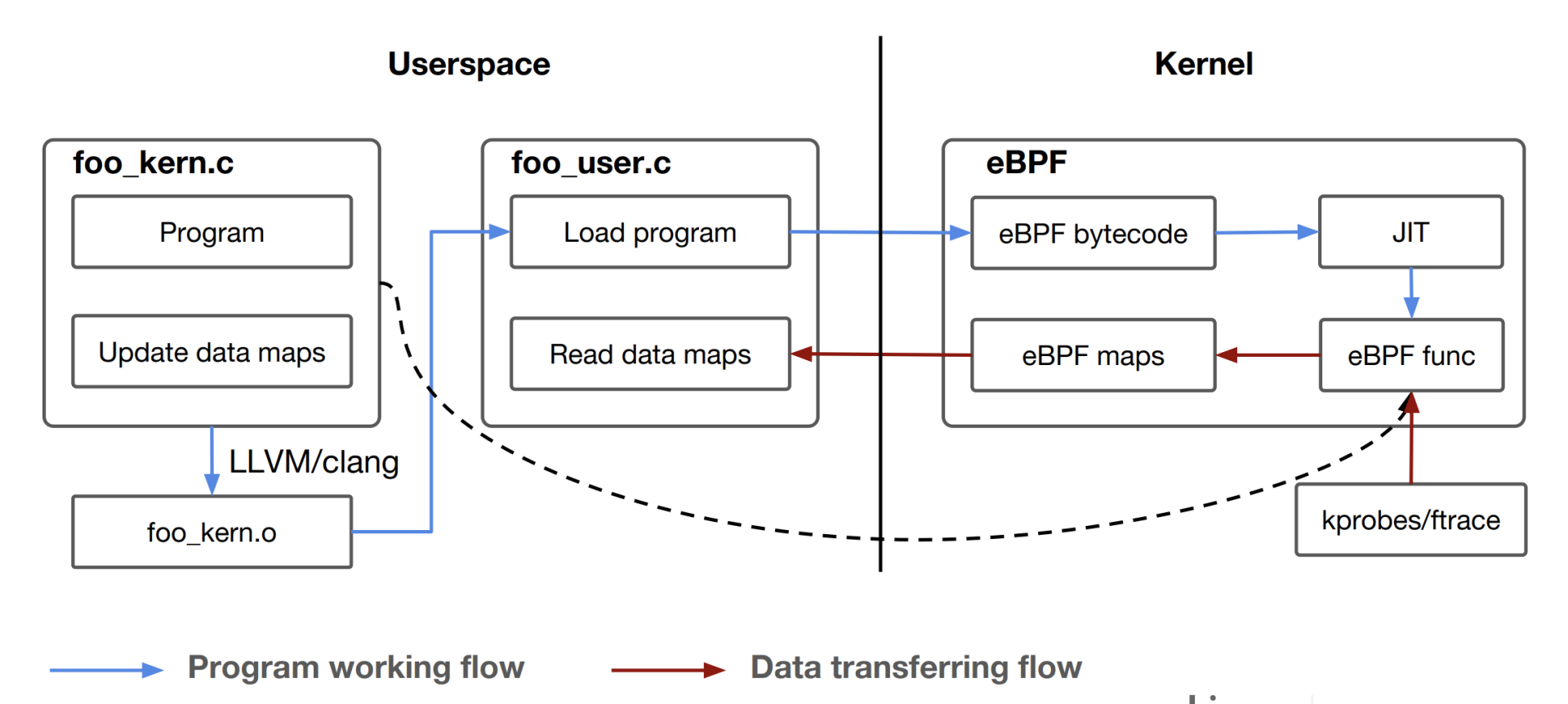
结合这张图,我们一起分析一下 eBPF 的运行原理。
一个 eBPF 的程序分为两部分,第一部分是内核态的代码,也就是图中的 foo_kern.c,这部分的代码之后会在内核 eBPF 的虚拟机中执行。第二部分是用户态的代码,对应图中的 foo_user.c。它的主要功能是负责加载内核态的代码,以及在内核态代码运行后通过 eBPF maps 从内核中读取数据。
然后我们看看 eBPF 内核态程序的编译,因为内核部分的代码需要被编译成 eBPF bytecode 二进制文件,也就是 eBPF 的虚拟机指令,而在 Linux 里,最常用的 GCC 编译器不支持生成 eBPF bytecode,所以这里必须要用 Clang/LLVM 来编译,编译后的文件就是 foo_kern.o。
foo_user.c 编译链接后就会生成一个普通的用户态程序,它会通过 bpf() 系统调用做两件事:第一是去加载 eBPF bytecode 文件 foo_kern.o,使 foo_kern.o 这个 eBPF bytecode 在内核 eBPF 的虚拟机中运行;第二是创建 eBPF maps,用于内核态与用户态的通讯。
接下来,在内核态,eBPF bytecode 会被加载到 eBPF 内核虚拟机中,这里你可以参考一下前面的 eBPF 架构图。
执行 BPF 程序之前,BPF Verifier 先要对 eBPF bytecode 进行很严格的指令检查。检查通过之后,再通过 JIT(Just In Time)编译成宿主机上的本地指令。
编译成本地指令之后,eBPF 程序就可以在内核中运行了,比如挂载到 tracepoints hook 点,或者用 kprobes 来对内核函数做分析,然后把得到的数据存储到 eBPF maps 中,这样 foo_user 这个用户态程序就可以读到数据了。
我们学习 eBPF 的编程的时候,可以从编译和执行 Linux 内核中 samples/bpf 目录下的例子开始。在这个目录下的例子里,包含了 eBPF 各种使用场景。每个例子都有两个.c 文件,命名规则都是 xxx_kern.c 和 xxx_user.c ,编译和运行的方式就和我们刚才讲的一样。
本来我想拿 samples/bpf 目录下的一个例子来具体说明的,不过后来我在 github 上看到了一个更好的例子,它就是ebpf-kill-example。下面,我就用这个例子来给你讲一讲,如何编写 eBPF 程序,以及 eBPF 代码需要怎么编译与运行。
我们先用 git clone 取一下代码:
1 | # git clone https://github.com/niclashedam/ebpf-kill-example |
这里你可以先看一下 Makefile,请注意编译 eBPF 程序需要 Clang/LLVM,以及由 Linux 内核源代码里的 tools/lib/bpf 中生成的 libbpf.so 库和相关的头文件。如果你的 OS 是 Ubuntu,可以运行make deps;make kernel-src这个命令,准备好编译的环境。
1 | # cat Makefile |
完成上面的步骤后,在 src/ 目录下,我们可以看到两个文件,分别是 bpf_program.c 和 loader.c。
在这个例子里,bpf_program.c 对应前面说的 foo_kern.c 文件,也就是说 eBPF 内核态的代码在 bpf_program.c 里面。而 loader.c 就是 eBPF 用户态的代码,它主要负责把 eBPF bytecode 加载到内核中,并且通过 eBPF Maps 读取内核中返回的数据。
1 | # ls src/ |
我们先看一下 bpf_program.c 中的内容:
1 | # cat src/bpf_program.c |
在这一小段代码中包含了 eBPF 代码最重要的三个要素,分别是:
BPF Program Types
BPF Maps
BPF Helpers
“BPF Program Types”定义了函数在 eBPF 内核态的类型,这个类型决定了这个函数会在内核中的哪个 hook 点执行,同时也决定了函数的输入参数的类型。在内核代码bpf_prog_type的枚举定义里,你可以看到 eBPF 支持的所有“BPF Program Types”。
比如在这个例子里的函数 bpf_prog(),通过 SEC() 这个宏,我们可以知道它的类型是 BPF_PROG_TYPE_TRACEPOINT,并且它注册在 syscalls subsystem 下的 sys_enter_kill 这个 tracepoint 上。
既然我们知道了具体的 tracepoint,那么这个 tracepoint 的注册函数的输入参数也就固定了。在这里,我们就把参数组织到 syscalls_enter_kill_args{}这个结构里,里面最主要的信息就是 kill() 系统调用中,输入信号的编号 sig 和信号发送目标进程的 pid。
“BPF Maps”定义了 key/value 对的一个存储结构,它用于 eBPF 内核态程序之间,或者内核态程序与用户态程序之间的数据通讯。eBPF 中定义了不同类型的 Maps,在内核代码bpf_map_type的枚举定义中,你可以看到完整的定义。
在这个例子里,定义的 kill_map 是 BPF_MAP_TYPE_HASH 类型,这里也用到了 SEC() 这个宏,等会儿我们再解释,先看其他的。
kill_map 是 HASH Maps 里的一个 key,它是一个 long 数据类型,value 是一个 char 字节。bpf_prog() 函数在系统调用 kill() 的 tracepoint 上运行,可以得到目标进程的 pid 参数,Maps 里的 key 值就是这个 pid 参数来赋值的,而 val 只是简单赋值为 1。
然后,这段程序调用了一个函数 bpf_map_update_elem(),把这组新的 key/value 对写入了到 kill_map 中。这个函数 bpf_map_update_elem() 就是我们要说的第三个要素 BPF Helpers。
我们再看一下“BPF Helpers”,它定义了一组可以在 eBPF 内核态程序中调用的函数。
尽管 eBPF 程序在内核态运行,但是跟 kernel module 不一样,eBPF 程序不能调用普通内核 export 出来的函数,而是只能调用在内核中为 eBPF 事先定义好的一些接口函数。这些接口函数叫作 BPF Helpers,具体有哪些你可以在”Linux manual page”中查看。
看明白这段代码之后,我们就可以运行 make build 命令,把 C 代码编译成 eBPF bytecode 了。这里生成了 src/bpf_program.o 这个文件:
1 | # make build |
接下来,你可以用 LLVM 工具来看一下 eBPF bytecode 里的内容,这样做可以确认下面两点。
编译生成了 BPF 虚拟机的汇编指令,而不是 x86 的指令。
在代码中用 SEC 宏添加的“BPF Program Types”和“BPF Maps”信息也在后面的 section 里。
查看 eBPF bytecode 信息的操作如下:
1 | ### 用objdump来查看bpf_program.o里的汇编指令 |
好了,看完了 eBPF 程序的内核态部分,我们再来看看它的用户态部分 loader.c:
1 | # cat src/loader.c |
这部分的代码其实也很简单,主要就是做了两件事:
通过执行 load_bpf_file() 函数,加载内核态代码生成的 eBPF bytecode,也就是编译后得到的文件“src/bpf_program.o”。
等待 30 秒钟后,从 BPF Maps 读取 key/value 对里的值。这里的值就是前面内核态的函数 bpf_prog(),在 kill() 系统调用的 tracepoint 上执行这个函数以后,写入到 BPF Maps 里的值。
至于读取 BPF Maps 的部分,就不需要太多的解释了,这里我们主要看一下 load_bpf_file() 这个函数,load_bpf_file() 是 Linux 内核代码 samples/bpf/bpf_load.c 里封装的一个函数。
这个函数可以读取 eBPF bytecode 中的信息,然后决定如何在内核中加载 BPF Program,以及创建 BPF Maps。这里用到的都是bpf()这个系统调用,具体的代码你可以去看一下内核中bpf_load.c和bpf.c这两个文件。
理解了用户态的 load.c 这段代码后,我们最后编译一下,就生成了用户态的程序 ebpf-kill-example:
1 | # make |
你可以运行一下这个程序,如果在 30 秒以内有别的程序执行了 kill -9 ,那么在内核中的 eBPF 代码就可以截获这个操作,然后通过 eBPF Maps 把信息传递给用户态进程,并且把这个信息打印出来了。
1 | # LD_LIBRARY_PATH=lib64/:$LD_LIBRARY_PATH ./src/ebpf-kill-example & |
重点小结
今天我们一起学习了 eBPF,接下来我给你总结一下重点。
eBPF 对早年的 BPF 技术做了增强之后,为 Linux 网络, Linux 安全以及 Linux 内核的调试和跟踪这三个领域提供了强大的扩展接口。
虽然整个 eBPF 技术是很复杂的,不过对于用户编写 eBPF 的程序,还是有一个固定的模式。
eBPF 的程序都分为两部分,一是内核态的代码最后会被编译成 eBPF bytecode,二是用户态代码,它主要是负责加载 eBPF bytecode,并且通过 eBPF Maps 与内核态代码通讯。
这里我们重点要掌握 eBPF 程序里的三个要素,eBPF Program Types,eBPF Maps 和 eBPF Helpers。
eBPF Program Types 可以定义函数在 eBPF 内核态的类型。eBPF Maps 定义了 key/value 对的存储结构,搭建了 eBPF Program 之间以及用户态和内核态之间的数据交换的桥梁。eBPF Helpers 是内核事先定义好了接口函数,方便 eBPF 程序调用这些函数。
理解了这些概念后,你可以开始动手编写 eBPF 的程序了。不过,eBPF 程序的调试并不方便,基本只能依靠 bpf_trace_printk(),同时也需要我们熟悉 eBPF 虚拟机的汇编指令。这些就需要你在实际的操作中,不断去积累经验了。
思考题
请你在ebpf-kill-example 这个例子的基础上,做一下修改,让用户态程序也能把调用 kill() 函数的进程所对应的进程号打印出来。
欢迎你在留言区记录你的思考或疑问。如果这一讲让你有所收获,也欢迎转发给你的朋友,同事,跟他一起学习进步。
加餐01 案例分析:怎么解决海量IPVS规则带来的网络延时抖动问题?
你好,我是程远。
今天,我们进入到了加餐专题部分。我在结束语的彩蛋里就和你说过,在这个加餐案例中,我们会用到 perf、ftrace、bcc/ebpf 这几个 Linux 调试工具,了解它们的原理,熟悉它们在调试问题的不同阶段所发挥的作用。
加餐内容我是这样安排的,专题的第 1 讲我先完整交代这个案例的背景,带你回顾我们当时整个的调试过程和思路,然后用 5 讲内容,对这个案例中用到的调试工具依次进行详细讲解。
好了,话不多说。这一讲,我们先来整体看一下这个容器网络延时的案例。
问题的背景
在 2020 年初的时候,我们的一个用户把他们的应用从虚拟机迁移到了 Kubernetes 平台上。迁移之后,用户发现他们的应用在容器中的出错率很高,相比在之前虚拟机上的出错率要高出一个数量级。
那为什么会有这么大的差别呢?我们首先分析了应用程序的出错日志,发现在 Kubernetes 平台上,几乎所有的出错都是因为网络超时导致的。
经过网络环境排查和比对测试,我们排除了网络设备上的问题,那么这个超时就只能是容器和宿主机上的问题了。
这里要先和你说明的是,尽管应用程序的出错率在容器中比在虚拟机里高出一个数量级,不过这个出错比例仍然是非常低的,在虚拟机中的出错率是 0.001%,而在容器中的出错率是 0.01%~0.04%。
因为这个出错率还是很低,所以对于这种低概率事件,我们想复现和排查问题,难度就很大了。
当时我们查看了一些日常的节点监控数据,比如 CPU 使用率、Load Average、内存使用、网络流量和丢包数量、磁盘 I/O,发现从这些数据中都看不到任何的异常。
既然常规手段无效,那我们应该如何下手去调试这个问题呢?
你可能会想到用 tcpdump 看一看,因为它是网络抓包最常见的工具。其实我们当时也这样想过,不过马上就被自己否定了,因为这个方法存在下面三个问题。
第一,我们遇到的延时问题是偶尔延时,所以需要长时间地抓取数据,这样抓取的数据量就会很大。
第二,在抓完数据之后,需要单独设计一套分析程序来找到长延时的数据包。
第三,即使我们找到了长延时的数据包,也只是从实际的数据包层面证实了问题。但是这样做无法取得新进展,也无法帮助我们发现案例中网络超时的根本原因。
调试过程
对于这种非常偶然的延时问题,之前我们能做的是依靠经验,去查看一些可疑点碰碰“运气”。
不过这一次,我们想用更加系统的方法来调试这个问题。所以接下来,我会从 ebpf 破冰,perf 进一步定位以及用 ftrace 最终锁定这三个步骤,带你一步步去解决这个复杂的网络延时问题。
ebpf 的破冰
我们的想法是这样的:因为延时产生在节点上,所以可以推测,这个延时有很大的概率发生在 Linux 内核处理数据包的过程中。
沿着这个思路,还需要进一步探索。我们想到,可以给每个数据包在内核协议栈关键的函数上都打上时间戳,然后计算数据包在每两个函数之间的时间差,如果这个时间差比较大,就可以说明问题出在这两个内核函数之间。
要想找到内核协议栈中的关键函数,还是比较容易的。比如下面的这张示意图里,就列出了 Linux 内核在接收数据包和发送数据包过程中的主要函数:

找到这些主要函数之后,下一个问题就是,想给每个数据包在经过这些函数的时候打上时间戳做记录,应该用什么方法呢?接下来我们一起来看看。
在不修改内核源代码的情况,要截获内核函数,我们可以利用kprobe或者tracepoint的接口。
使用这两种接口的方法也有两种:一是直接写 kernel module 来调用 kprobe 或者 tracepoint 的接口,第二种方法是通过ebpf的接口来调用它们。在后面的课程里,我还会详细讲解 ebpf、kprobe、tracepoint,这里你先有个印象就行。
在这里,我们选择了第二种方法,也就是使用 ebpf 来调用 kprobe 或者 tracepoint 接口,记录数据包处理过程中这些协议栈函数的每一次调用。
选择 ebpf 的原因主要是两个:一是 ebpf 的程序在内核中加载会做很严格的检查,这样在生产环境中使用比较安全;二是 ebpf map 功能可以方便地进行内核态与用户态的通讯,这样实现一个工具也比较容易。
决定了方法之后,这里我们需要先实现一个 ebpf 工具,然后用这个工具来对内核网络函数做 trace。
我们工具的具体实现是这样的,针对用户的一个 TCP/IP 数据流,记录这个流的数据发送包与数据接收包的传输过程,也就是数据发送包从容器的 Network Namespace 发出,一直到它到达宿主机的 eth0 的全过程,以及数据接收包从宿主机的 eth0 返回到容器 Network Namespace 的 eth0 的全程。
在收集了数十万条记录后,我们对数据做了分析,找出前后两步时间差大于 50 毫秒(ms)的记录。最后,我们终于发现了下面这段记录:
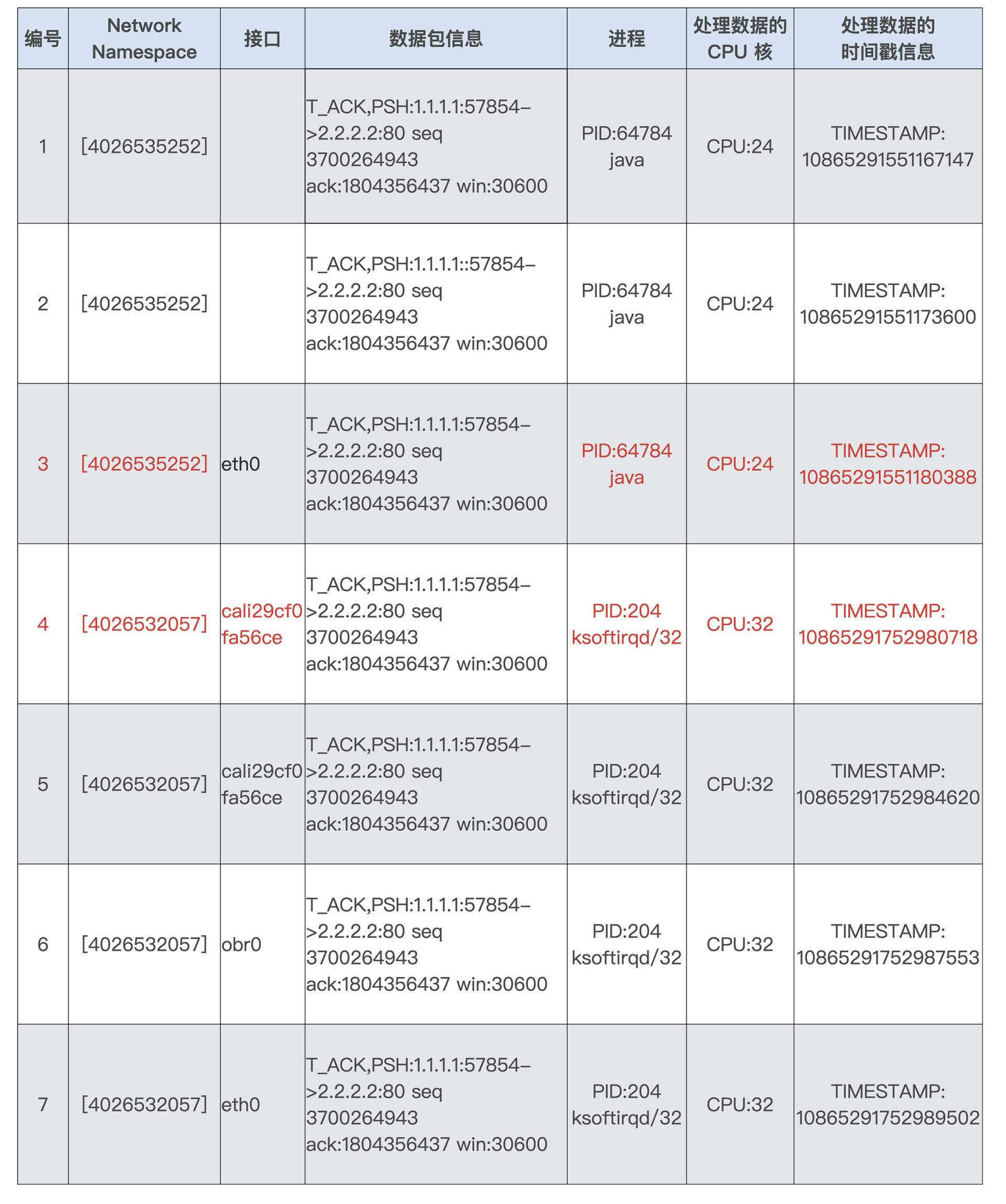
在这段记录中,我们先看一下“Network Namespace”这一列。编号 3 对应的 Namespace ID 4026535252 是容器里的,而 ID4026532057 是宿主机上的 Host Namespace。
数据包从 1 到 7 的数据表示了,一个数据包从容器里的 eth0 通过 veth 发到宿主机上的 peer veth cali29cf0fa56ce,然后再通过路由从宿主机的 obr0(openvswitch)接口和 eth0 接口发出。
为了方便你理解,我在下面画了一张示意图,描述了这个数据包的传输过程:
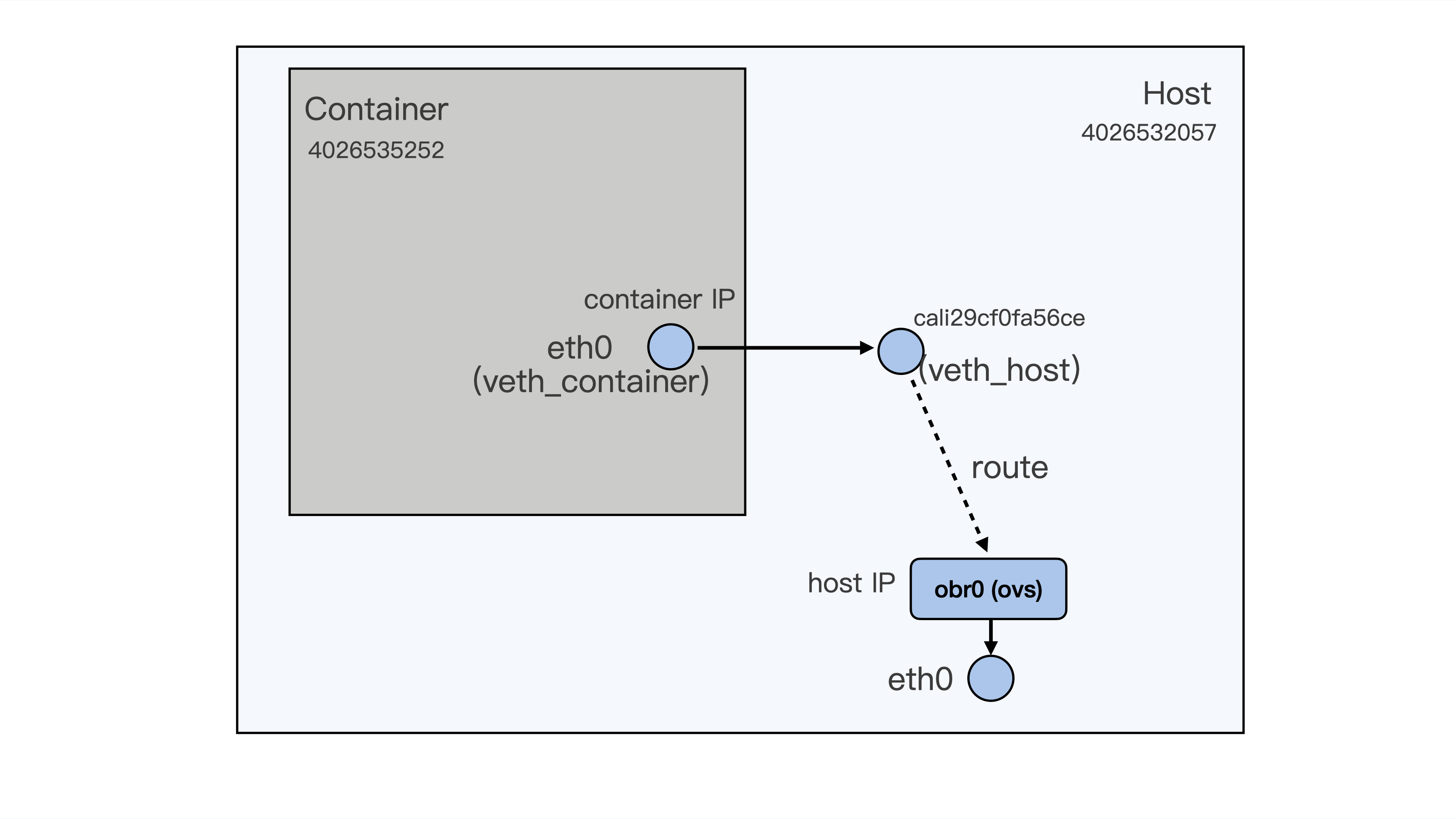
在这个过程里,我们发现了当数据包从容器的 eth0 发送到宿主机上的 cali29cf0fa56ce,也就是从第 3 步到第 4 步之间,花费的时间是 10865291752980718-10865291551180388=201800330。
因为时间戳的单位是纳秒 ns,而 201800330 超过了 200 毫秒(ms),这个时间显然是不正常的。
你还记得吗?我们在容器网络模块的第 17 讲说过 veth pair 之间数据的发送,它会触发一个 softirq,并且在我们 ebpf 的记录中也可以看到,当数据包到达 cali29cf0fa56ce 后,就是 softirqd 进程在 CPU32 上对它做处理。
那么这时候,我们就可以把关注点放到 CPU32 的 softirq 处理上了。我们再仔细看看 CPU32 上的 si(softirq)的 CPU 使用情况(运行 top 命令之后再按一下数字键 1,就可以列出每个 CPU 的使用率了),会发现在 CPU32 上时不时出现 si CPU 使用率超过 20% 的现象。
具体的输出情况如下:
1 | %Cpu32 : 8.7 us, 0.0 sy, 0.0 ni, 62.1 id, 0.0 wa, 0.0 hi, 29.1 si, 0.0 st |
其实刚才说的这点,在最初的节点监控数据上,我们是不容易注意到的。这是因为我们的节点上有 80 个 CPU,单个 CPUsi 偶尔超过 20%,平均到 80 个 CPU 上就只有 0.25% 了。要知道,对于一个普通节点,1% 的 si 使用率都是很正常的。
好了,到这里我们已经缩小了问题的排查范围。可以看到,使用了 ebpf 帮助我们在毫无头绪的情况,找到了一个比较明确的方向。那么下一步,我们自然要顺藤摸瓜,进一步去搞清楚,为什么在 CPU32 上的 softirq CPU 使用率会时不时突然增高?
perf 定位热点
对于查找高 CPU 使用率情况下的热点函数,perf 显然是最有力的工具。我们只需要执行一下后面的这条命令,看一下 CPU32 上的函数调用的热度。
1 | # perf record -C 32 -g -- sleep 10 |
为了方便查看,我们可以把 perf record 输出的结果做成一个火焰图,具体的方法我在下一讲里介绍,这里你需要先理解定位热点的整体思路。
结合前面的数据分析,我们已经知道了问题出现在 softirq 的处理过程中,那么在查看火焰图的时候,就要特别关注在 softirq 中被调用到的函数。
从上面这张图里,我们可以看到,run_timer_softirq 所占的比例是比较大的,而在 run_timer_softirq 中的绝大部分比例又是被一个叫作 estimation_timer() 的函数所占用的。
运行完 perf 之后,我们离真相又近了一步。现在,我们知道了 CPU32 上 softirq 的繁忙是因为 TIMER softirq 引起的,而 TIMER softirq 里又在不断地调用 estimation_timer() 这个函数。
沿着这个思路继续分析,对于 TIMER softirq 的高占比,一般有这两种情况,一是 softirq 发生的频率很高,二是 softirq 中的函数执行的时间很长。
那怎么判断具体是哪种情况呢?我们用 /proc/softirqs 查看 CPU32 上 TIMER softirq 每秒钟的次数,就会发现 TIMER softirq 在 CPU32 上的频率其实并不高。
这样第一种情况就排除了,那我们下面就来看看,Timer softirq 中的那个函数 estimation_timer(),是不是它的执行时间太长了?
ftrace 锁定长延时函数
我们怎样才能得到 estimation_timer() 函数的执行时间呢?
你还记得,我们在容器 I/O 与内存那一讲里用过的ftrace么?当时我们把 ftrace 的 tracer 设置为 function_graph,通过这个办法查看内核函数的调用时间。在这里我们也可以用同样的方法,查看 estimation_timer() 的调用时间。
这时候,我们会发现在 CPU32 上的 estimation_timer() 这个函数每次被调用的时间都特别长,比如下面图里的记录,可以看到 CPU32 上的时间高达 310 毫秒!

现在,我们可以确定问题就出在 estimation_timer() 这个函数里了。
接下来,我们需要读一下 estimation_timer() 在内核中的源代码,看看这个函数到底是干什么的,它为什么耗费了这么长的时间。其实定位到这一步,后面的工作就比较容易了。
estimation_timer() 是IPVS模块中每隔 2 秒钟就要调用的一个函数,它主要用来更新节点上每一条 IPVS 规则的状态。Kubernetes Cluster 里每建一个 service,在所有的节点上都会为这个 service 建立相应的 IPVS 规则。
通过下面这条命令,我们可以看到节点上 IPVS 规则的数目:
1 | # ipvsadm -L -n | wc -l |
我们的节点上已经建立了将近 80K 条 IPVS 规则,而 estimation_timer() 每次都需要遍历所有的规则来更新状态,这样就导致 estimation_timer() 函数时间开销需要上百毫秒。
我们还有最后一个问题,estimation_timer() 是 TIMER softirq 里执行的函数,那它为什么会影响到网络 RX softirq 的延时呢?
这个问题,我们只要看一下 softirq 的处理函数__do_softirq(),就会明白了。因为在同一个 CPU 上,__do_softirq() 会串行执行每一种类型的 softirq,所以 TIMER softirq 执行的时间长了,自然会影响到下一个 RX softirq 的执行。
好了,分析这里,这个网络延时问题产生的原因我们已经完全弄清楚了。接下来,我带你系统梳理一下这个问题的解决思路。
问题小结
首先回顾一下今天这一讲的问题,我们分析了一个在容器平台的生产环境中,用户的应用程序网络延时的问题。这个延时只是偶尔发生,并且出错率只有 0.01%~0.04%,所以我们从常规的监控数据中无法看到任何异常。
那调试这个问题该如何下手呢?
我们想到的方法是使用 ebpf 调用 kprobe/tracepoint 的接口,这样就可以追踪数据包在内核协议栈主要函数中花费的时间。
我们实现了一个 ebpf 工具,并且用它缩小了排查范围,我们发现当数据包从容器的 veth 接口发送到宿主机上的 veth 接口,在某个 CPU 上的 softirq 的处理会有很长的延时。并且由此发现了,在对应的 CPU 上 si 的 CPU 使用率时不时会超过 20%。
找到了这个突破口之后,我们用 perf 工具专门查找了这个 CPU 上的热点函数,发现 TIMER softirq 中调用 estimation_timer() 的占比是比较高的。
接下来,我们使用 ftrace 进一步确认了,在这个特定 CPU 上 estimation_timer() 所花费的时间需要几百毫秒。
通过这些步骤,我们最终锁定了问题出在 IPVS 的这个 estimation_timer() 函数里,也找到了问题的根本原因:在我们的节点上存在大量的 IPVS 规则,每次遍历这些规则都会消耗很多时间,最终导致了网络超时现象。
知道了原因之后,因为我们在生产环境中并不需要读取 IPVS 规则状态,所以为了快速解决生产环境上的问题,我们可以使用内核livepatch的机制在线地把 estimation_timer() 函数替换成了一个空函数。
这样,我们就暂时规避了因为 estimation_timer() 耗时长而影响其他 softirq 的问题。至于长期的解决方案,我们可以把 IPVS 规则的状态统计从 TIMER softirq 中转移到 kernel thread 中处理。
思考题
如果不使用 ebpf 工具,你还有什么方法来找到这个问题的突破口呢?
欢迎你在留言区和我交流讨论。如果这一讲的内容对你有帮助的话,也欢迎转发给你的朋友、同事,和他一起学习进步。
加餐03 理解ftrace(1):怎么应用ftrace查看长延时内核函数?
你好,我是程远。
上一讲里,我们一起学习了 perf 这个工具。在我们的案例里,使用 perf 找到了热点函数之后,我们又使用了 ftrace 这个工具,最终锁定了长延时的函数 estimation_timer()。
那么这一讲,我们就来学习一下 ftrace 这个工具,主要分为两个部分来学习。
第一部分讲解 ftrace 的最基本的使用方法,里面也会提到在我们的案例中是如何使用的。第二部分我们一起看看 Linux ftrace 是如何实现的,这样可以帮助你更好地理解 Linux 的 ftrace 工具。
ftrace 的基本使用方法
ftrace 这个工具在 2008 年的时候就被合入了 Linux 内核,当时的版本还是 Linux2.6.x。从 ftrace 的名字 function tracer,其实我们就可以看出,它最初就是用来 trace 内核中的函数的。
当然了,现在 ftrace 的功能要更加丰富了。不过,function tracer 作为 ftrace 最基本的功能,也是我们平常调试 Linux 内核问题时最常用到的功能。那我们就先来看看这个最基本,同时也是最重要的 function tracer 的功能。
ftrace 的操作都可以在 tracefs 这个虚拟文件系统中完成,对于 CentOS,这个 tracefs 的挂载点在 /sys/kernel/debug/tracing 下:
1 | # cat /proc/mounts | grep tracefs |
你可以进入到 /sys/kernel/debug/tracing 目录下,看一下这个目录下的文件:
1 | # cd /sys/kernel/debug/tracing |
tracefs 虚拟文件系统下的文件操作,其实和我们常用的 Linux proc 和 sys 虚拟文件系统的操作是差不多的。通过对某个文件的 echo 操作,我们可以向内核的 ftrace 系统发送命令,然后 cat 某个文件得到 ftrace 的返回结果。
对于 ftrace,它的输出结果都可以通过 cat trace 这个命令得到。在缺省的状态下 ftrace 的 tracer 是 nop,也就是 ftrace 什么都不做。因此,我们从cat trace中也看不到别的,只是显示了 trace 输出格式。
1 | # pwd |
下面,我们可以执行 echo function > current_tracer 来告诉 ftrace,我要启用 function tracer。
1 | # cat current_tracer |
在启动了 function tracer 之后,我们再查看一下 trace 的输出。这时候我们就会看到大量的输出,每一行的输出就是当前内核中被调用到的内核函数,具体的格式你可以参考 trace 头部的说明。
1 | # cat trace | more |
看到这个 trace 输出,你肯定会觉得输出的函数太多了,查看起来太困难了。别担心,下面我给你说个技巧,来解决输出函数太多的问题。
其实在实际使用的时候,我们可以利用 ftrace 里的 filter 参数做筛选,比如我们可以通过 set_ftrace_filter 只列出想看到的内核函数,或者通过 set_ftrace_pid 只列出想看到的进程。
为了让你加深理解,我给你举个例子,比如说,如果我们只是想看 do_mount 这个内核函数有没有被调用到,那我们就可以这么操作:
1 | # echo nop > current_tracer |
在执行了 mount 命令之后,我们查看一下 trace。
这时候,我们就只会看到一条 do_mount() 函数调用的记录,我们一起来看看,输出结果里的几个关键参数都是什么意思。
输出里”do_mount <- ksys_mount”表示 do_mount() 函数是被 ksys_mount() 这个函数调用到的,”2159455.499195”表示函数执行时的时间戳,而”[005]“是内核函数 do_mount() 被执行时所在的 CPU 编号,还有”mount-20889”,它是 do_mount() 被执行时当前进程的 pid 和进程名。
1 | # mount -t tmpfs tmpfs /tmp/fs |
这里我们只能判断出,ksys mount() 调用了 do mount() 这个函数,这只是一层调用关系,如果我们想要看更加完整的函数调用栈,可以打开 ftrace 中的 func_stack_trace 选项:
1 | # echo 1 > options/func_stack_trace |
打开以后,我们再来做一次 mount 操作,就可以更清楚地看到 do_mount() 是系统调用 (syscall) 之后被调用到的。
1 | # umount /tmp/fs |
结合刚才说的内容,我们知道了,通过 function tracer 可以帮我们判断内核中函数是否被调用到,以及函数被调用的整个路径 也就是调用栈。
这样我们就理清了整体的追踪思路:如果我们通过 perf 发现了一个内核函数的调用频率比较高,就可以通过 function tracer 工具继续深入,这样就能大概知道这个函数是在什么情况下被调用到的。
那如果我们还想知道,某个函数在内核中大致花费了多少时间,就像加餐第一讲案例中我们就拿到了 estimation_timer() 时间开销,又要怎么做呢?
这里需要用到 ftrace 中的另外一个 tracer,它就是 function_graph。我们可以在刚才的 ftrace 的设置基础上,把 current_tracer 设置为 function_graph,然后就能看到 do_mount() 这个函数调用的时间了。
1 | # echo function_graph > current_tracer |
通过 function_graph tracer,还可以让我们看到每个函数里所有子函数的调用以及时间,这对我们理解和分析内核行为都是很有帮助的。
比如说,我们想查看 kfree_skb() 这个函数是怎么执行的,就可以像下面这样配置:
1 | # echo '!do_mount ' >> set_ftrace_filter ### 先把之前的do_mount filter给去掉。 |
设置完成之后,我们再来看 trace 的输出。现在,我们就可以看到 kfree_skb() 下的所有子函数的调用,以及它们花费的时间了。
具体输出如下,你可以做个参考:
1 | # cat trace | more |
好了,对于 ftrace 的最基本的、也是最重要的内核函数相关的 tracer,我们已经知道怎样操作了。那你有没有好奇过,这个 ftrace 又是怎么实现的呢?下面我们就来看一下。
ftrace 的实现机制
下面这张图描述了 ftrace 实现的 high level 的架构,用户通过 tracefs 向内核中的 function tracer 发送命令,然后 function tracer 把收集到的数据写入一个 ring buffer,再通过 tracefs 输出给用户。
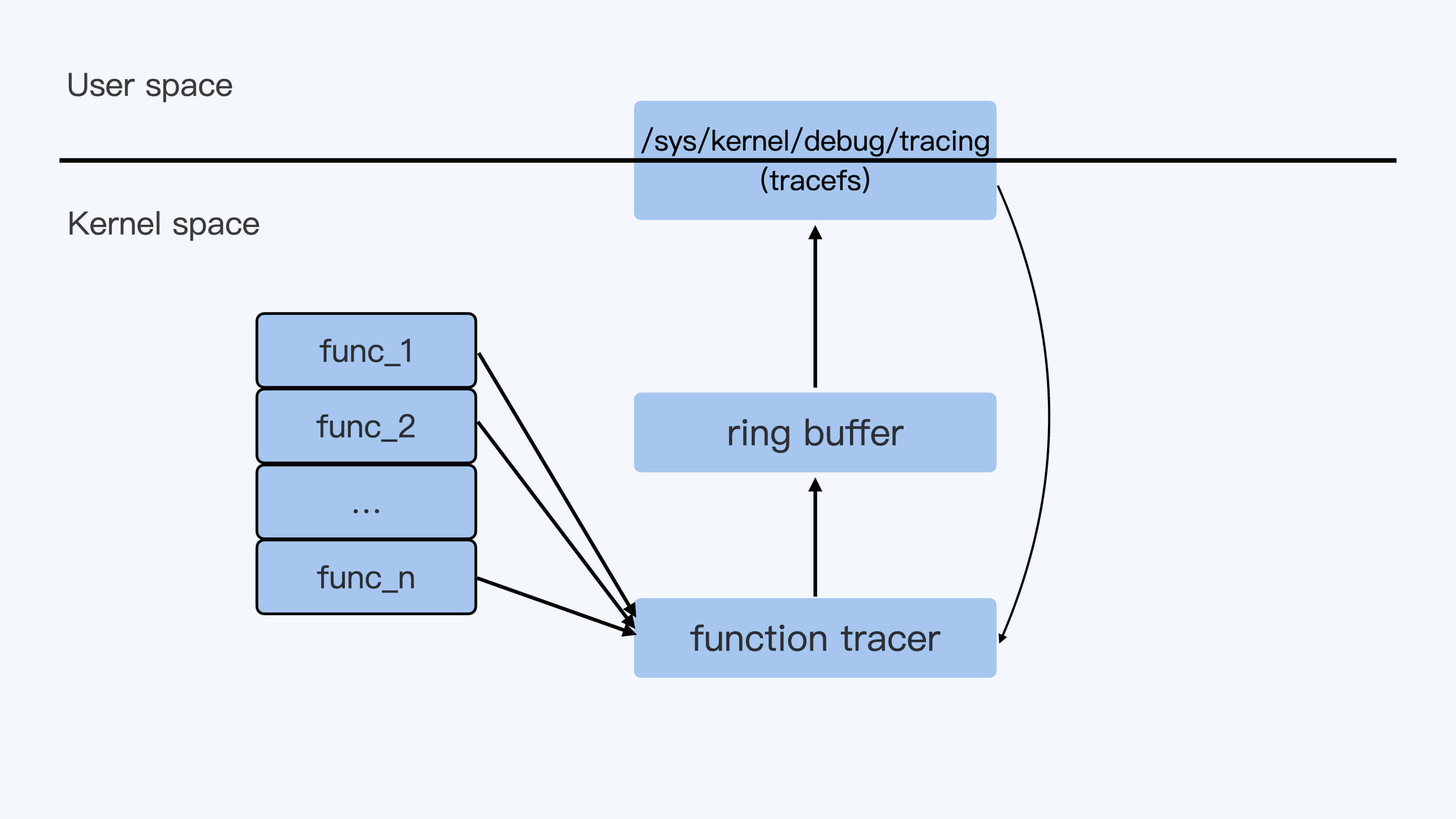
这里的整个过程看上去比较好理解。不过还是有一个问题,不知道你有没有思考过,
frace 可以收集到内核中任意一个函数被调用的情况,这点是怎么做到的?
你可能想到,这是因为在内核的每个函数中都加上了 hook 点了吗?这时我们来看一下内核的源代码,显然并没有这样的 hook 点。那 Linux 到底是怎么实现的呢?
其实这里 ftrace 是利用了 gcc 编译器的特性,再加上几步非常高明的代码段替换操作,就很完美地实现了对内核中所有函数追踪的接口(这里的“所有函数”不包括“inline 函数”)。下面我们一起看一下这个实现。
Linux 内核在编译的时候,缺省会使用三个 gcc 的参数”-pg -mfentry -mrecord-mcount”。
其中,”-pg -mfentry”这两个参数的作用是,给编译出来的每个函数开头都插入一条指令”callq “。
你如果编译过内核,那么你可以用”objdump -D vmlinux”来查看一下内核函数的汇编,比如 do_mount() 函数的开头几条汇编就是这样的:
1 | ffffffff81309550 <do_mount>: |
而”-mrecord-mcount”参数在最后的内核二进制文件 vmlinux 中附加了一个 mcount_loc 的段,这个段里记录了所有”callq “指令的地址。这样我们很容易就能找到每个函数的这个入口点。
为了方便你理解,我画了一张示意图,我们编译出来的 vmlinux 就像图里展示的这样:
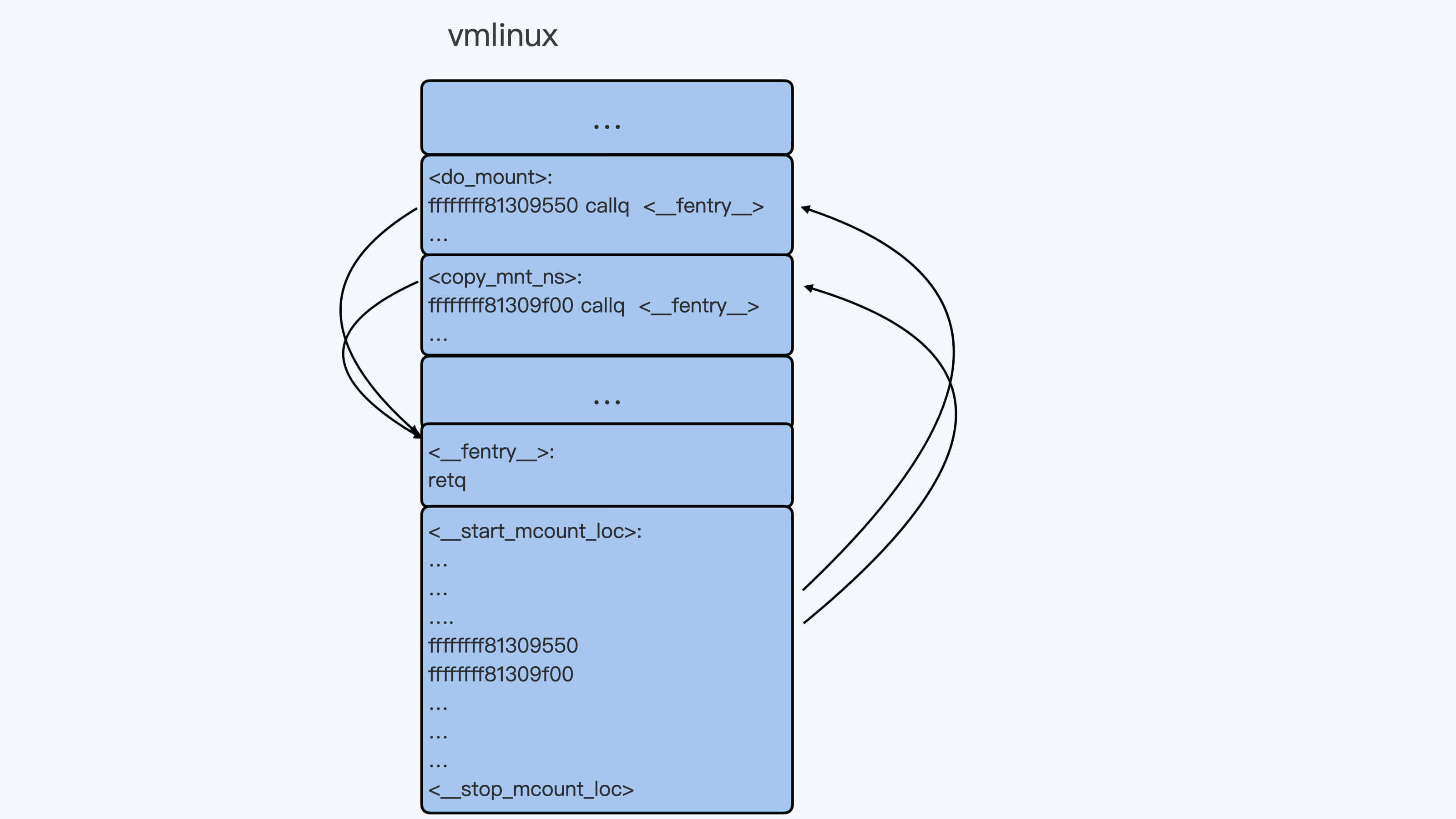
不过你需要注意的是,尽管通过编译的方式,我们可以给每个函数都加上一个额外的 hook 点,但是这个额外”fentry”函数调用的开销是很大的。
即使”fentry”函数中只是一个 retq 指令,也会使内核性能下降 13%,这对于 Linux 内核来说显然是不可以被接受的。那我们应该怎么办呢?
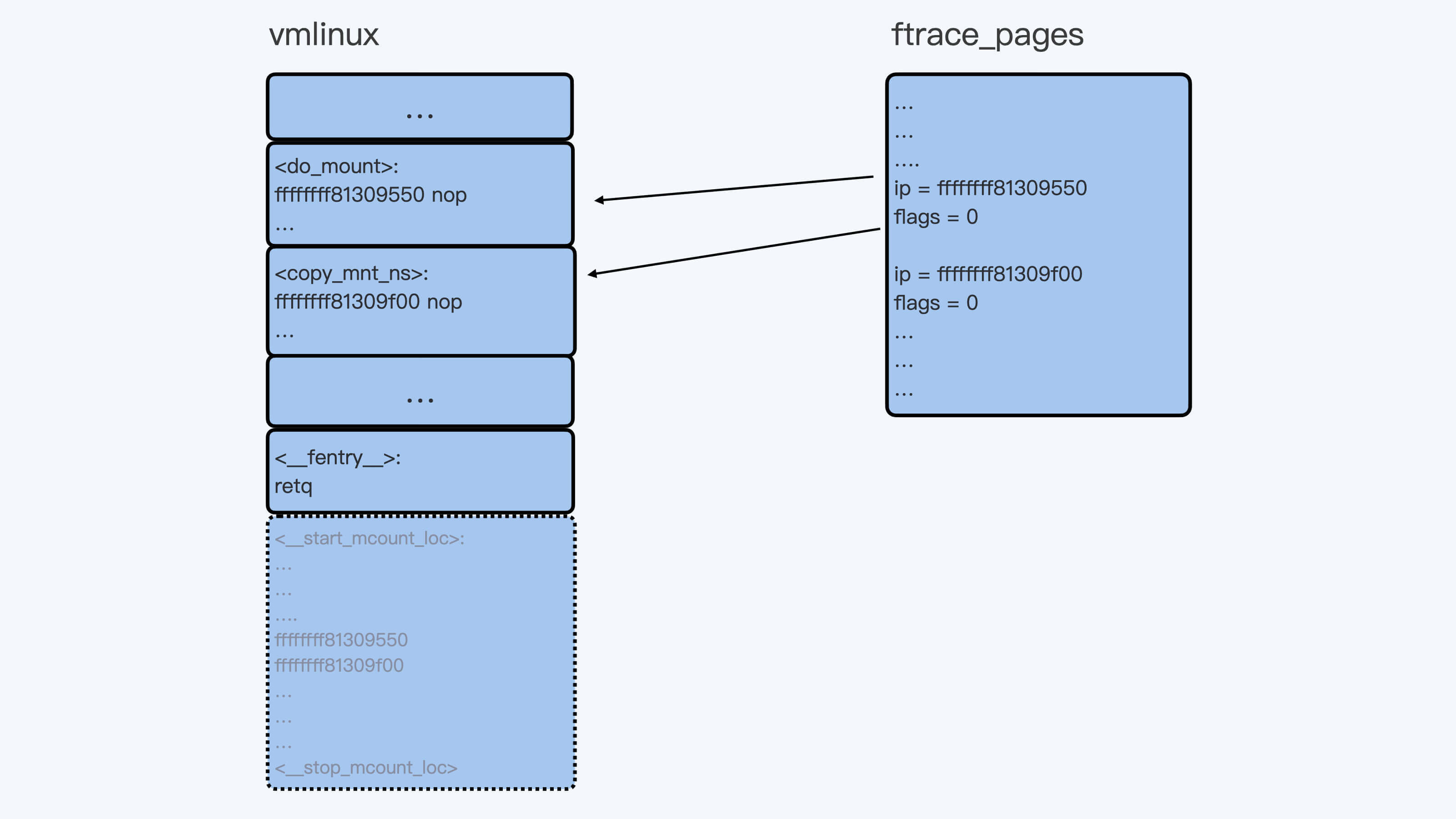
ftrace 在内核启动的时候做了一件事,就是把内核每个函数里的第一条指令”callq “(5 个字节),替换成了”nop”指令(0F 1F 44 00 00),也就是一条空指令,表示什么都不做。
虽然是空指令,不过在内核的代码段里,这相当于给每个函数预留了 5 个字节。这样在需要的时候,内核可以再把这 5 个字节替换成 callq 指令,call 的函数就可以指定成我们需要的函数了。
同时,内核的 mcount_loc 段里,虽然已经记录了每个函数”callq “的地址,不过对于 ftrace 来说,除了地址之外,它还需要一些额外的信息。
因此,在内核启动初始化的时候,ftrace 又申请了新的内存来存放 mcount_loc 段中原来的地址信息,外加对每个地址的控制信息,最后释放了原来的 mcount_loc 段。
所以 Linux 内核在机器上启动之后,在内存中的代码段和数据结构就会发生变化。你可以参考后面这张图,它描述了变化后的情况:
当我们需要用 function tracer 来 trace 某一个函数的时候,比如”echo do_mount > set_ftrace_filter”命令执行之后,do_mount() 函数的第一条指令就会被替换成调用 ftrace_caller 的指令。
你可以查看后面的示意图,结合这张图来理解刚才的内容。
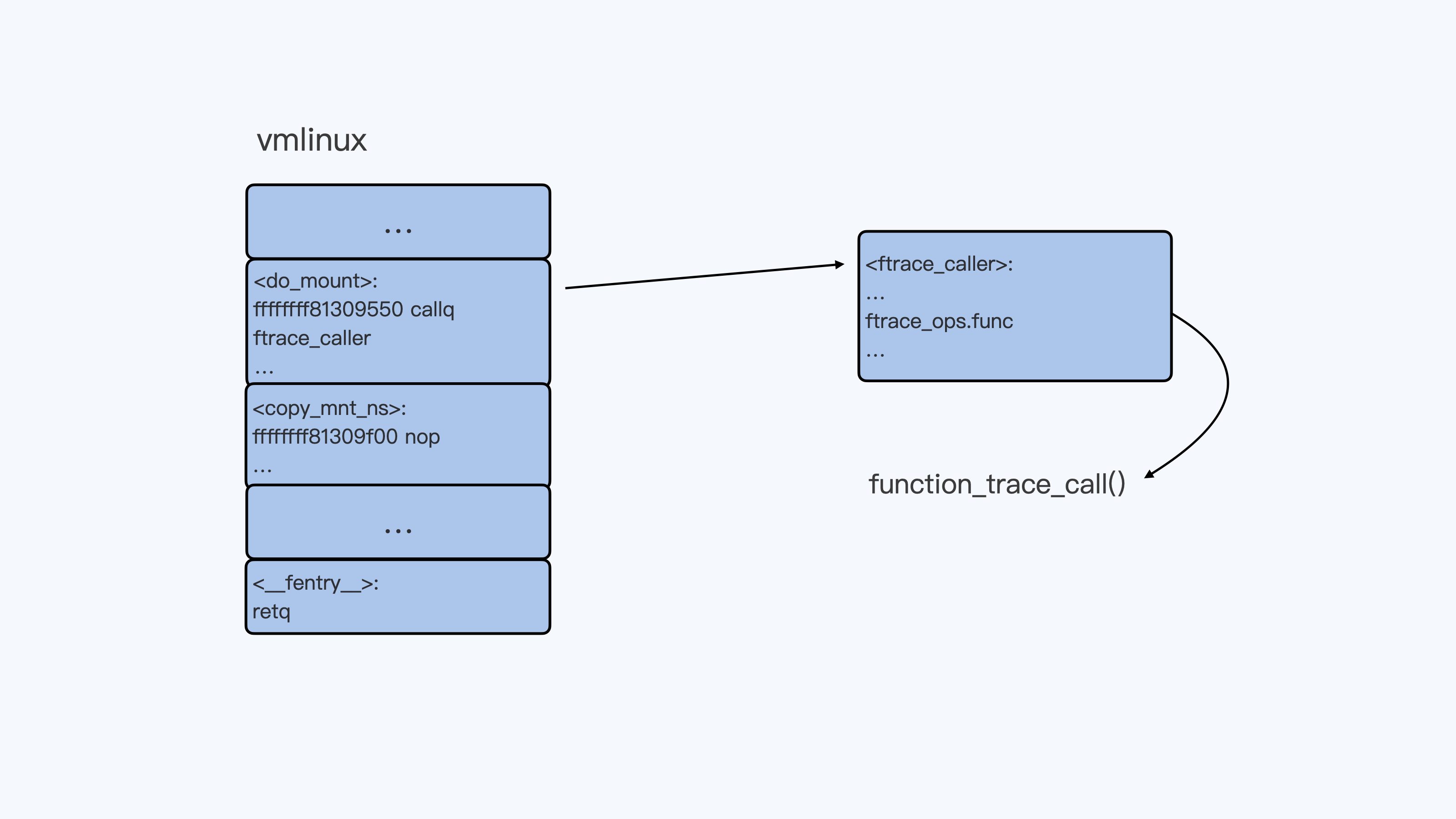
这样,每调用一次 do_mount() 函数,它都会调用 function_trace_call() 函数,把 ftrace function trace 信息放入 ring buffer 里,再通过 tracefs 输出给用户。
重点小结
这一讲我们主要讲解了 Linux ftrace 这个工具。
首先我们学习了 ftrace 最基本的操作,对内核函数做 trace。在这里最重要的有两个 tracers,分别是 function 和 function_graph。
function tracer 可以用来记录内核中被调用到的函数的情况。在实际使用的时候,我们可以设置一些 ftrace 的 filter 来查看某些我们关心的函数,或者我们关心的进程调用到的函数。
我们还可以设置 func_stack_trace 选项,来查看被 trace 函数的完整调用栈。
而 function_graph trracer 可以用来查看内核函数和它的子函数调用关系以及调用时间,这对我们理解内核的行为非常有帮助。
讲完了 ftrace 的基本操作之后,我们又深入研究了 ftrace 在 Linux 中的实现机制。
在 ftrace 实现过程里,最重要的一个环节是利用 gcc 编译器的特性,为每个内核函数二进制码中预留了 5 个字节,这样内核函数就可以调用调试需要的函数,从而实现了 ftrace 的功能。
思考题
我们讲 ftrace 实现机制时,说过内核中的“inline 函数”不能被 ftrace 到,你知道这是为什么吗?那么内核中的”static 函数”可以被 ftrace 追踪到吗?
欢迎你在留言区跟我分享你的思考与疑问,如果这一讲对你有启发,也欢迎转发给你的同事、朋友,跟他一起交流学习。
结束语 跳出舒适区,突破思考的惰性
你好,我是程远。
今天是我们专栏必学内容的最后一讲。当你读到这一讲内容的时候,刚好是元旦。首先我要祝你元旦快乐,2021 年一切顺利!
在过去的二十多讲内容里,我们从基础开始,一起学习了容器进程、内存、存储、网络以及安全这几部分的内容。在每一讲里,我们都会从一个实际问题或者现象出发,然后一步步去分析和解决问题。一路走来,真是百感交集,我有好多心里话,但又不知该从何说起。
所以最后一讲,我想和你聊聊我个人的一些成长感悟,在辞旧迎新的元旦,正适合回顾过去和展望未来。所以这既是专栏的一次总结交流,也是我们开启新征程的“号角”。
在多年以前,我在书里读到一句话,说的是“每个人都有潜在的能量,只是很容易被习惯所掩盖,被时间所迷离,被惰性所消磨。”
今天再次回看这段话,还真是一语中的,感触良多,回想起专栏写作的整个过程,这件事带给我的最大感悟就是:跳出自己的舒适区,才能有所突破。
突破舒适区是很难的事儿
我们都知道,突破舒适区是一件很难的事儿。这里我给你分享一个我自己的故事,也许你也会从这个故事里找到自己的影子。
记得在 2 年前,我参加过 eBay 的一个内部培训,培训的目标就是要让自己有所“突破”。我必须承认,这个培训是我经历过的所有培训中最接地气的一个培训,在培训过程里我也是情绪激昂的,准备带着学到的东西回到工作里去大展身手,好好突破一番的。
不过等培训结束,再回到日常工作的时候,之前的雄心壮志、激情澎湃又被日常的琐事所淹没,积蓄的那股劲儿又慢慢被消磨了。周围的同事会开玩笑地对我说:“程远啊,我觉得你没有突破啊。”
其实,我心里也知道,所谓的“突破”就要跳出自己的舒适区。不过我始终不知道怎么跳出来,哪怕自己手上的工作再多,工作到再晚,但这仍然是处于自己舒适区。这是因为这一切的工作节奏还有思考的问题,都是我自己熟悉的。
这种熟悉很可能让我们沉湎其中,裹足不前。那问题来了,意识到自己处于舒适区,产生想要“跳出去”的念头的确是良好开局,难的是怎么有效突破。这就要聊到突破方法路径的问题了,我想结合自己的感悟给你说一说。
主动迎接挑战,在实战中进步
不知道你有没有听过热力学里熵增的定律,大概说的是:封闭系统的熵(能量)会不可逆地增加,最终导致整个系统崩溃。那怎么才能保持这个系统的活力呢?就是能量交换,不断去引入外部的能量,也就是负熵。
我们可以引申一下,自然会想到走出舒适区这件事,也是同样的道理。我们要有一种冒险家的勇气,主动去迎接挑战,在实战里迫使自己不断进步。
其实选择做这样一个专栏,对我来说就是走出舒适区的一项“挑战”。在今年 7 月份,那还是我们这个专栏筹备的前期,我当时就一个想法,就是把我这些年来在容器方面的积累给记录下来。
从 7 月份决定写容器这个专栏开始,到现在差不多也有半年的时间了,我真的觉得,在工作的同时把写专栏的这件事给坚持下来,真的是一件不容易的事情。这里不仅仅是一个简单的时间投入问题,更多的是迫使自己再去思考的问题。
估计你也发现了,我每一讲都涉及不少知识点。我在专栏写作的过程中,花时间最多的就是怎么把问题说清楚,这里要解释哪些关键知识点,适合用什么样的例子做解释,每个知识点要讲到什么程度,需要查阅哪些代码和资料来保证自己所讲内容的正确性。
这样的思考模式和我日常思考工作问题的模式是完全不同的。但也正是借着这样的机会,我才从自己原先的舒适区里跳了出来,工作之余同时也在思考写专栏的问题,每天都有大量的 context switch,也就是上下文切换。
我很高兴自己可以坚持下来,完成了专栏的主体部分。可以说,这门课既是容器的实战课,也是我自己走出舒适区的实战训练。
突破舒适区,本质是突破思考的惰性
这次的专栏写作,还让我意识到,突破舒适区的本质就是突破思考的惰性。只有不断思考,才能推着自己不断往前走,才能让我们更从容地解决工作上的问题。
在 2020 年的 12 月初,Kubernetes 宣布不再支持 dockershim,也就是说 Kubernetes 节点上不能再直接用 Docker 来启动容器了。当时我看到这条新闻,觉得这是理所当然的,因为我们的容器云平台上在 2019 年初就从 Docker 迁移到了 Containerd。
不过,后来我在专栏留言回复的过程中,连续有三位同学留言,问我怎么看 Kubernetes 的这个决定,这让我又回忆起了当初我们团队是怎么做的迁移决定。
这件事还要追溯到 2018 年的时候,我们发现 kubelet 通过 CRI 接口就可以集成 Containerd 了,于是我们就开始思考,是不是应该用 Containerd 来替换 Docker 呢?
当时我们看到的好处有两点。第一点是这样替换之后架构上的优势,CRI 可以说是 kubelet 连接 Runtime 的标准了,而用 Dockershim 接 Docker 再转 Containerd,这样很累赘。第二点好处就是降低了维护成本。Containerd 只是 Docker 中的一部分,维护 Containerd 明显要比维护庞大的 Docker 容易。
当然,这么做的挑战也是很大的。当时,我们在生产环境中已经有 2 万台物理机节点以及几十万个容器,而且那时候业界还几乎没有人在生产环境中用 kubelet 直接调用 Containerd。没有前人的尝试可以借鉴,只能咬牙打一场硬仗。
后来我们通过一个多月的测试,发现直接使用 Containerd,无论是稳定性还是性能都没有问题。有了实际测试做保障,我们在 2019 年初又花了 3 个月时间,才把生产环境上的 Docker 全部替换成 Containerd。
这样的结果看似轻描淡写,一两句话就带过了。但实际过程里,已经不是过五关斩六将了,而是一直在发现问题、解决问题,大大小小的战役才汇聚成了最后的战果。其实,我在这个专栏里和你分享的一些容器问题,也来源于我们当时的迁移实践。
现在回想起来,当初的这个决定无疑是非常正确的了。不过再想想,如果当时看到 Kubernetes 的变化,我们没有主动思考,等到现在 Kubernetes 宣布不再支持 Dockershim 才去做应对,结果又会怎样呢?
这个问题,我觉得用数字来说话更直观。刚才提到当时迁移的时候,有 2 万台物理机节点以及几十万个容器。但如果等到现在才迁移,我们需要面对的就是 6 万台物理机和上百万的容器了。
你看,无论是写专栏也好,还是我们实际工作也好,呆在舒适区里,短期成本看着挺小,不需要你大动干戈,消耗脑细胞和精力。但是,当你习惯了这种思考的惰性,就会变成温水煮青蛙而不自知,等到外部条件发生变化时会很被动。
最后的彩蛋
前面我们聊了很多突破舒适区的事儿,不知道你有没有被触动呢?
其实学习也好,工作也罢,就是要有一种突破意识,走出舒适区,才能“开疆拓土”。那为了让你我都知行合一,我还要给你聊聊后面的专题加餐安排。
在开篇词我也提到了这个安排。虽然这一讲是我们课程的结束语,但我们课程的内容并没有结束。在这个专题里,我选择了一个真实案例。那这个案例我是怎么选的呢?
其实这是 2020 年初,我们在生产环境里遇到的一个真实的容器网络问题。我觉得这是一个很好的调试案例,它的好就在于可以用到 Linux 内核的最主要的几个调试工具,包括 perf,ftrace 和 ebpf。我们逐个使用这些工具,就可以层层递进地揭开问题的本质。
通过这个案例的学习,我会带你掌握每种工具的特性。这样你在理解了容器基本原理的基础上,就能利用这些好的工具系统化地分析生产环境中碰到的容器问题了,就像我们开篇中说的那样——变黑盒为白盒。
写完结束语之后,我会认真为你准备这个专题加餐。而这一个月的时间,你还可以继续消化理解课程主体部分的内容,打牢基础,这样对你学习后面的专题加餐也有很大帮助。
最后的最后,我想和你说的是,希望你我都能主动思考,不断突破自己,走出舒适区,一起共勉吧!
这里我为你准备了一份毕业问卷,题目不多,希望你可以花两分钟填一下。也十分期待能听到你的声音,说说你对这门课程的想法和建议。